Python’s Type-Hinting Shift: A Deep Dive into Postponed Evaluation of Annotations (from __future__ import annotations)
This article focuses on the practical engineering tradeoffs and the CPython compilation mechanics behind a deceptively small import line.

Prologue: a “mysterious” import line
During development, I noticed a generated file starting with from __future__ import annotations. That single line looks harmless, but it raises a real question: why does Python’s type system need a future switch at all? Who benefits from it? And what does it change under the hood?
This article walks through the mechanics behind postponed annotations and explains why a compile-time flag can reshape the entire lifecycle of type hints.
In Python’s typing evolution, from __future__ import annotations (PEP 563) marked a major pivot. It is not just a convenience feature—it changes how Python stores and later resolves annotations.

Why it exists: the practical value
- Faster imports in annotation-heavy codebases
Large projects can easily accumulate thousands of annotations. In the legacy model, Python eagerly evaluates annotation expressions at import time (e.g., nested generics such as Dict[str, List[Record]]). That costs CPU during module import.
With postponed evaluation enabled, Python stores annotations as strings instead of executing them immediately, keeping imports much lighter. - Forward references and circular dependencies become easier
You can reference a class in its own method signatures without worrying about definition order. You also reduce the need for imports that exist only to satisfy type hints.
- Introduced: Python 3.7 (opt-in via __future__).
- Defaulting status: It was once planned to become the default behavior in a later Python release, but the rollout was deferred because many runtime-introspection libraries depend on eagerly-evaluated annotations.
- Stdlib reference: future — Future statement definitions
The pain point: the annotation “lifecycle” before PEP 563
Before PEP 563, Python handled annotations in an **eager** way.
That means when you write def foo(x: int) -> list: ..., Python tries to resolve int and list while importing the module, and stores the actual objects into __annotations__.
What gets expensive
- Forward references: inside a class body, methods can’t safely refer to the class itself unless you quote the name.
- Slower startup: importing modules becomes more expensive when annotations contain complex expressions.
- Import cycles: adding imports “just for typing” can trigger circular import chains.
A key mindset shift: type hints are not type declarations
To understand the annotations future import, it helps to correct a common misconception: Python type hints are not enforcement.
In languages like Java or C++, types are part of the compilation contract. In Python:
- In source code: annotations communicate intent to IDEs and static type checkers (MyPy, Pyright) and to humans.
- At runtime: Python usually treats them as metadata stored in __annotations__. The interpreter does not enforce them automatically.
A useful mental model:
Writing x: str in Python does not constrain x to be a string. It records “I intend to treat x as a string.”
From “execute now” to “record now”
Legacy behavior is action-oriented:
“Here is an annotation — resolve it into real objects now.”
With postponed annotations enabled, the behavior becomes metadata-oriented:
“Store the annotation as text; resolve it only when someone actually needs it.”
Why it must be at the top level
__future__ imports are special in CPython.
The placement rules
It must appear:
- At the top level of the module.
- Before any other executable code (including most imports).
- With only a module docstring allowed above it.
If you write import os first and then from __future__ import annotations, Python raises a SyntaxError.
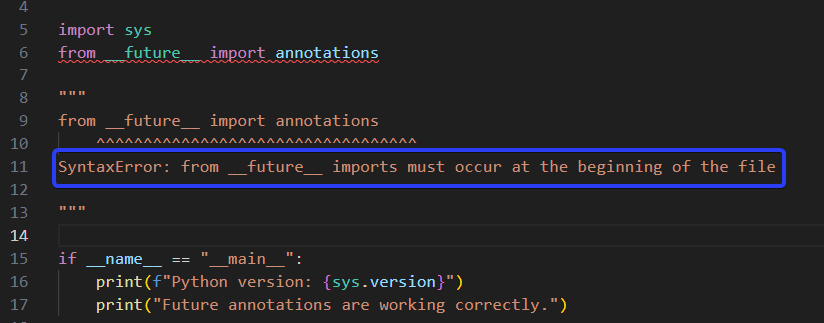
The real reason: it’s a compiler switch
A __future__ import is not “just another import.” It is effectively a compile-time flag that changes how CPython compiles the module.
CPython’s pipeline is:
source code → AST → bytecode (.pyc)
Once the compiler starts translating the module using the legacy rules, it cannot realistically “rewind” and rebuild the already-produced AST/bytecode with a different annotation strategy.
A simple analogy: you must tell the translator which mode to use before they begin translating the first sentence.
Scope: it does not affect your whole project
A common misconception is that enabling postponed annotations “spills” globally. It does not.
from __future__ import annotations applies per module:
- If server.py enables it, only annotations inside server.py are postponed.
- If schema.py does not, its annotations keep the eager behavior—even if server.py imports it.
That isolation is crucial for backward compatibility.
What CPython changes internally
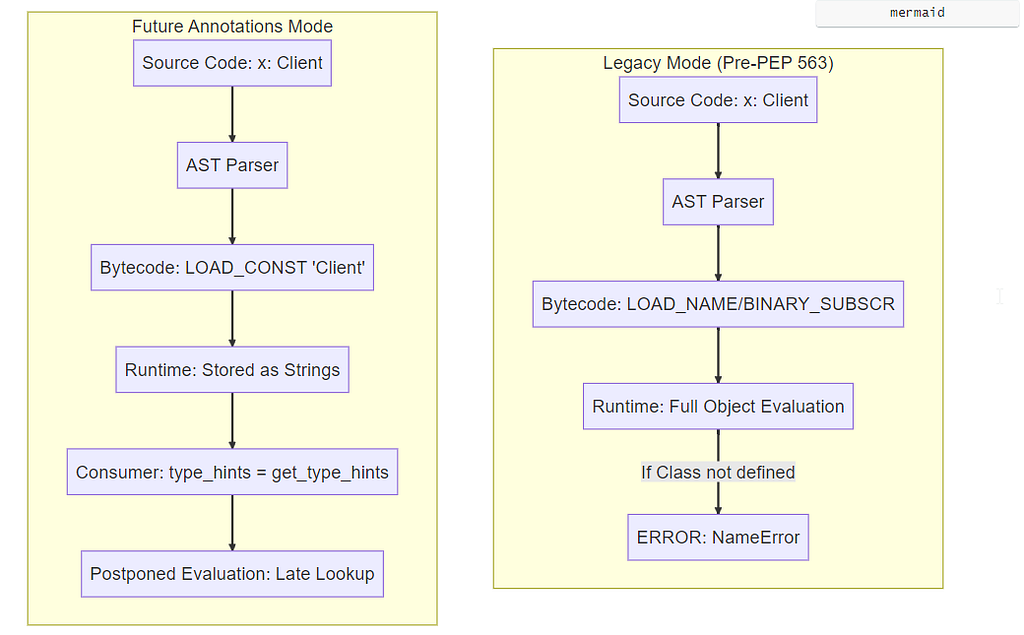
At compile time, from __future__ import annotations sets a flag on the module’s code object. The compiler then emits different bytecode for annotations: it stores string constants instead of generating runtime name lookups.
Bytecode impact: goodbye, LOAD_NAME
In Python bytecode, postponed annotations cause a noticeable shift.
- Legacy mode: annotations trigger runtime lookups such as LOAD_NAME / LOAD_GLOBAL. Complex generics also introduce additional operations (e.g., BINARY_SUBSCR). The goal is simply to put the resolved objects into __annotations__.
a: int = 10
class User:
pass
def f(x: User) -> "User":
return x
# Note: Without the future import enabled, the following will be objects/strings depending on the exact annotation.
print(__annotations__.get("a")) # -> <class 'int'>(module-level)
print(f.__annotations__) # -> {'x': <class '__main__.User'>, 'return': 'User'}
import typing
print(
typing.get_type_hints(f)
) # -> {'x': <class '__main__.User'>, 'return': <class '__main__.User'>}
- Future annotations mode: the compiler avoids those lookups for annotations. It can store the annotation text with something as simple as LOAD_CONST.
from __future__ import annotations
a: int = 10
class User: pass
def f(x: User) -> "User":
return x
# Note: With the future import enabled, the following will be strings.
print(__annotations__.get('a')) # -> 'int'(module-level)
print(f.__annotations__) # -> {'x': 'User', 'return': 'User'}
import typing
print(typing.get_type_hints(f)) # -> {'x': <class 'mymod.User'>, 'return': <class 'mymod.User'>}
# If the annotation were "othermod.User", the stored string would be "othermod.User".
# Resolving it requires the referenced module/type to be available when get_type_hints runs.
At runtime, Python no longer has to resolve annotation names during import. That both reduces import cost and avoids some order-of-definition failures.
Side-by-side examples
Below are two common patterns compared across purpose, mechanics, pros/cons, and when to use them.
Example A: legacy behavior (no postponed annotations)
- Goal: keep annotations as real runtime objects when possible.
- Mechanism: refer to the type name directly and let Python resolve it during import.
class Node:
def add_child(self, child: Node): # NameError: name 'Node' is not defined
pass
- Pros: direct runtime introspection is straightforward when names resolve; some dynamic/reflection code becomes simpler.
- Cons: forward references can fail; import-time work scales with annotation complexity.
- Best for: small scripts, code with strict definition order, or systems that heavily rely on runtime inspection and don’t want late resolution.
Example B: postponed annotations (from __future__ import annotations)
- Goal: store annotations cheaply and resolve them only when needed.
- Mechanism: enable the future import at module top level so the compiler stringifies annotations.
from __future__ import annotations
class Node:
def add_child(self, child: Node):
# Internally stored as: {'child': 'Node'}
pass
import typing
print(typing.get_type_hints(Node.add_child))
# Output: {'child': <class '__main__.Node'>}
- Pros: lighter imports; forward references work naturally; easier incremental migration in large codebases.
- Cons: frameworks must explicitly resolve annotations; errors can appear later (“late failures”).
- Best for: large services, modular architectures, heavy use of forward references, or performance-sensitive imports — ideally paired with strong static checking.
Key differences at a glance
- Performance: postponed mode reduces import-time work.
- Runtime introspection: legacy mode gives you real objects earlier; postponed mode requires an explicit resolution step.
- When errors surface: legacy mode fails early (often at import); postponed mode may fail later (when something resolves the hints).
The controversy: why it’s not the default everywhere
PEP 563 improves performance and forward references, but it also created real friction.
Runtime frameworks (e.g., Pydantic, FastAPI) feel the pain
Many libraries use annotations for runtime reflection: they build validators, schemas, dependency graphs, and serializers from type hints.
When annotations become strings:
- Reconstruction cost
Libraries must resolve strings back into real objects — often via typing.get_type_hints() (which may evaluate expressions) or controlled eval() logic. - Scope and closure pitfalls
If a type lives in a local scope (e.g., a class defined inside a function), recovering it later can be difficult or impossible without the right namespace. - Maintenance burden
This shifts complexity from CPython import-time work to every library that consumes annotations at runtime.
PEP 563 vs. PEP 649 (the direction of travel)
Because of these tradeoffs, the community explored alternative designs such as PEP 649 (deferred evaluation via descriptors / callable machinery) to achieve lazy evaluation without forcing everything into strings.
Summary: a performance lever with explicit costs
You can think of from __future__ import annotations as a performance and ergonomics lever:
- It reduces import-time overhead by postponing annotation resolution.
- It removes ordering constraints for forward references.
- It moves responsibility: static tools keep you honest during development; runtime frameworks must do explicit resolution.
Static checkers are unaffected
MyPy, Pyright, and IDEs read source code. They can type-check regardless of whether the module enables postponed annotations.
Runtime can “fail later”
Postponed annotations can hide problems until a framework resolves them. Here’s a minimal example of a delayed NameError:
from __future__ import annotations
import typing
# ⚠️ NonExistentType does not exist.
# Without postponed annotations, Python would raise NameError here during import.
# With postponed annotations, the module loads and the error appears later.
def process_data(data: NonExistentType) -> str:
return str(data)
print("--- Step 1: module loads successfully ---")
print(f"Annotations: {process_data.__annotations__}")
print("\n--- Step 2: later, a framework resolves type hints ---")
try:
hints = typing.get_type_hints(process_data)
except NameError as e:
print(f"!!! Late failure caught: {e} !!!")
In real projects, this often shows up with if TYPE_CHECKING: imports: static tools see them, runtime doesn’t execute them, and your resolver hits missing names later.
References (PEPs and docs)
- PEP 563 — Postponed Evaluation of Annotations
- PEP 649 — Deferred Evaluation of Annotations Tentatively Using Descriptors
- PEP 484 — Type Hints
- Python Docs: future
Python’s Type-Hinting Shift: A Deep Dive into Postponed Evaluation of Annotations (from __future__… was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.



