Http ConnectionPooling TTL Trap: Intermitten Api Failures
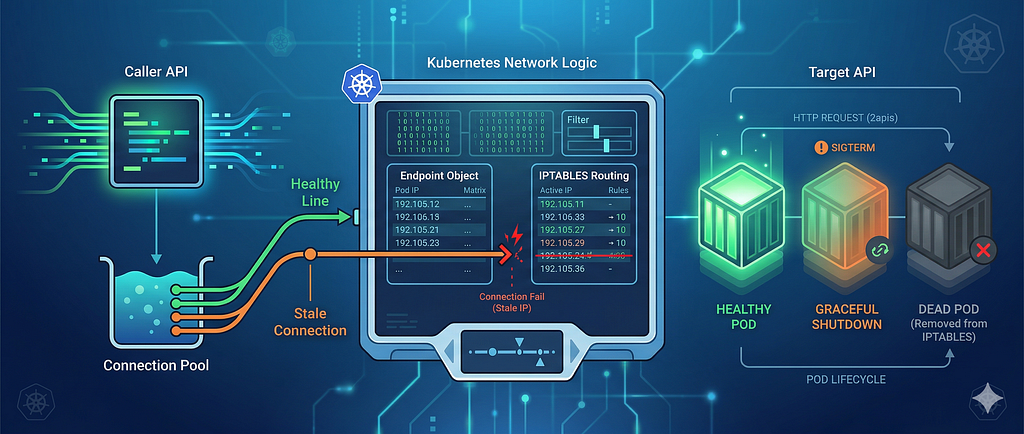
Problem Definition
We had been experiencing an unique kind of problem between two API’s: The one performing API call was throwing NoHttpResponseException.
Interestingly: As I trigger the exact same api call right after, it succeeded: Meaning, somehow; a one time error was happening periodically which is not related to the application level but more like infrastructure level.
Root Cause Detection
The exception itself also strictly indicates that the request is not handled by any http server, in other terms the underlying TCP connection was already closed!
As I dug deeper: I have noticed a common pattern between the target api’s pod lifecycle and the exception’s occurring times.
This is a high-scale api handling millions of requests and has ~15 deployments accross two kubernetes clusters. As I query the pod’s lifecycle on NewRelic, I realized a pattern: every single exception is occured at times where at least one pod of target-api was dying a new one was being created.
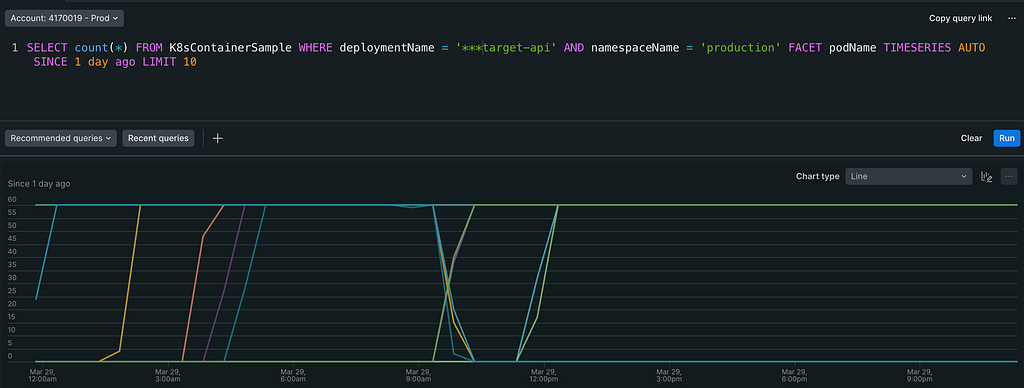
This immediately made me think of that there was a problem with the graceful shutdown of the target-api. So I checked the pod’s logs and it’s lifecycle more closely but I’ve seen nothing suspicious. The logs were obvious:
1- Pod receives SIGTERM, sets Readiness=DOWN.
2- It sleeps for configured sleep period (15s).
3- As the sleep period is over, it waits for active requests to complete.
4- It starts closing Tomcat (Spring’s Http Server), Kafka Producer etc.
{"message":"Health check is entering unhealthy state sleeping for 15000 ms","service_name":"target-api","thread.name":"SpringApplicationShutdownHook","timestamp":"2026-03-28T15:39:49.546254912Z", "level":"INFO"}
{"message":"Midas health check sleep is done","service_name":"target-api","thread.name":"SpringApplicationShutdownHook","timestamp":"2026-03-28T15:40:04.546565862Z", "level":"INFO"}
{"message":"Commencing graceful shutdown. Waiting for active requests to complete","service_name":"target-api","thread.name":"SpringApplicationShutdownHook","timestamp":"2026-03-28T15:40:04.548526775Z", "level":"INFO"}
{"message":"Graceful shutdown complete","service_name":"target-api","thread.name":"tomcat-shutdown","timestamp":"2026-03-28T15:40:04.551124375Z", "level":"INFO"}So everything regarding to the target-api’s graceful shutdown seemed complete. This directed me to check the configurations of the caller-api.
More Root Cause Detection!
Even though there were multiple APIs that were calling the target-api only the caller-api was experiencing the error. And only it had connection-pooling enabled with below configurations that none of the other APIs had:
httpclient:
hc5:
enabled: true
max-connections: 50
max-connections-per-route: 25
time-to-live: 30
time-to-live-unit: SECONDS
Somehow; this had to be the cause of the problem. I first thought it was somehow resolving the “dying” pod’s IP because of the connection-pooling since:
If there would be no connection-pooling:
❗ Every single HTTP call would resolve the “living” pod’s IP dynamically as the request is made. This introduces an overhead per HTTP request but it’s the safe and default way mostly.
But what connection-pooling does:
❗ It resolves the target pod’s IP once the connection is established, and holds it until either the first request over that TCP connection fails, or the configured time-to-live period is over. It has no capability of figuring-out if the IP it is holding statically is still there or not!
In order to better understand the “IP lifecycle” I drawed below diagram by inspecting kubernetes events, application logs etc:
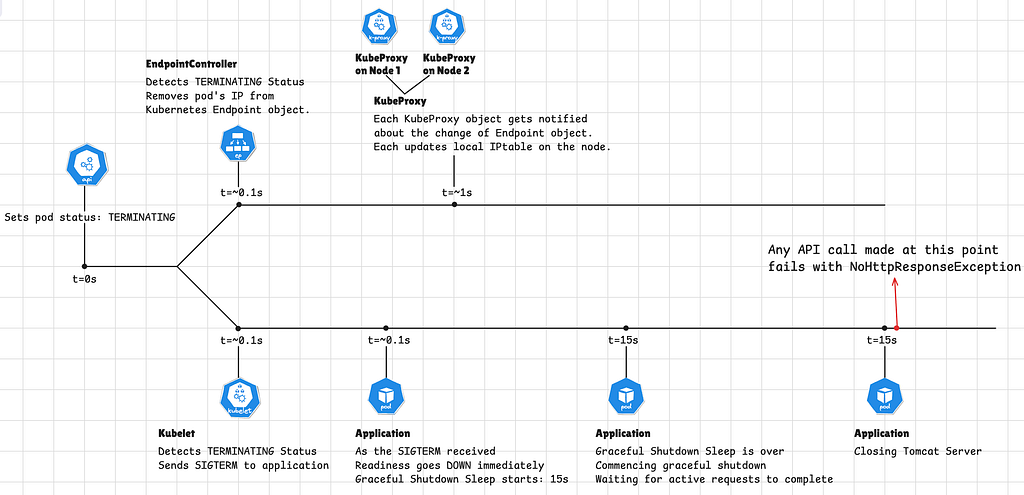
Note: The applications Readiness state switches runs completely async from the kubernetes state switches, for this reason they are shown in the separate timelines.
The diagram clearly shows: It is not possible for a new connection to be established after t=~1s since the “dying” pod’s IP gets removed from IP tables at that time.
But what if the connection is established right before the pod enters TERMINATING state, and connection is kept alive beyond over the termination period?
The Solution
So the problem was about the configuration: If any connection established while the pod was healthy, it will be kept until the pod dies, since 30 seconds of time-to-live is much larger than overall shutdown process of 15 seconds. The first request after the Tomcat is shutdown was immediately failing.
The solution was obvious: Decreasing the time-to-live of the connections in the connection-pool to around 15 seconds.
httpclient:
hc5:
enabled: true
max-connections: 50
max-connections-per-route: 25
time-to-live: 10
time-to-live-unit: SECONDS
Even if theoretically it is possible to set time-to-live to 15 seconds, to exactly match the time period of shutdown process (15 seconds + microseconds), it shouldn’t be done practically.
As I observed that in production environment; it takes up to 1 to 5 seconds for “dying” pod’s IP to get removed from IP tables. So as a safe configuration I decreased the TTL to 10 seconds, and as I deploy toproduction, the Sentry errors of NoHttpResponseException stopped being received :).
Http Connection Pool TTL Trap: Debugging Intermittent API Failures was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.




