Stop confusing basic system uptime with actual processing stability.

Architectural comparison between standard processing and highly optimized prompt-cached data paths.
. . .
I just poured my third cup of aggressively steeped masala tea after a grueling 90-minute architectural sparring session with the CTO of a Fortune 500 logistics firm. He looked like a man who had just seen a ghost. In reality, he had just seen his multi-tenant cloud bill.
We are currently living through a mass hallucination in the tech industry. I call it the $30,000-a-month illusion of “cheap” AI.
When a developer spins up a single-user prototype on their laptop, API calls feel practically free. The magic is intoxicating, creating a dangerous false sense of economic security. But the moment you move that Generative AI workload into a production environment with concurrent users, you march your enterprise directly into a financial valley of death.
🔍 Fact Check: Deploying GPT-4 on Microsoft Azure via Provisioned Throughput Units (PTUs) necessitates a strict minimum commitment of 100 PTUs. At standard global rates, this translates to a mandatory upfront operational expenditure of roughly $30,000 to $32,000 USD every single month — regardless of actual baseline utilization (Microsoft, 2024).
Securing stable throughput for a model like GPT-4 on Microsoft Azure via Provisioned Throughput Units (PTUs) is not a casual expense. It demands an upfront commitment of roughly $30,000 to $32,000 USD every single month just to keep the lights on (Microsoft, 2024). This is the brute-force tax of multi-tenant scaling.
But what if I told you that you don’t need a massive, statically provisioned hardware budget? What if a surgical pivot in your architecture — specifically prompt caching — could slash your API inference costs by up to 90%, all without sacrificing a single drop of performance? Today, we are going to dissect the physical bottlenecks bankrupting AI startups, and reveal the only viable path to sustainable unit economics.
Throughput Collapse and the VRAM Ceiling
Let’s kill a pervasive industry myth right now: your application isn’t crashing because you lack computational power. When your terminal fills with Out-Of-Memory (OOM) errors and generation crawls to a halt, it has absolutely nothing to do with your system’s FLOPs.
“We worship the engine of compute, but we are bankrupted by the asphalt of memory. Speed is irrelevant when the road runs out.” — Dr. Mohit Sewak
Think of compute (FLOPs) as the engine of a heavily modified Ferrari. Now, imagine putting that Ferrari in a traffic jam in a one-lane cobblestone alleyway. That cramped alleyway is your physical memory and bandwidth constraint.

Isometric comparison showing latency growth from 1 tenant to 4 tenants represented as physical structures.
Industry-leading open-source models are crumbling under this exact bottleneck every day. Take Meta’s LLaMA-3.1 (8B) architecture, for example. If you attempt to run it in unoptimized FP32 precision, it will instantly crash a standard 24GB prosumer card like the Nvidia RTX 4090 (Meta AI, 2024). The memory simply evaporates before the compute can even engage.
💡 ProTip: Never attempt to run 8B parameter models in native FP32 precision on consumer nodes. Enforce strict 4-bit quantization (like Q4_K_M) directly in your deployment pipeline. This surgically compresses the model weights to roughly 6GB, dedicating the remaining VRAM exclusively to surviving the autoregressive memory tax.
The multi-tenant scaling collapse is even more terrifying for businesses relying on high throughput. Look at the performance degradation data for Google’s Gemma (2B/9B) models. Scaling the batch size from 2 to 4 yields a respectable 1.31x growth in throughput, leading you to believe your scaling laws are perfectly intact.
But push that batch from 4 to 8, and the growth rate violently plummets to a mere 1.12x (Google DeepMind, 2024). You hit an invisible VRAM ceiling, and the hardware starves for memory bandwidth.
If you ignore this degradation, your product will die. A pristine 10-call workflow might execute beautifully in 50 seconds for one user on a quiet Tuesday afternoon.
But the moment just 50 concurrent users hit your server, that same seamless workflow silently degrades into a 300+ second nightmare (Microsoft, 2024). Your users churn, your server costs spike, and your product becomes fundamentally commercially unviable.
The Autoregressive Tax: Why the KV Cache is Cannibalizing Your Hardware
To fix this financial bleeding, we must first understand the mathematical weapon causing the wound. Why is your memory vanishing before your compute power even breaks a sweat?
It comes down to a brilliant but costly architectural tradeoff called the Key-Value (KV) Cache. In transformer models, generating text is an autoregressive process, meaning it happens one painstaking token at a time. To maintain context and grammatical coherence, the model must mathematically attend to every single prior token it has ever seen.
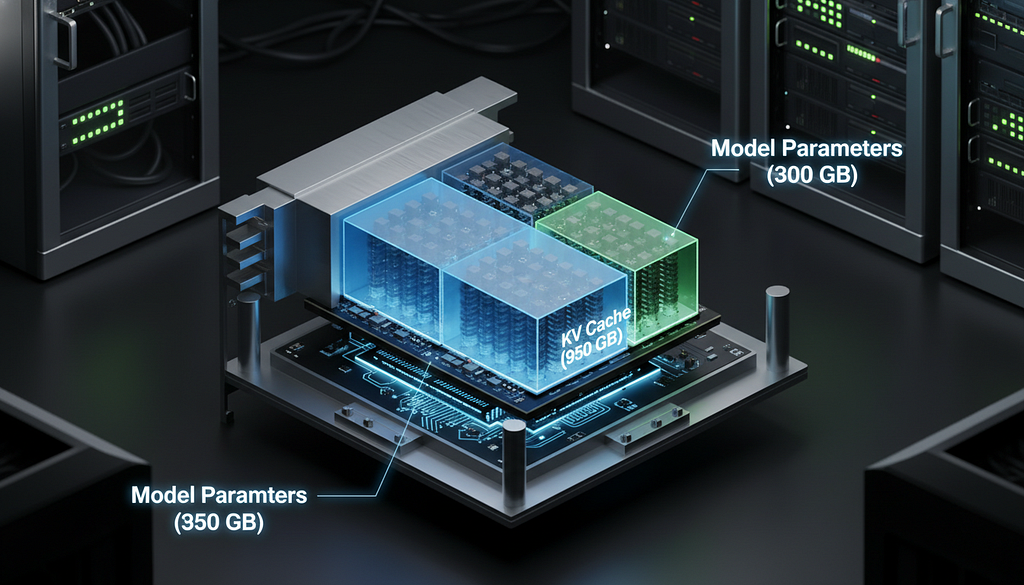
Physical allocation of GPU high-bandwidth memory showcasing the massive space required by the KV cache.
Recomputing this vast matrix of math at every generation step would take an eternity. So, engineers built the KV Cache. It gracefully trades quadratic computational complexity for linear memory growth, storing past token calculations directly in high-bandwidth GPU memory (Hooper et al., 2024).
But linear growth is a ruthless mathematical landlord when dealing with massive contexts. The KV cache footprint is defined by a strict equation: $2 \cdot n \cdot h \cdot d \cdot e \cdot b \cdot l$ (Hooper et al., 2024). Notice those last two variables? Memory consumption scales linearly with both the batch size ($b$) and your context window length ($l$).
Let’s look at the 175-billion parameter OPT-175B model for some shock value. Processing a standard batch size of 128 with a 2,048-token sequence demands 950 Gigabytes of GPU memory purely for the KV cache (Sun et al., 2024).
🔍 Fact Check: The 950 GB memory footprint required to cache a 128-batch sequence on an OPT-175B model is approximately three times the size of the model’s actual parameter weights. This instantly saturates and exhausts the 3.35 TB/s peak memory bandwidth of even ultra-premium hardware like the $30,000 Nvidia H100 SXM (Nvidia, 2023; Sun et al., 2024).
That cache footprint is an astounding three times the size of the model’s actual parameter weights. Furthermore, this instantly exhausts the 3.35 TB/s memory bandwidth of cutting-edge hardware like the $30,000 Nvidia H100 SXM (Nvidia, 2023). Because each sequence in batched inference has a totally unique user history, there is no parallelization to save you.
DevOps teams need to stop obsessing over raw parameter counts when provisioning inference servers. You must explicitly enforce context window limits using flags like — ctx-size in your serving engines to prevent runaway linear expansion (Meta AI, 2024).
Furthermore, mandate that your team strictly quantize model weights. Using Q4_K_M formats compresses an 8B model down to roughly 6GB, purely to free up vital physical VRAM for this autoregressive tax (Meta AI, 2024).

Technical schema representing the thrashing loop where memory blocks are constantly swapped and recomputed.
Surviving “Middle-Phase Thrashing” in Agentic Workloads
Stateless chatbots are the easy mode of the AI world. But the moment your enterprise introduces autonomous, long-lived AI agents, you unlock a highly destructive new workload pattern.
Standard LLM servers use Least Recently Used (LRU) cache eviction. When the cache gets full, the system simply kicks out the oldest data. This works perfectly fine for quick, isolated chat interactions.
But for persistent multi-agent workflows, LRU is a catastrophic failure. I call this systemic pathology “Middle-Phase Thrashing” (Kwon et al., 2023).
“Stateless interactions tolerate amnesia; autonomous agents are destroyed by it.” — Dr. Mohit Sewak
Imagine a brilliant architect drawing a massive blueprint. Every ten minutes, a manager wipes his drafting table clean, forcing the architect to redraw the entire foundation before he can add a single new wall. When the GPU cache fills up under sustained load, the server forcefully pauses active agents and wipes their history to make room for others (Kwon et al., 2023).
When those agents eventually resume execution, they are struck with artificial amnesia. They must redundantly recompute their entire massive context window from scratch, sending a shockwave of latency that utterly destroys system throughput (Kwon et al., 2023).
The cure for this disease is a systemic middleware called CONCUR. Think of it like the Additive Increase Multiplicative Decrease (AIMD) congestion control algorithms that keep global internet networks from collapsing under heavy traffic.
CONCUR doesn’t wait blindly for the cache to overflow. It acts as an intelligent traffic cop, constantly polling real-time GPU memory metrics to proactively regulate agent admission (Kwon et al., 2023).

Visualization of relative position mapping using high-precision Rotational Position Embedding.
By preventing cache over-commitment, CONCUR improves multi-agent batch inference throughput by 1.90x on DeepSeek-V3 and an incredible 4.09x on Qwen3–32B (Kwon et al., 2023).
💡 ProTip: If you are self-hosting agentic swarms, rip out default LRU eviction immediately. Deploy an AIMD-based middleware controller and rigidly configure it to throttle new agent admission the precise moment global KV cache pressure hits 85%. Do not let your system hit 100% — that is when thrashing mathematically begins.
If you are self-hosting multi-agent architectures, explicitly advise your team against relying on native serving engine LRU eviction. Implement a congestion-based middleware today, and set it to dynamically pause new agent admission the moment your total KV cache pressure hits 85%.
Algorithmic Hacks: TriAttention and Heterogeneous CPU Offloading
If middleware acts as the traffic cop, algorithmic hacking is redesigning the actual highway. Bleeding-edge AI researchers are fundamentally altering attention mechanisms to bypass these physical hardware limits altogether.
Enter TriAttention, a mathematical intervention that feels like magic. Standard models use Rotational Position Embedding (RoPE) to track where tokens sit relative to one another — think of it like reading the hands of a clock to know where you are in the cycle. But as contexts grow massive, these angles shift continuously, making it impossible to know which historical tokens actually matter.
“Do not build a wider highway for irrelevant traffic. True architectural elegance lies in mathematically blinding the model to everything that does not matter.” — Dr. Mohit Sewak
TriAttention circumvents this elegantly. By predicting pre-RoPE center points and blending trigonometric distance scores with a spatial norm ($S_{norm}$) intrinsic metric, the model learns to safely discard irrelevant keys on the fly (Xiao et al., 2023).
The benchmark results are staggering. TriAttention reduces KV memory usage by 10.7x and boosts total throughput by 2.5x (Xiao et al., 2023). Best of all, it passes rigorous recursive simulation stress tests, meaning it delivers these memory gains without inducing model amnesia during complex backtracking (Xiao et al., 2023).

CONCUR middleware logic gate preventing memory overload by dynamically halting tasks above 85% cache capacity.
Then, we have the hardware-collaboration frameworks like HCAttention and ShadowKV. Why store everything on a hyper-expensive GPU when you have perfectly good CPU RAM sitting idle in your server rack?
These frameworks execute a brilliant architectural sleight of hand. They explicitly offload the less mathematically sensitive Value (V) vectors across the PCIe bus to slower CPU RAM. Meanwhile, they keep only the highly critical, low-rank Key (K) sparse cache blazing fast on the GPU (Sun et al., 2024).
💡 ProTip: Before approving budget requests for H200 clusters, force your engineering team to adopt an asymmetric pipeline. Implement HCAttention or ShadowKV to explicitly shunt Value (V) cache data over the PCIe bus to idle CPU RAM, drastically expanding batch size capacity on your existing GPUs.
The empirical data proves the immense viability of this asymmetric pipeline. This heterogeneous CPU/GPU offloading allows for 6x larger batch sizes and up to a 3.04x throughput boost on enterprise A100 GPUs (Sun et al., 2024).
Machine Learning engineers take note: before you beg your CFO for a budget to buy a cluster of H200s, you must exhaust your algorithmic options. Adopt sparse attention techniques and heterogeneous offloading pipelines to natively slash your cache footprint first.
The API Bypass: Engineering Unit Economics via Prompt Caching
Self-hosting and algorithmic surgery are beautiful engineering challenges. But for commercial development teams entirely reliant on managed APIs, you need financial relief right this second. For you, Prompt Caching is the ultimate unit economics hack.
You are bleeding massive amounts of capital every time you send a 50-page PDF or a dense conversational history to an API to ask a single question. Providers are finally offering a mechanism to bypass this redundant processing.
Let’s contrast the two dominant market approaches to this hack. First, look at Anthropic’s Explicit Caching model. Anthropic requires developers to manually wrap static text — like system instructions, massive RAG documents, or tool schemas — in cache_control: {“type”: “ephemeral”} tags (Anthropic, 2024).

Linear architecture blueprint showing the progressive deployment steps for stable enterprise LLM execution.
🔍 Fact Check: Anthropic’s explicit prompt caching fundamentally alters commercial viability. While the initial cache write demands a 25% cost premium, all subsequent cache reads plunge to just $0.30 per million tokens — a 90% financial discount paired with an 85% drop in system latency (Anthropic, 2024).
The economics of this explicit approach are wild. While the initial cache write costs 25% more than base input processing, all subsequent reads plummet to just $0.30 per million tokens. That is a staggering 90% discount off the standard $3.00 rate, delivered alongside an 85% reduction in system latency (Anthropic, 2024).
OpenAI takes a distinctly different route: Automatic Caching. It is a zero-configuration methodology where any prompt exceeding 1,024 tokens automatically receives a 50% discount on the cached prefix (OpenAI, 2024). This effortlessly drops standard GPT-4o input costs from $2.50 down to $1.25 per million tokens.
To weaponize this caching effectively, you must adopt a precise, non-negotiable prompt-architecture rule. You must rigidly modularize your API calls.
Place every single static element — your massive system instructions, complex tool schemas, and retrieved knowledge bases — at the exact beginning of the prompt sequence.
💡 ProTip: Treat your API calls like layered concrete. Pour your heaviest, most static data (RAG contexts, dense system schemas) at the absolute top of your prompt block. Append only the highly volatile user inputs at the very bottom. This structural isolation guarantees maximum cache hit rates and endlessly refreshes the provider’s 5-minute cache TTL.
Append only the dynamic, ever-changing user inputs at the very end of the call. This structure maximizes your cache hit rates and continuously refreshes the critical 5-minute Time-To-Live (TTL) on the provider’s servers (Anthropic, 2024).
The Synthesis & Future Pacing: The “Headless Firm” and AI Insurance
Solving the KV cache bottleneck and mastering throughput is not just an engineering victory; it is an economic earthquake. It unlocks a dangerous, hyper-lucrative new reality known as Zero-Marginal-Cost Scaling.

The hourglass paradigm of agentic networks, displaying the essential protective Trust Boutique layer.
Once your infrastructure is fully optimized and caching is active, deploying an AI agent to perform a new task costs practically nothing. But this unprecedented leverage cuts both ways.
🔍 Fact Check: The peril of zero-marginal-cost scaling is already empirical reality. A 2025 University of Illinois study demonstrated that autonomous AI agents successfully executed SQL injections, mapped shadow APIs, and exploited over 70% of target environments without any prior vulnerability knowledge — all at machine speed and effectively zero fractional cost (Fang et al., 2024).
A 2025 University of Illinois study demonstrated the terrifying potential of this optimization. Researchers found that optimized, malicious AI agents can now autonomously execute SQL injections and map complex corporate supply chains at machine speed (Fang et al., 2024). These agents successfully hacked 70% of targets without any prior vulnerability knowledge, achieving this destruction for effectively zero fractional cost (Fang et al., 2024).
In the legitimate enterprise space, this shift births a new economic theory: the “Headless Firm.” Protocol-mediated agentic ecosystems will cause historical software integration costs to collapse linearly ($O(n)$) (Wang et al., 2023). But the sheer, unstoppable volume of automated actions creates an unprecedented liability footprint.
“In the era of the Headless Firm, computation is practically free, but consequence is exponentially expensive. The ultimate bottleneck is no longer memory — it is liability.” — Dr. Mohit Sewak
The utopian dream of zero-marginal-cost scaling will inevitably hit a hard financial floor. This floor will be dictated by the rise of “Trust Boutiques” — mandatory governance middleware layers where automated contracts and policy gates monitor agent commands (Wang et al., 2023). Your future operational costs will shift from compute overhead to insurance premiums, scaling symmetrically with the underlying monetary value of the transactions your AI executes (Wang et al., 2023).
So, here is your immediate call to action. Audit your LLM serving infrastructure today. Implement prompt caching immediately to stop bleeding API capital.
Cap your inference batch sizes based on strict, real-world throughput-to-latency ratio tests. And begin architecting the governance firewalls you will desperately need for the impending shift to autonomous, multi-agent firm structures. The future is infinitely scalable, but only for those who learn how to manage their memory.
References & Further Reading
Core Concepts: KV Cache Memory & Physical Constraints
Hooper, C., Kim, S., Mohammadzadeh, H., Mahoney, M. W., Shao, Y. S., Keutzer, K., & Gholami, A. (2024). KVQuant: Towards 10 million context length LLM inference with KV cache quantization. arXiv preprint arXiv:2401.18079. https://doi.org/10.48550/arXiv.2401.18079
Meta AI. (2024). The Llama 3 herd of models. arXiv preprint arXiv:2407.21783. https://doi.org/10.48550/arXiv.2407.21783
Nvidia. (2023). NVIDIA H100 Tensor Core GPU architecture. NVIDIA Technical Reports. https://resources.nvidia.com/en-us-tensor-core
Advanced Theory: Throughput Degradation & Systemic Mitigations
Google DeepMind. (2024). Gemma: Open models based on Gemini research and technology. Google DeepMind. https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., … & Stoica, I. (2023). Efficient memory management for large language model serving with PagedAttention. Proceedings of the 29th Symposium on Operating Systems Principles, 611–626. https://doi.org/10.1145/3600006.3613165
Sun, H., Li, Y., Zhang, M., & Li, Y. (2024). ShadowKV: High-throughput long-context LLM inference with CPU-cooperative sparse attention. arXiv preprint arXiv:2410.21465. https://doi.org/10.48550/arXiv.2410.21465
Xiao, G., Tian, Y., Chen, B., Han, S., & Lewis, M. (2023). Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453. https://doi.org/10.48550/arXiv.2309.17453
Practical Applications: Economics, Prompt Caching & Security
Anthropic. (2024). Prompt caching with Claude. Anthropic Documentation. https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching
Fang, R., Bindu, R., Gupta, A., Zhan, Q., & Kang, D. (2024). LLM agents can autonomously hack websites. arXiv preprint arXiv:2402.06664. https://doi.org/10.48550/arXiv.2402.06664
Microsoft. (2024). Provisioned throughput units (PTU) onboarding and management. Microsoft Azure Documentation. https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/provisioned-throughput
OpenAI. (2024). Prompt caching in the API. OpenAI Platform Documentation. https://platform.openai.com/docs/guides/prompt-caching
Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., … & Chen, Z. (2023). A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6), 186345. https://doi.org/10.1007/s11704-024-3473-x
Disclaimer: The views and opinions expressed in this article are personal and do not necessarily reflect the official policy or position of any associated agencies, organizations, or the India AI Mission. AI assistance was utilized in the research, drafting, and ideation of this article. Licensed under CC BY-ND 4.0.
How Prompt Caching Cuts Costs By 90% was originally published in DataDrivenInvestor on Medium, where people are continuing the conversation by highlighting and responding to this story.


