Qwen3.6–27B: The 27-Billion Parameter Model Beating 397-Billion Parameter Giants
 Antalpha | Web3 AI Router4 min read·Just now
Antalpha | Web3 AI Router4 min read·Just now--
Alibaba’s new open-source dense model rewrites the rules of AI efficiency
When the news dropped that a 27-billion parameter model had outperformed a model with 397 billion total parameters, the AI community reacted the only way it knows how: skepticism, then awe, then a scramble to download it.
That’s Qwen3.6–27B, the latest release from Alibaba’s Qwen team — and it’s one of those rare moments in AI where the headline numbers don’t do justice to what’s actually happening underneath.
The Size Debate Is Over. The Efficiency Era Began.
For years, bigger was unambiguously better. GPT-4, Claude 3.5, Gemini Ultra — the race was measured in parameters, in compute, in benchmark dominance.
Qwen3.6–27B doesn’t win by being the biggest. It wins by being smart about what it keeps.
The architecture is a dense model — every parameter is active, every parameter contributes. This is fundamentally different from the MoE (Mixture of Experts) approach, where a 397B model only “uses” 17B parameters at any given moment. The dense model has no routing overhead. No gating logic deciding which expert to consult. Just 27 billion parameters doing their job, full stop.
The result: a model you can actually run on consumer hardware (with quantization), at a fraction of the inference cost of a 397B MoE system — while outperforming it on the benchmarks that matter most.
The Coding Numbers That Got Everyone’s Attention
Here’s where it gets concrete. Qwen3.6–27B versus the previous open-source flagship, Qwen3.5–397B-A17B:
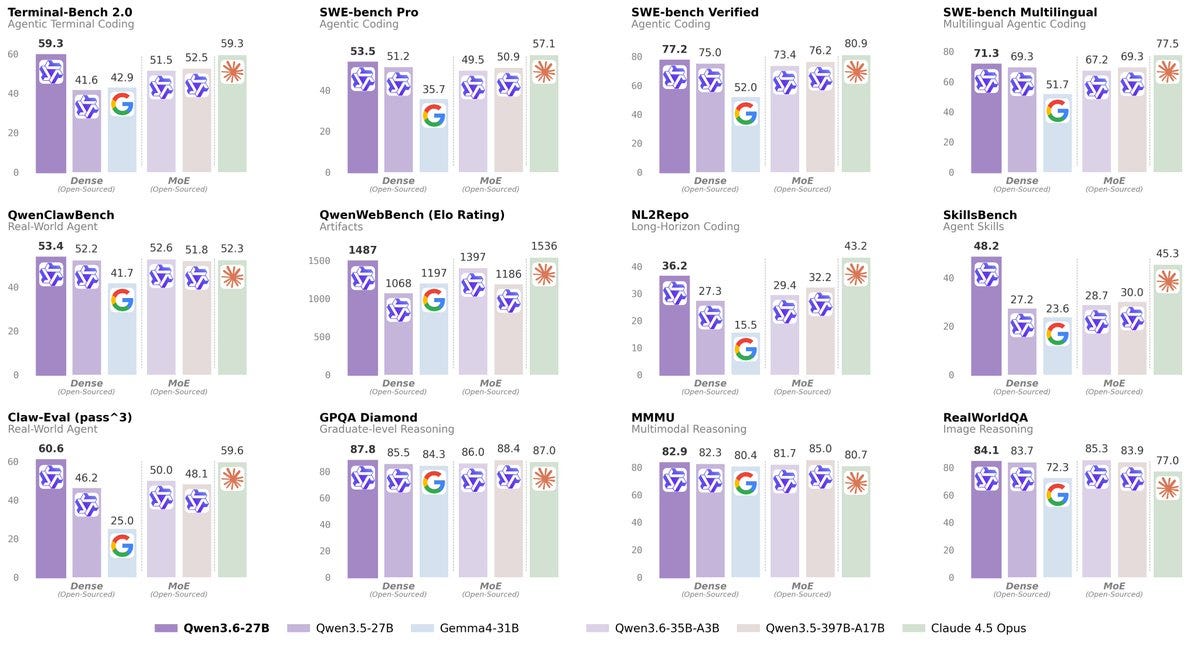
On Terminal-Bench 2.0 — a benchmark testing an agent’s ability to navigate real development environments — Qwen3.6–27B scores 59.3 versus 52.5. A 13% improvement. On SkillsBench, measuring practical software engineering skills, it nearly doubles the predecessor’s score (48.2 vs 30.0).
This isn’t incremental. This is the kind of gap that makes you go back and check your methodology.
And it’s not just coding. On GPQA Diamond — a doctorate-level science reasoning benchmark — Qwen3.6–27B scores 87.8, competitive with models many times its size.
What “Agent Coding” Actually Means Here
The Qwen team makes a specific claim: this model achieves “flagship-level agent coding.” Let’s unpack what that means practically.
Agent coding isn’t about writing a function from a prompt. It’s about:
- Reading an existing codebase and understanding what needs to change
- Planning multi-step modifications across multiple files
- Executing terminal commands, handling errors, iterating
- Maintaining context across a long session of tool use
This is where most models fall apart. They can write clean functions in isolation, but get lost in real workflows. SWE-bench Verified tests exactly this — real GitHub issues, requiring real code changes across entire repositories.
Qwen3.6–27B’s scores on SWE-bench Verified (77.2) and SWE-bench Pro (53.5) put it ahead of every open-source model at its scale, and competitive with closed models that cost 10x more to run.
The Multimodal Dimension
One detail that shouldn’t get lost: Qwen3.6–27B is a multimodal model. It handles text and images, and supports both “thinking” and “non-thinking” modes — meaning you can toggle between fast inference and deep deliberation depending on the task.
This matters for developers building AI-powered tools: one model, one API endpoint, capable of handling both document analysis and code generation without switching providers.
The Open Source Angle
Qwen3.6–27B is available now on Qwen Studio, Hugging Face, and ModelScope — all with open weights.
Open weights mean you can run it locally, fine-tune it on your codebase, and integrate it into products without per-token API costs. For startups and indie developers building in the AI coding space, this is a real alternative to paying for Claude or GPT-4 API calls.
Why This Matters Beyond the Benchmarks
We’re entering a phase in AI development where architecture innovation is starting to matter as much as scale. Dense models, MoE, attention mechanisms — these architectural choices are creating efficiency gaps that pure scale can’t close.
A 27B dense model outperforming a 397B MoE model is a sign that the field is getting sophisticated about how to allocate parameters, not just how many to use.
Qwen3.6–27B isn’t just a good model. It’s evidence that the next wave of AI progress won’t be measured in parameters — it’ll be measured in efficiency, cost-per-task, what you can do with a model that fits on a single GPU.
The Takeaway
If you’re building AI-powered developer tools, Qwen3.6–27B is worth your attention. The combination of:
- Top-tier coding performance
- Open weights (no API dependency)
- Multimodal capability
- Reasoning competitive with models 3–5x its size
…is a combination that didn’t exist six months ago.
The era of measuring AI progress in parameter counts is ending. Qwen3.6–27B is one of the clearest signals that the efficiency era has begun.
Source: Qwen AI Blog — Qwen3.6–27B: 270亿参数稠密模型,旗舰级编程能力
Closing Thoughts
This article is based on Qwen Team’s technical blog, with all data sourced from official benchmarks. If you have any thoughts on Qwen3.6–27B’s practical applications, AI model selection, or building AI-powered tools — feel free to reach out.
The world moves fast. But meaningful conversations never go out of style.
Threads:https://www.threads.com/@antalpha_ai



