Ontology isn’t a database. It’s the layer that tells AI agents what to do, why, and what happens next.
The Problem Multi-Agent Didn’t Solve
In my previous articles, I built a 6-agent MCP system on GCP — Email, CRM, Calendar, CS, Helpdesk, and Report agents. I tested three orchestrators (Claude, GPT-4o, Llama 3.1) and got 100% success. Then I connected it to web and mobile with Google ADK. Zero server changes.
The architecture worked. But it had a blind spot.
In the multi-agent system, the orchestrator AI picks which agent to call. The agent AI picks which tool to use. That’s two AI decisions per request — both made from scratch every time. The AI doesn’t know that this customer is a VIP. It doesn’t know that complaints should go to CS Agent. It doesn’t know that closing a ticket should trigger a follow-up survey. Every request starts from zero context.
For simple tasks — “check my email” — this is fine. For real business processes — lead scoring, SLA monitoring, cross-department workflows — it’s not enough. The AI needs business knowledge injected before it decides, not after.
What Palantir Got Right
Palantir’s Foundry platform is built on one core idea: ontology as the operational layer for enterprise AI. They define object types (customers, orders, tickets), relationships as link types (customer generates leads, leads convert to opportunities), and action types with governance rules — all in a structured ontology. LLMs and AI agents query and reason over this ontology before making decisions. All writes must go through action types, which enforce validation, approvals, and audit trails — preventing uncontrolled changes to data.
The insight is simple but powerful: the ontology orchestrates the agents, not the other way around.
I wanted to bring this idea into my existing multi-agent system — without Palantir’s price tag. So I’m building OOSDK: Open Ontology SDK.
Three Orchestration Approaches — A Comparison
Before diving into the design, let me place ontology in context. Over the past experiments, I’ve tried three fundamentally different approaches to AI orchestration:
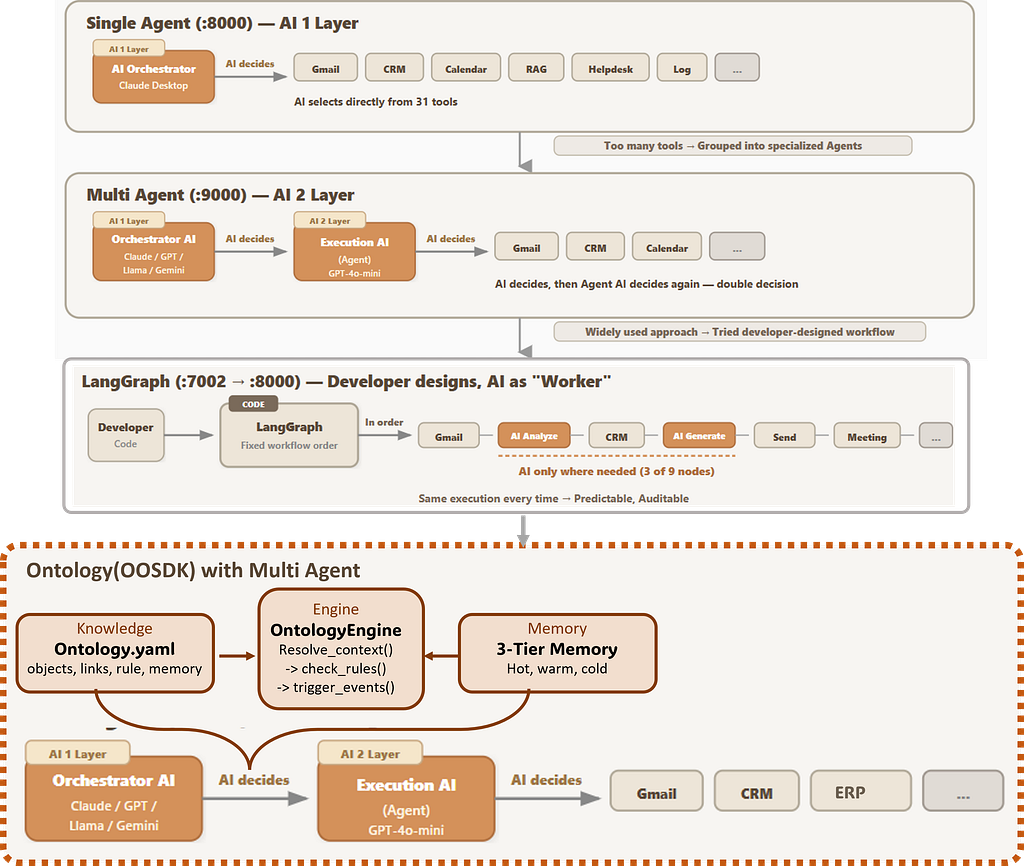
Autonomous : AI decides autonomously. Claude, Cursor+GPT, Cursor+Llama, ADK — all acting as managers who both decide and execute. Flexible, great for PoC. But no guardrails.
Developer Manual : LangGraph, where the developer designs the workflow in code. AI only executes within fixed nodes. Predictable and auditable — ideal for regulated environments. But every process change means a code change.
Ontology (— this article): Rules defined in a knowledge graph, not in code. AI interprets and executes based on declared business logic. Non-developers can modify the YAML to change how the system behaves. Flexibility of autonomous, auditability of manual — best for business agility.
Each approach fits different needs. The key differentiator with ontology: change the YAML, change the business process — no code deployment required.
OOSDK: Three Components, One Engine
To make ontology work in practice, I need to build one thing: OOSDK (Open Ontology SDK). It has three components:
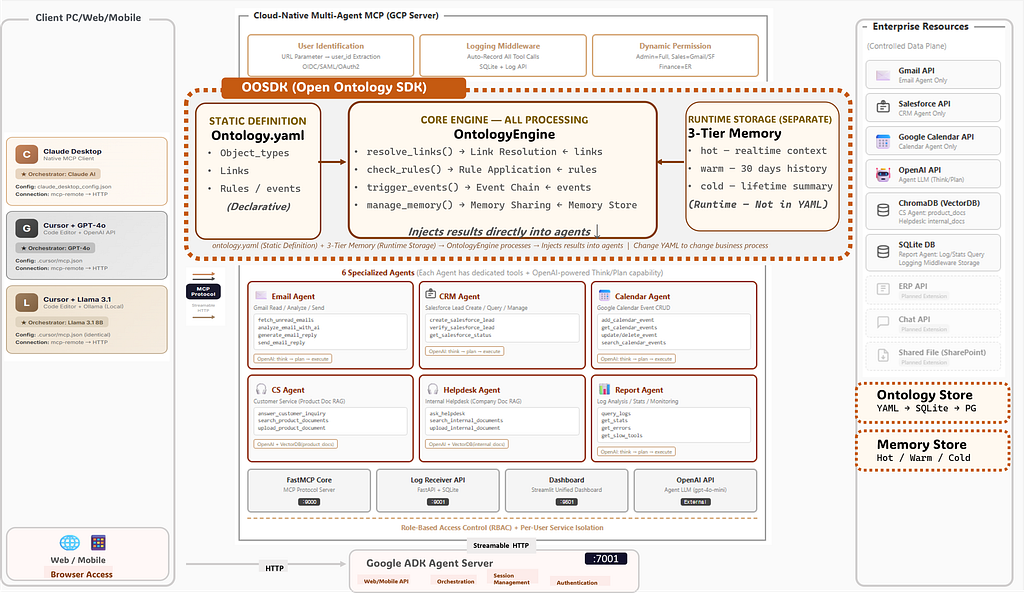
1. ontology.yaml — The Static Definition
This is where you declare your business world. Three sections — that’s it:
object_types:
Customer:
fields: [name, email, tier]
source: salesforce
Lead:
fields: [email, status, score]
source: crm
Ticket:
fields: [subject, priority]
source: helpdesk
links:
Customer → Lead:
type: generates
Lead → Opportunity:
type: converts_to
rules:
auto_approve:
if: lead.score > 80
then: approve
escalate_vip:
if: customer.tier == "VIP"
then: priority = "high"
route_support:
if: email.type == "complaint"
then: agent = "cs_agent"
No Python. No deployment. A business analyst can read this and say “change VIP threshold from tier to spend_amount > 10000” — and the system behaves differently at the next request.
2. OntologyEngine — The Core Processor
The engine reads ontology.yaml and does four things:
class OntologyEngine:
def __init__(self, yaml_path):
self.ontology = load_yaml(yaml_path)
self.memory = ThreeTierMemory()
def resolve_context(self, trigger: dict):
"""Before AI decides — inject business context"""
# Step 1: Resolve relationships
links = self.resolve_links(trigger)
# Step 2: Apply business rules
rules = self.check_rules(trigger, links)
# Step 3: Load relevant memory
memory = self.manage_memory(trigger)
# Inject into agent context
return {
"links": links,
"applied_rules": rules,
"memory": memory,
"suggested_agent": rules.get("route_to")
}
The four core methods:
resolve_links() — Given a customer email, find all related objects: their leads, opportunities, tickets, past interactions. The AI gets this context before deciding anything.
check_rules() — Apply business rules. Score above 80? Auto-approve. VIP customer? Escalate priority. Complaint email? Route to CS Agent. These aren’t AI decisions — they’re business decisions, deterministic and auditable.
trigger_events() — After an action completes, fire downstream events. Close a ticket → send satisfaction survey + update lead status + schedule follow-up. One action, three consequences — all defined in YAML, not scattered across code.
manage_memory() — Read from and write to the 3-tier memory store, ensuring every agent call has the right context at the right granularity.
The engine injects results directly into agents. The orchestrator AI doesn’t guess which agent to call — it receives a pre-filtered, rule-applied context that narrows the decision space dramatically.
3. 3-Tier Memory — Runtime Context
Memory is separate from ontology.yaml because it’s runtime state, not static definition:
Hot — Real-time context. The current conversation, active session data. Cleared after each interaction.
Warm — Recent history. Last 30 days of interactions, tickets, emails. Retrieved when the engine resolves links for a known customer.
Cold — Lifetime summary. Aggregated customer profile, total spend, satisfaction trends. Compact enough that even with hundreds of thousands of customers, the AI context window stays manageable.
The key insight: even with massive data, the AI context is always bounded. Hot gives you now. Warm gives you recent. Cold gives you everything else — as a summary, not raw data. The engine decides which tier to pull from based on the ontology rules.
How It Changes the Agent Flow
Here’s the before and after:
# Before: Multi-Agent (AI decides everything from scratch)
request -> Orchestrator AI # picks agent
-> Execution AI # picks tool
-> Execute # done
# After: Ontology + Multi-Agent (AI decides WITH context)
request -> OntologyEngine
resolve_links() # find related objects
check_rules() # apply business rules
manage_memory() # load hot/warm/cold
-> Orchestrator AI # picks agent WITH context
-> Execution AI # picks tool
-> Execute
-> OntologyEngine
trigger_events() # fire downstream chains
Two critical additions: context injection before the decision, and event propagation after the execution. The AI doesn’t start from zero anymore — and actions don’t end in isolation.
The Roadmap: From Concepts to Business Scenarios
✅This article covers concepts and design — the “what” and “why” of ontology-driven orchestration. The implementation is next, across three business scenarios:
- ⬚ Business Case 1 — Customer Relationship Pipeline: Lead scoring, auto-routing, duplicate detection, SLA monitoring. SFDC-connected. The simplest ontology — 5–6 object types, linear relationships.
- ⬚ Business Case 2 — Customer 360° + Event Chain: Side-by-side demo: same customer email, responded to with and without ontology context. Plus the “1 action → 3 events” chain — close a ticket, and a survey, lead update, and follow-up all fire automatically. Memory 3-tier in action.
- ⬚ Business Case 3 — Order to Cash + Multi-Agent: The end-to-end process: Quote → Order → Delivery → Invoice → Payment. SFDC handles the sales side; Odoo ERP handles fulfillment and accounting. Ontology bridges the two systems — breaking down departmental silos with a unified knowledge graph. Multi-agent orchestration across domains.
Why This Matters
Most AI agent frameworks focus on the AI — making it smarter, faster, more capable. Ontology shifts the focus to the business logic around the AI. The AI doesn’t need to be smarter if it already knows the rules, the relationships, and the history before it starts thinking.
And because those rules live in YAML — not in Python, not in LangGraph nodes, not in prompt engineering — they can be modified by anyone who understands the business. A sales operations manager can change lead scoring thresholds. A CS director can add a new escalation rule. No developer required. No deployment needed.
Change the YAML, change the business process.
That’s the promise. The next articles will show whether it holds up in practice.
There is demonstrated in video on SunnyLab TV. Find me on Medium for the previous articles in this series.
Tags: Ontology, Palantir, Multi-Agent Systems, MCP Server, Artificial Intelligence, OOSDK, YAML, Claude, Python, Software Architecture, Cursor, LangGraph, Google ADK, Order to Cash, Knowledge Graph
Why I’m Building an Open Ontology SDK — and What Palantir Got Right About AI Orchestration was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.




