You audited your code. You reviewed your dependencies. Did you check what was in the model?

In 2020, a routine software update pushed to thousands of organizations contained a backdoor that went undetected for months. The SolarWinds attack didn’t succeed because the attackers were exceptionally clever at breaking into systems. It succeeded because the attackers understood something most defenders hadn’t fully absorbed: if you can compromise the supply chain, you don’t need to compromise each target individually. You let the targets install the compromise themselves.
The AI industry is about to learn this lesson the hard way.
We are in a moment of extraordinary dependency. Teams building LLM-powered applications are, almost without exception, building on top of components they didn’t create: pre-trained foundation models, open-source fine-tuning frameworks, community-contributed datasets, third-party embedding APIs, model hubs where anyone can publish weights under a permissive license. The speed of AI development has made this dependency structure essentially mandatory, nobody is training a frontier model from scratch to power their customer support chatbot.
That dependency structure is also an attack surface. And right now, most organizations have no systematic way of understanding what’s in it.
LLM03: The OWASP Category That Looks Like a Vendor Problem
The OWASP LLM Top 10 for 2025 classifies this as LLM03: Supply Chain, and the definition is deliberately broad: compromised pre-trained models, datasets, and third-party dependencies introduced before deployment. The “before deployment” framing is important. This isn’t about runtime attacks. It’s about the integrity of the components you assembled your system from.
Most security teams, when they encounter this category, treat it as a procurement problem. “We got the model from a reputable provider. We checked the license. We ran the benchmark.” That’s the equivalent of verifying that your SolarWinds renewal was processed correctly. The question isn’t whether the vendor is reputable, it’s whether you can verify that what you received is what you think you received, and whether anyone in the supply chain between origin and deployment had an opportunity to tamper with it.
For traditional software, we have tooling for this: software composition analysis, dependency scanning, SBOM generation, cryptographic signing of artifacts. The tooling is imperfect, but the discipline exists. For AI components model weights, training datasets, fine-tuning pipelines; the equivalent discipline is almost entirely absent from most organizations’ security programs.
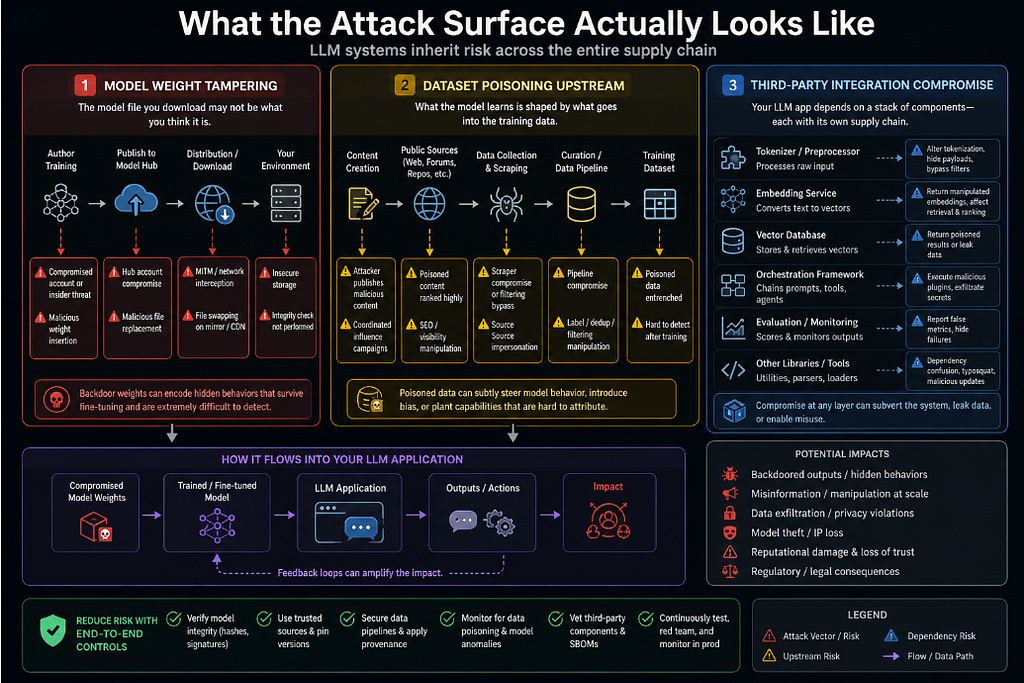
What the Attack Surface Actually Looks Like
Let me be specific about the vectors, because “supply chain” is abstract enough to be easy to dismiss.
Model weight tampering. A pre-trained model is a file, typically a large binary blob of floating-point numbers. That file can be modified. If you download a model from a public repository, you are trusting that the weights you received are the weights the author published, and that the weights the author published are the weights that were produced by the training process they described. Each of those links in the chain is a potential point of failure. Model hubs are not immune to account compromise. Researchers have demonstrated that weight files can be modified to introduce backdoor behaviors that survive fine-tuning, meaning that even if you do additional training on top of a compromised base model, the backdoor may persist.
Dataset poisoning upstream. The training data for large foundation models is scraped from the internet at scale. The data for domain-specific fine-tuning often comes from curated but still external sources. An attacker who can influence what goes into a training dataset, by publishing content to a source that will be scraped, by contributing to an open dataset, by compromising a data pipeline can influence model behavior in ways that are extraordinarily difficult to detect after the fact. MITRE ATLAS documents this class of attack explicitly, including case studies of researchers demonstrating practical data poisoning in production-adjacent settings.
Third-party integration compromise. Beyond the model itself, LLM applications typically depend on a stack of third-party components: tokenizers, vector databases, embedding services, orchestration frameworks, evaluation libraries. Each of these is a dependency with its own supply chain. A compromised tokenizer can alter what the model actually processes relative to what the developer intended. A compromised embedding service can return manipulated representations that affect retrieval behavior. These are exactly the kinds of attacks that traditional software supply chain security is designed to catch but teams often don’t apply that same scrutiny when the dependency is AI infrastructure rather than application code.
The Verification Gap
Here’s the uncomfortable gap at the center of this problem: even if you wanted to fully verify the integrity of a pre-trained model, you largely can’t.
Traditional software artifacts can be verified against a hash. The hash tells you that the binary you received is byte-for-byte identical to the binary the vendor published. What it doesn’t tell you is whether the source code that produced that binary contains vulnerabilities, or whether the build environment was clean. This is why supply chain security for software has evolved beyond hashing toward things like reproducible builds and build provenance attestation.
For AI models, we don’t even have widespread hashing as a standard practice. Model cards, the documents that describe a model’s training process, data sources, and intended use are self-reported and unverified. Reproducibility of training runs is technically feasible in principle and practically difficult in almost every production scenario. The compute required to reproduce a frontier model training run in order to verify that the published weights match the claimed process is, for most organizations, simply not available.
This doesn’t mean verification is impossible. It means the practical controls need to be risk-proportionate and pragmatic:
Verify what you can verify. Cryptographic hashes for model weight files should be a baseline requirement. If a model provider doesn’t publish hashes, that’s a gap worth raising with them. If the hashes they publish don’t match what you downloaded, that’s an incident.
Treat provenance as a security property. Where did this model come from? What was it trained on? Who has had access to the weights? These questions should be part of a formal model intake process, not an afterthought. The NIST AI RMF’s Map function explicitly includes understanding the lineage of AI components as part of risk context. Organizations that have a model register, a formal inventory of what models they use, where they came from, and what they’ve been evaluated against are in a categorically better position than those that don’t.
Behave testing as a control. Because you often can’t verify the training process, behavioral testing becomes a meaningful signal. Red-teaming a model for anomalous responses, testing for known backdoor triggers, evaluating behavior under adversarial inputs, these are not replacements for supply chain integrity controls, but they provide partial coverage when those controls aren’t available. MITRE ATLAS includes case studies of researchers detecting backdoored models through systematic behavioral testing.
Apply software composition analysis discipline to AI dependencies. Your vector database library has CVEs. Your orchestration framework has a dependency tree. Your tokenizer has a published version with known issues. These components should go through the same SCA process as your application dependencies because they are your application dependencies, and calling them “AI infrastructure” doesn’t change that.
The Governance Question Nobody Has Answered Yet
The NIST AI RMF’s Govern function asks organizations to establish clear accountability for AI system behavior. For supply chain risk, this creates an organizational question that most teams haven’t answered: who owns the decision to trust a particular model or dataset?
In traditional software procurement, there’s usually a process. Legal reviews licenses. Security reviews the vendor’s security posture. Engineering evaluates the technical fit. Someone signs off. The component enters an approved list.
For AI models, especially open-source ones downloaded from public hubs, this process often doesn’t exist. An engineer finds a model that benchmarks well, pulls the weights, integrates it into a prototype, and the prototype becomes production. The formal intake process that would catch supply chain risks, the risk assessment, the provenance review, the behavioral evaluation never happened.
Building that intake process is an organizational change, not a technical one. It requires someone in the organization to own “AI component governance” as a function, with the authority to establish criteria for approved models and the mandate to ensure that new models go through review before reaching production.

Why This Will Get Worse Before It Gets Better
The AI model ecosystem is growing faster than the security discipline around it. Model hubs are adding thousands of new models per week. Fine-tuning pipelines are becoming simpler and more accessible, which means the gap between “I found an interesting base model” and “it’s in production” is shrinking. The economic incentive to build on top of existing components rather than training from scratch is only increasing as foundation models become more capable.
All of this is happening in an environment where the tooling for AI supply chain verification is roughly where software supply chain tooling was in 2015, nascent, inconsistent, not yet widely adopted, and not yet integrated into the standard security workflow.
The organizations that are going to weather the first wave of serious AI supply chain attacks are the ones that started treating AI components with the same rigor they apply to software dependencies before the attacks became common knowledge. That means building the intake process now. It means requiring provenance documentation now. It means asking hard questions of model providers now, even when those providers aren’t used to being asked.
The supply chain is already your attack surface. The question is whether you know what’s in it.
If you’re finding this series useful, it would genuinely mean a lot if you followed along , I’m covering the full OWASP LLM Top 10 through the lens of pre-deployment architecture review, and the next piece goes deep on data and model poisoning: what it looks like at the training layer, how it survives fine-tuning, and what you can actually do about it before you ship. Hit follow so you don’t miss it.
This article is part of a series on AI application security, drawing on the OWASP LLM Top 10 (2025), MITRE ATLAS, and the NIST AI Risk Management Framework.
The Model You Didn’t Build: Why the AI Supply Chain Is Security’s Next Blind Spot was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.


