Your System Is Only as Good as Its Worst Day

Most systems look perfect when everything is working.
Request flow, responses return, dashboards stay green. It’s easy to believe that correctness is the goal, that if the system works under normal conditions, the job is done.
But real systems don’t live in normal conditions all the time.
Dependencies slow down, networks drop packets, and requests arrive in bursts. Some parts fail while others keep running. And in those moments, the question is no longer “Does it work?” but:
What happens when it doesn’t?
Systems are not defined by their success paths, but by how they behave under failure.
The happy path is a lie
Most systems are designed around a simple mental model:
Request → process → response
A clean, linear flow where every dependency is available, every call returns on time, and every component behaves exactly as expected.
This is the happy path.
But it’s not where systems actually live. In reality, dependencies fail without warning.
The result is not a neat sequence of steps, but a constantly shifting environment where timing, load, and availability are never guaranteed.
The “normal case” is not the baseline; it’s the exception.
Service is down for 10 minutes
Let’s reduce everything to a simple system:
Service A depends on Service B.
Now assume that Service B is unavailable for 10 minutes.
What happens to the requests coming into A during those 10 minutes?
- Do they fail immediately?
- Do they wait?
- Do they retry?
- Do they get queued somewhere?
Each of these choices leads to a completely different system behavior. And the story doesn’t end when Service B comes back.
- What happens to the accumulated work?
- Does the system recover smoothly or get overwhelmed?
- What if traffic is high during or after the outage?
This simple scenario exposes almost every weakness in a system’s design.
The fundamental failure modes
Before we talk about solutions, we need to understand what actually goes wrong.
System failures are not random; they follow patterns. Once you start looking closely, you’ll see the same types of problems appearing again and again, regardless of the tech or architecture.
- Overload
- Retry amplification
- Duplication
- Partial failure
Overload
When requests pile up

Every system has a limit. It may not be obvious or fixed, but there is always a point beyond which the system cannot process incoming work fast enough.
Now imagine a small gap:
The system can handle 100 requests per second, and it receives 120.
Nothing dramatic happens at first; the system doesn’t crash, it keeps working. But those extra 20 requests per second don’t disappear; they start to accumulate.
Queues begin to grow, response times increase, and requests spend more time waiting than being processed. From the outside, everything still looks “up”, but internally, pressure is building.
Then something subtle happens:
- clients start timing out
- timed-out requests are retried
Now the system is no longer with 120 requests per second; it might be dealing with 150 or more.
Overload is not a sudden failure, it is a slow buildup that eventually turns into collapse.
That’s what makes it dangerous. By the time the system visibly breaks, it has already been in trouble for a while.
Once overload starts, it rarely stays isolated; it triggers the next failure modes.
Retry amplification
When recovery makes things worse
When something fails, the natural reaction is to try again.
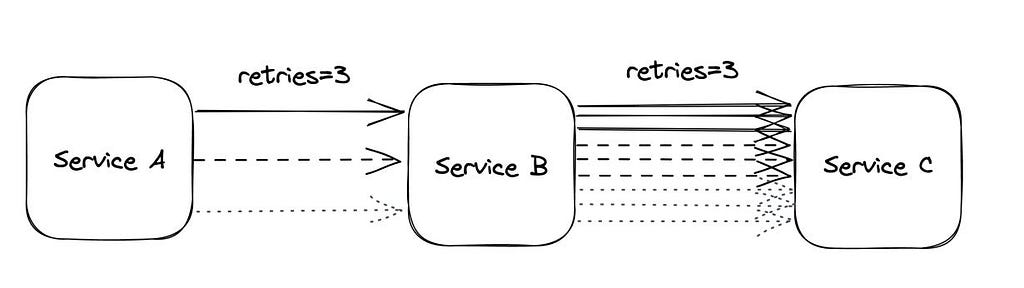
A request times out, so the client retries. If it fails again, it retries once more. On the surface, this looks resilient, an attempt to recover from temporary issues.
But under stress, this behavior turns dangerous.
Imagine a service that is already slow due to overload. Requests start timing out. Clients begin retrying. Now each original request is no longer one request; it becomes two, three, sometimes more.
The system is now receiving more traffic precisely when it is least able to handle it.

This creates a feedback loop:
- system slows down
- timeouts increase
- retries increase
- load increases further
- system slows down even more
What started as a recovery mechanism becomes a load multiplier.
The most dangerous part is that nothing is technically “wrong”. Each component is behaving as designed. But together, they amplify the problem instead of solving it.
This is how systems that were only slightly degraded end up fully unavailable.
Duplication
When the same work happens twice
In a perfect world, every request would be processed exactly once. In reality, you can’t rely on that.
Consider a simple scenario:
- A request is sent
- The system processes it successfully
- But the response is delayed or lost
From the client’s perspective, it looks like a failure. So it retries.
Now the system receives the same request again and processes it again.
The result is duplication.
This is not a rare edge case. It is a direct consequence of timeouts, retries, and unreliable networks. The system cannot distinguish between a request that failed and a request that succeeded but whose response never arrived.
And the consequences are not just technical, they are real:
- payments charged twice
- orders created multiple times
- notifications sent repeatedly
The key shift is this:
You must assume that any operation may be executed more than once.
Partial failure
Most systems are not a single unit; they are a collection of services, databases, and external dependencies.
Which means they don’t fail all at once.
Instead, some parts keep working while others degrade or stop responding.
One service might be fast, another might be slow, and a third might be unavailable. From the outside, the system is neither fully up nor fully down; it’s somewhere in between.
This is partial failure.
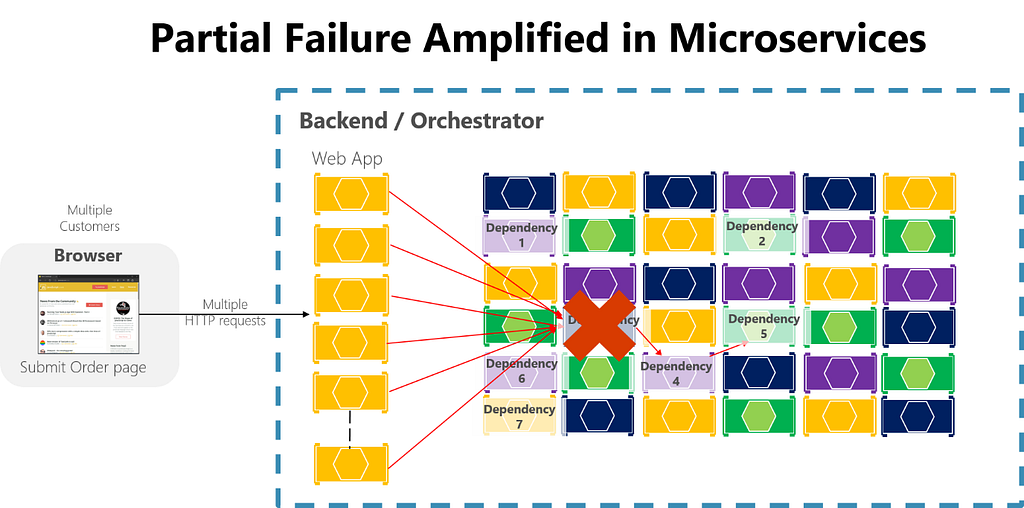
It’s one of the hardest problems to reason about, because behavior becomes inconsistent:
- some requests succeed
- some fail
- some hand indefinitely
There is no single, clear signal that “the system is broken.” This creates ambiguity:
- Did the operation succeed or not?
- Is the dependency down or just slow?
- Should we retry or stop?
These are not edge cases; they are the normal operating conditions of real systems. And once partial failure appears, it interacts with everything else:
- overload increases
- retries begin
- duplicates appear
What looks like a small issue in one component quickly spreads across the system.
Core concepts that address these failures
Once you understand how systems fail, the next step is not to eliminate those failures; that’s impossible. Instead, we design around them.
Each of the failure modes we’ve seen leads to a specific kind of response:
- overload forces us to control intake
- retries forces us to manage timing and limits
- duplication forces us to protect correctness
- partial failure forces you to tolerate uncertainty
These are not abstract concepts. They are practical mechanisms that shape how a system behaves under stress.
Good system design is not about avoiding failure, but about responding to it in a controlled and predictable way.
- Backpressure
- Idempotency
- Queuing
- Dead Letter Queues
- Controlled Retries
Backpressure
Controlling the flow
The first problem we saw was overload: the system accepts more work than it can handle. Backpressure is the response to that.
Instead of allowing unlimited requests to enter and hoping the system can keep up, backpressure enforces a simple rule:
Only accept as much work as you can process safely.
This means the system must sometimes slow down or reject incoming requests. That may sound counterintuitive. Why turn work away? But the alternative is worse: accepting everything and collapsing under the load.
Without backpressure:
- queues grow without bound
- latency increases
- timeouts trigger retries
- system spirals into failure
With backpressure:
- intake is controlled
- capacity is protected
- failure becomes visible and immediate
This shifts the system from failing internally to failing explicitly. Some requests may be delayed or rejected, but the system as a whole remains stable.
A system that tries to handle everything will eventually handle nothing.

Backpressure is not a single feature you turn on. It is a set of decisions about when and how the system refuses work.
Rate limiting
Define a hard boundary
The simplest form of backpressure is to set a limit:
- accept up to N requests per second
- reject anything beyond that

When the limit is reached, the system responds immediately instead of letting requests pile up. This protects capacity at the point of entry.
Bounded queues
Limit how much you buffer
Queues are useful, but they can become dangerous if they grow without limit.
A bounded queue introduces a cap:
- if the queue is not full → accept work
- if the queue is full → reject new work
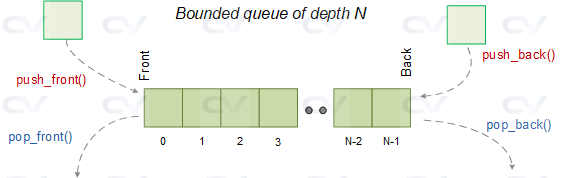
This prevents memory exhaustion and unbounded latency.
Load shedding
Drop work selectively
Not all requests are equally important. Under stress, the system can drop low-priority requests and preserve critical ones. For example:
- health checks or background jobs may be skipped
- core user operations are still served
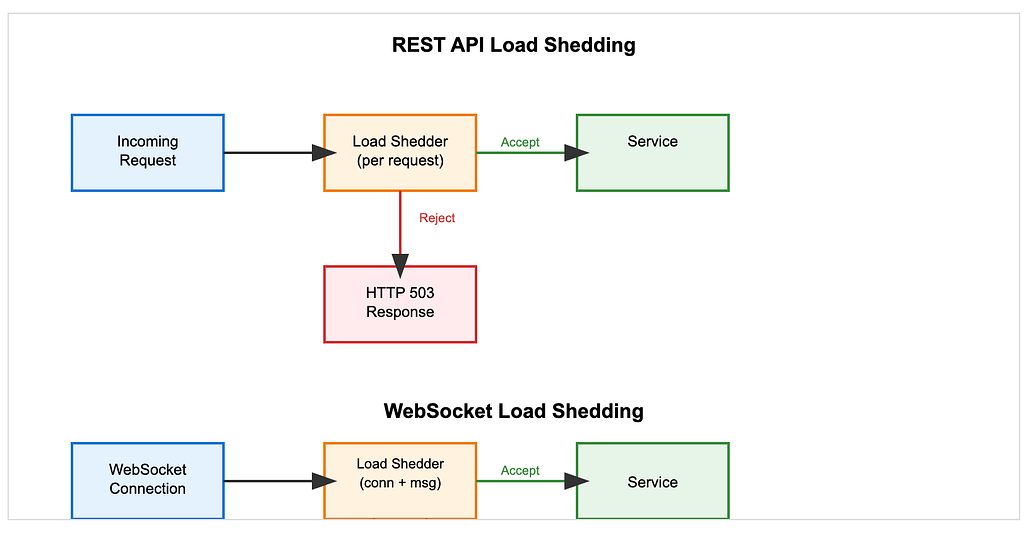
When capacity is limited, survival depends on prioritization.
Timeouts
Avoid holding resources too long
Requests that take too long consume resources that could be used elsewhere. By enforcing timeouts:
- slow operations are cut off
- resources are freed
- system avoids getting stuck
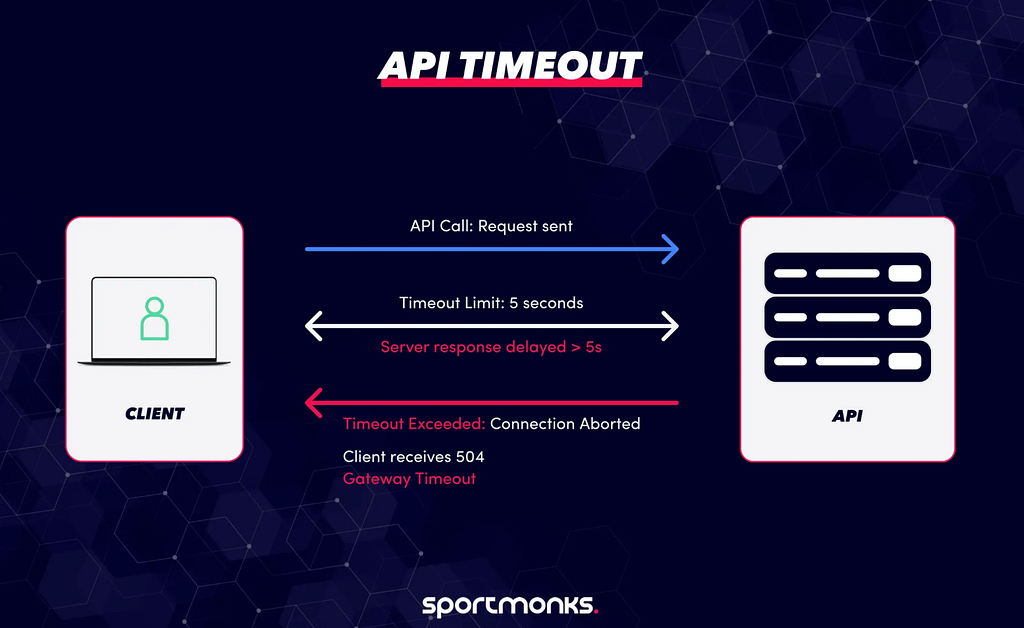
This is a subtle form of backpressure; it limits how long work can occupy the system.
Signaling upstream
Slow the source
In some systems, backpressure is not just rejection; it is communication.
Instead of dropping requests, the system signals upstream: send less, slow down.
This is common in streaming or pipeline systems.
Idempotency
Making repeats safe
We’ve already seen that duplication is unavoidable. Requests can be retried. Messages can be delivered more than once. Responses can be lost even when the work has already been done.
You cannot guarantee that an operation will run exactly once.
Idempotency is the response to that reality.

An operation is idempotent if running it multiple times produces the same result as running it once.
This is usually done by attaching a unique identifier to the request:
- a transaction ID
- an idempotency key
When the system receives a request:
- if it has never seen the key → process it
- if it has seen the key before → return the previous result
The operation is not executed again.
Without idempotency:
- retries can create duplicate effects
- systems become inconsistent
- errors propagate silently
Idempotency is not an optimization. It is a safety guarantee under uncertainty.
Queuing
Absorbing instability
Some failures are not permanent; they are temporary.
A dependency might be down for a few minutes. A service might be slow under load. In these situations, the problem is not that the work cannot be done, but that it cannot be done right now.
Queuing is the response to that.
Instead of forcing immediate processing, the system separates accepting work & processing work.
Work is stored first and handled when the system is ready.
The system no longer depends on everything being available at the same moment. A request can be accepted immediately or processed later. This decoupling is what allows systems to remain stable under fluctuation.
Without a queue:
- requests fail when a dependency is unavailable
- retries increase pressure
- temporary issues become system-wide failure
With a queue:
- incoming work is preserved
- pressure is absorbed
- system gains time to recover
There is a trade-off. Queueing introduces delay. Work is no longer instantaneous; it becomes eventual.
- responses may not be immediate
- processing order may vary
- backlog may build up
Stability is gained by accepting time as a variable.

Queues can hide problems. If the system is consistently slower than incoming traffic, then the queue grows, delays increase, and issues become visible only much later.
This is why queues must be bounded and monitored.
Dead letter queues
Accepting failure
Not all work can be completed. Some requests will fail; not because of timing, but because they are invalid, inconsistent, or impossible to process. No amount of retries or waiting will change that.
Dead Letter Queues (DLQ) are the response to this reality.

Instead of retrying forever, the system sets a boundary.
Try a limited number of times. If it still fails, isolate it.
Failed messages are moved to a separate queue, DLQ, where they can be inspected and handled later.
The system no longer assumes that everything must eventually succeed. Instead, it ensures that everything must either succeed or be accounted for.
The trade-off is that moving to a DLQ means accepting that:
- some work is not completed immediately
- some failures require manual or delayed resolution
Stability is preserved by isolating what cannot be fixed automatically.
Controlled retries
Not all retries are equal
Retries are necessary. Failures happen due to timeouts, temporary outages, or network issues. In many cases, simply trying again is enough to recover.
Every retry consumes capacity.
Retries should not be immediate, unlimited, or blind. They must be delayed, limited, and selective.

Instead of retrying immediately, the system introduces time and variation:
- each retry waits longer than the previous one
- retries are spread out rather than synchronized
- total retry attempts are capped
This reduces pressure on the system and gives it time to recover.
A critical distinction:
- transient failures (timeouts, temporary overload) → retry may help
- permanent failures (invalid outputs, business rule violations) → retry is pointless
Retrying everything is not resilience; it is inefficiency. A retry only makes sense if the next attempt has a chance to succeed.
Designing for failure
Failures in systems do not stay isolated. What begings as a small issue rarely remains contained. It interacts with other parts of the system and triggers a chain of reactions.
A service slows down. Requests start timing out. Clients retry. Load increases. Queues grow. Some components fail while others continue. What started as a minor degradation becomes a system-wide problem.
This is where the shift happens.
If failure is inevitable and interconnected, then system design cannot be based on ideal conditions. It must be based on what happens under stress.
Engineering is not only about making things work, but it is also about making sure they continue to work when they don’t.
With this perspective, the definition of success changes.
A system is working because:
- behaves predictably under stress
- fails in controlled ways
- protects its own stability
- recovers without causing further damage
Writing code gets a system to run. Understanding failure is what keeps it running.
Read More
- From REST to gRPC to GraphQL: Choosing the Right Protocol for Your APIs
- API Load Testing: A Comprehensive Guide to Concepts, Metrics, and Test Types
Sources
https://www.telerik.com/blogs/building-resilient-apis-retry-pattern
https://www.geeksforgeeks.org/system-design/dead-letter-queue-system-design/
https://www.mdpi.com/1424-8220/23/6/3024
https://sketechnews.substack.com/p/idempotency-duplicate-requests
https://www.sportmonks.com/glossary/api-timeout-2/
https://www.srao.blog/p/load-shedding-when-your-api-needs
https://www.chipverify.com/systemverilog/systemverilog-queue
https://www.geeksforgeeks.org/system-design/rate-limiting-in-system-design/
https://systemdr.substack.com/p/backpressure-mechanisms-in-distributed
https://keyholesoftware.com/preventing-retry-storms-with-responsible-client-policies/
https://newsletter.pragmaticengineer.com/p/resiliency-in-distributed-systems-74c
https://blog.zeplin.io/collaboration/what-is-the-happy-path/
System Resilience: From Failure Modes to Design Patterns was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.



