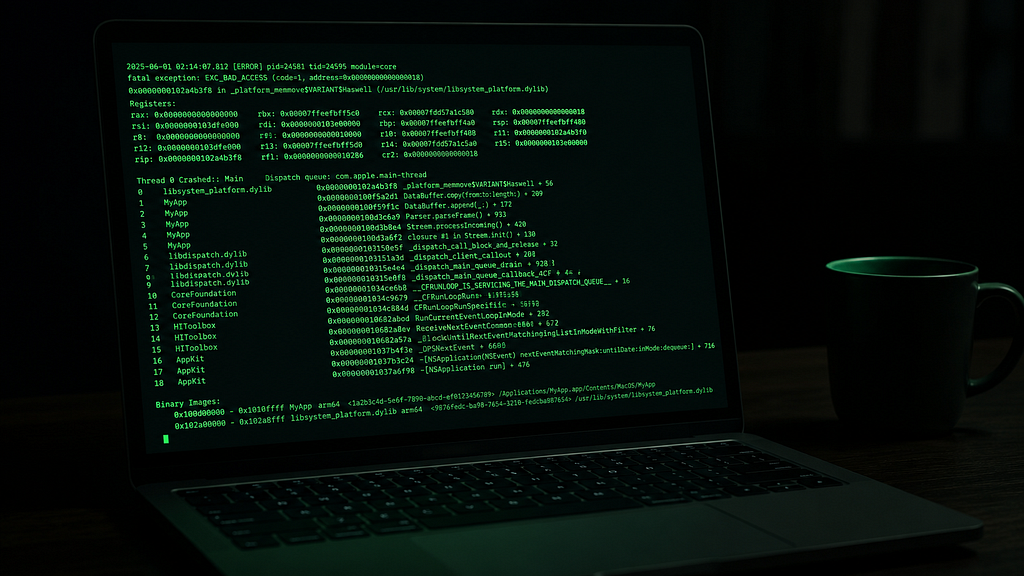
Last week, I added a fuzz test to a small Go parser.
I did not expect much. The function had been in production for six months. It had unit tests. Coverage was over 90%. Every test passed.
Four minutes and twenty-three seconds later, the fuzzer crashed it.
The failing input was not huge. It was not clever. It was just this:
"platform"
One missing separator. One panic. Six months in production.
Fuzzing Is Not Just Random Input
Most engineers think of fuzzing as a security tool. Something penetration testers run. Something you do when you are building a browser or a compiler.
That is too narrow a definition.
Go has had built-in fuzzing since Go 1.18. It ships with the standard toolchain. You do not need a third-party library, a security audit, or a dedicated fuzzing infrastructure. You need one function and one command.
What Go’s fuzzer does is generate inputs automatically, guided by code coverage. It keeps the inputs that reach new branches in your code and discards the ones that do not. This is not random noise. It is the fuzzer learning which inputs make your code take a new path.
I had used Go for years before fuzzing became part of my normal testing workflow.
The difference between fuzzing and unit testing is simple: unit tests check the paths you remembered. Fuzzing finds the paths you did not.
The Parser Looked Safe
The function was a simple parser. It read budget rules from a configuration string in the format team=limit — a team name and an integer limit, separated by an equals sign.
func ParseBudgetRule(rule string) (team string, limit int, err error) {
parts := strings.SplitN(rule, "=", 2)
team = strings.TrimSpace(parts[0])
limit, err = strconv.Atoi(strings.TrimSpace(parts[1]))
if err != nil {
return "", 0, fmt.Errorf("invalid limit in %q: %w", rule, err)
}
if limit <= 0 {
return "", 0, fmt.Errorf("limit must be positive, got %d", limit)
}
return team, limit, nil
}It had unit tests. They covered valid rules, non-numeric limits, negative limits, and whitespace around values. All passing. Coverage was 92%.
The function looked safe because everything I had tried was safe.
The Fuzz Test Was Small
Here is what I added:
func FuzzParseBudgetRule(f *testing.F) {
f.Add("platform=5000")
f.Add("infra=250")
f.Add("ops=1")
f.Fuzz(func(t *testing.T, rule string) {
team, limit, err := ParseBudgetRule(rule)
if err != nil {
return
}
if team == "" {
t.Errorf("ParseBudgetRule(%q) returned empty team with no error", rule)
}
if limit <= 0 {
t.Errorf("ParseBudgetRule(%q) returned non-positive limit %d with no error", rule, limit)
}
})
}The seed corpus gives the fuzzer valid examples to start from. The fuzz function checks invariants: if parsing succeeds, the team name should be non-empty and the limit should be positive.
I ran it with:
go test -fuzz=FuzzParseBudgetRule -fuzztime=5m
The Input That Broke It
Four minutes and twenty-three seconds in:
--- FAIL: FuzzParseBudgetRule (263.42s)
fuzzing process hung or terminated unexpectedly: exit status 2
Failing input written to testdata/fuzz/FuzzParseBudgetRule/6f1d4b2a
To re-run:
go test -run=FuzzParseBudgetRule/6f1d4b2a
The failing input:
"platform"
No equals sign. Just a word.
strings.SplitN("platform", "=", 2) returns []string{"platform"}. One element, not two. So parts[1] does not exist.
Index out of range. Panic.
One important detail: the fuzzer automatically saved the failing input to testdata/fuzz/FuzzParseBudgetRule/. It becomes a permanent regression test. Every future go test run replays it without the -fuzz flag. You do not need to remember to add this case. The toolchain does it for you.
The assumption was reasonable. It was also wrong.
Why Unit Tests Missed It
My unit tests covered:
- "platform=5000" — valid input
- "platform=abc" — invalid limit
- "platform=-1" — negative limit
- " platform = 5000 " — whitespace trimming
Every test I wrote assumed the input contained an equals sign. That was the format. It was documented. The caller was supposed to provide it.
The fuzzer does not read documentation. It does not know what the format is “supposed to be.” It tries "platform" because it is a shorter mutation of "platform=5000", and shorter inputs often reach error paths that longer inputs skip past.
A useful mental model: your unit tests check the roads you built. Fuzzing tries to find roads you did not know existed, and drives a car down them at speed.
The bug was not in the logic of the function. The bug was in the assumption that the input would always be well-formed.
The Fix
func ParseBudgetRule(rule string) (team string, limit int, err error) {
parts := strings.SplitN(rule, "=", 2)
if len(parts) != 2 {
return "", 0, fmt.Errorf("invalid rule %q: expected format team=limit", rule)
}
team = strings.TrimSpace(parts[0])
if team == "" {
return "", 0, fmt.Errorf("team cannot be empty")
}
limit, err = strconv.Atoi(strings.TrimSpace(parts[1]))
if err != nil {
return "", 0, fmt.Errorf("invalid limit in %q: %w", rule, err)
}
if limit <= 0 {
return "", 0, fmt.Errorf("limit must be positive, got %d", limit)
}
return team, limit, nil
}Three new checks: the separator must be present, the team name cannot be empty, and the limit must be positive. The fuzz invariants now match the implementation.
After fixing the function, I re-ran the fuzzer for another five minutes. It did not find another crash in that run.
This is the kind of bug that feels obvious only after a tool finds it.
How I Use Fuzzing Now
After this, I stopped treating fuzzing as a security-only tool. For Go services, it is just another parser test.
Fuzz any function that:
- Parses external input — config strings, API payloads, file formats
- Validates input before storing or acting on it
- Splits or transforms strings based on an assumed structure
- Converts between types where the input shape is not guaranteed
The setup:
- Create fuzz_test.go alongside your existing test file
- Name the function FuzzXxx
- Seed it with 3–5 representative valid inputs
- Write invariants — what must be true when the function returns without an error
- Run go test -fuzz=FuzzXxx -fuzztime=5m locally
- Commit the saved test cases from testdata/fuzz/ into version control
In CI: run go test ./..., not active fuzzing. Active fuzzing is exploratory and belongs in development. CI replays the saved failing cases automatically.
# Local exploration
go test -fuzz=FuzzParseBudgetRule -fuzztime=5m
# CI: replay all saved failing cases automatically
go test ./...
The saved test cases in testdata/ stay in version control and protect every future change to that function.
What Go’s Native Fuzzer Will Not Catch
Go’s built-in fuzzer is good at finding inputs that crash your code or violate the invariants you define. It will not catch everything.
Trail of Bits has been working on gosentry, a security-focused fork of the Go toolchain that adds checks Go’s native fuzzer does not provide natively: integer overflow detection, race detection, goroutine leak detection, and timeout handling. If you are building security-sensitive services, it is worth reviewing what gosentry adds on top of the standard toolchain.
Go’s native fuzzer also will not help with:
- Logic errors that do not panic or fail invariants — the output can be wrong and the fuzzer will not know
- Stateful bugs that require a sequence of operations
- General performance regressions that need benchmarks or profiling
For those, you still need traditional unit tests, integration tests, and property-based testing tools like rapid. Fuzzing complements your test suite. It does not replace it.
The Rule I Use Now
Fuzzing does not care what you expected. It explores what is actually possible.
The bug I found was not exotic. It was the simplest possible malformed input: a string with no separator. The kind of input that only appears in a config file because someone made a typo, or because upstream sanitization had a gap.
Unit tests would have caught this if I had thought to write it. I did not think to write it. That is the point.
Most functions that parse or validate external input are worth fuzzing. Not because fuzzing is magic. Because input assumptions are where boring production bugs hide.
Go has had built-in fuzzing since Go 1.18. The setup is small. The command is simple. The payoff can be immediate.
A fuzzer found my bug in 4 minutes and 23 seconds.
Your parsers, validators, and input processors probably have their own version of this bug. The only reason not to look is not knowing the tool exists.
Now you do.
What is the weirdest input that ever broke your production code?
If this was useful, give it a clap — it helps other engineers find it. Follow me here on Medium and subscribe for more stories like this. I write about Go production patterns, testing, and the small engineering decisions that prevent large incidents.
Vinamra Yadav is a software engineer working on distributed systems and Go services. He writes about backend engineering, testing strategies, and building production-grade systems.
I Ran Go Fuzzing for Five Minutes. It Found a Production Bug was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.