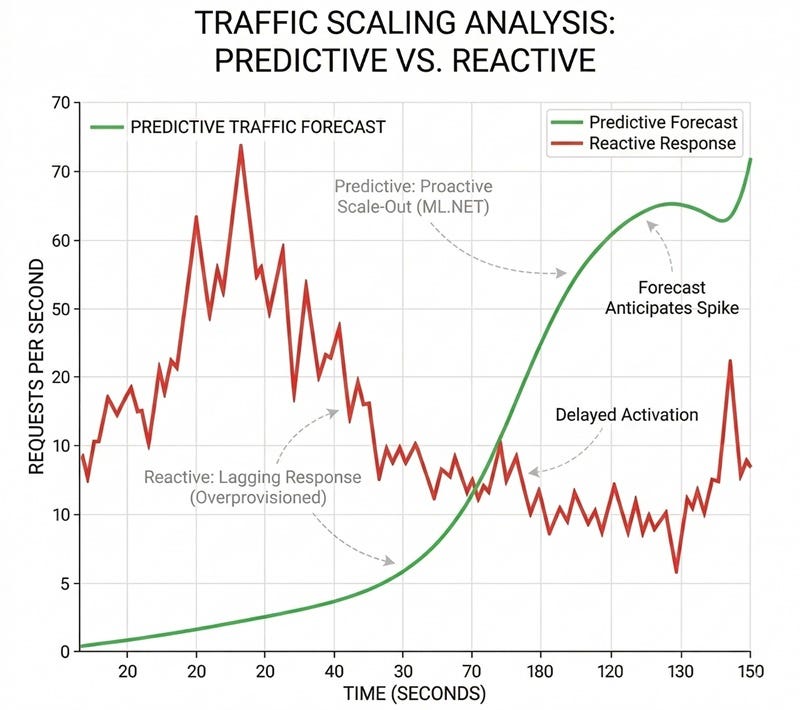
The Hidden Cost of Reactive Infrastructure Most cloud architectures today operate on a “tax of fear” where resources are over-provisioned by 30% to 50% simply to survive traffic spikes. This happens because traditional auto-scaling is fundamentally reactive. It waits for a CPU or RAM threshold to be breached before initiating the provisioning process. In high-throughput environments, by the time a new node is healthy and receiving traffic, the latency spike has already impacted the user experience. This gap between detection and action is where engineering budgets are wasted on idle compute instances.
The Failure of Surface Level Monitoring Standard cloud dashboards focus on lagging indicators. In high-concurrency .NET environments, metrics like CPU average often fail to signal a bottleneck until it is too late. A system can be struggling internally while the CPU still appears to be within normal limits.
The true leading indicators of an imminent latency crisis are low-level runtime frictions. Ignoring signals like thread context switching or memory management pauses is the primary reason scaling strategies remain expensive and slow.
Decoding Imminent Latency with Telemetry To shift from reactive to proactive, the infrastructure must monitor the internal nervous system of the application. In our engineering models, we identified four specific low-level metrics that serve as precursors to failure.
using Microsoft.ML.Data;
namespace CloudSealed.ML.Engine.Models
{
public class TelemetryData
{
[LoadColumn(0)] public float ThreadContextSwitches { get; set; }
[LoadColumn(1)] public float Gen2GcCollections { get; set; }
[LoadColumn(2)] public float IopsThrottleRate { get; set; }
[LoadColumn(3)] public float NetworkQueueLength { get; set; }
[LoadColumn(4)] public float Latency { get; set; }
}
}
High rates of context switching indicate that the CPU is spending more time managing threads than executing business logic. When combined with a Generation 2 Garbage Collection cycle, system latency grows exponentially.
Building a Predictive Brain with ML.NET The solution to infrastructure waste lies in predictive observability. By integrating ML.NET directly into the telemetry pipeline, it is possible to model the non-linear relationships between these low-level signals and end-user latency.
Using regression algorithms like FastTree (Gradient Boosted Decision Trees), the system can analyze telemetry to forecast a breach before it manifests.
public void TrainModel(string dataPath)
{
var dataView = _mlContext.Data.LoadFromTextFile<TelemetryData>(dataPath, hasHeader: true, separatorChar: ',');
var pipeline = _mlContext.Transforms.Concatenate("Features",
nameof(TelemetryData.ThreadContextSwitches),
nameof(TelemetryData.Gen2GcCollections),
nameof(TelemetryData.IopsThrottleRate),
nameof(TelemetryData.NetworkQueueLength))
.Append(_mlContext.Regression.Trainers.FastTree(labelColumnName: nameof(TelemetryData.Latency), featureColumnName: "Features"));
_trainedModel = pipeline.Fit(dataView);
}
Ensuring Determinism for Mission Critical Systems A critical requirement for enterprise infrastructure is auditability. AI models cannot operate as black boxes when financial resources are at stake. By enforcing a deterministic context with a fixed seed during the MLContext initialization (new MLContext(seed: 42)), we guarantee that every diagnostic report and training session can be reproduced with absolute precision. This satisfies both engineering reliability and compliance requirements.
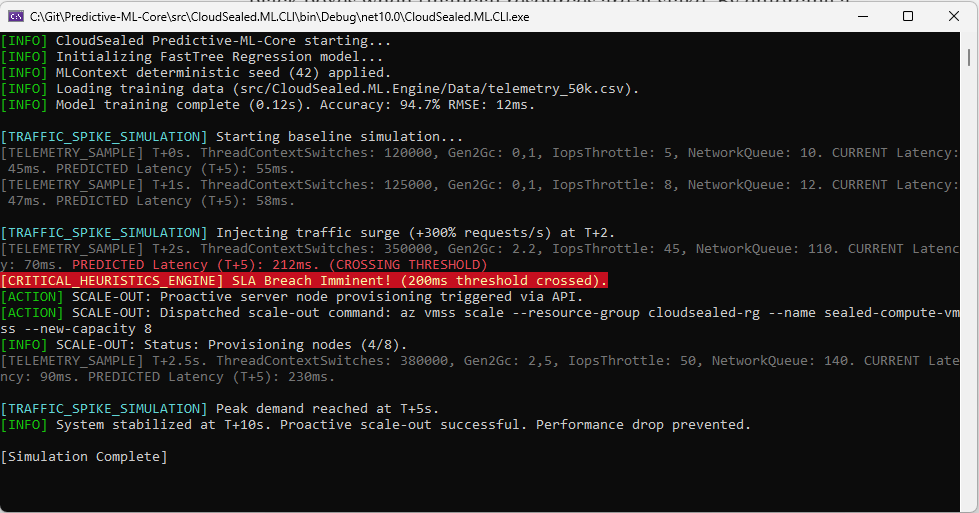
Real Time Inference and Proactive Scaling Implementing this predictive layer allows the infrastructure to understand its own breaking point. When the model evaluates a sudden spike in network queue lengths and thread locks, it predicts the resulting latency. If the forecast crosses an unacceptable threshold, it triggers a scale-out event heuristically.
var prediction = engine.Predict(trafficSpike);
Console.WriteLine($"[FORECAST] Predicted Latency {Math.Round(prediction.PredictedLatency, 2)} ms");
if (prediction.PredictedLatency > 200)
{
Console.WriteLine("[CRITICAL] SLA Breach Imminent (200ms threshold crossed).");
Console.WriteLine("[ACTION] Triggering Node Scale-Out & Process Offloading Heuristics.");
}
This ensures that extra compute capacity is fully provisioned and warm before the peak traffic actually hits the cluster, allowing for a much tighter and highly efficient baseline.
Technical Precision Over Resource Waste Moving toward a self-regulating environment requires a conceptual shift from static monitoring to predictive modeling. By leveraging high-fidelity telemetry and deterministic ML.NET contexts, engineering teams can finally align their cloud spend with actual demand. This transition protects both the system’s resilience and the organization’s budget without relying on traditional over-provisioning.
The complete engine architecture, CLI tools, and unit tests are open-source and available for review.
GitHub Repository https://github.com/cloudsealed/Predictive-ML-Core.git
Rodrigo Martinez Pinto is a Senior Software Engineer, specializing in High-Frequency Trading (HFT) systems and high-performance cloud architecture optimization.
Predictive Scaling with ML.NET to Prevent Cloud Overprovisioning was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.





