Nvidia’s 30B Model That Eats PDFs, Screen Recordings, and Your Helpdesk Queue that runs on 24gb consumer card. It is OpenSource
TLDR
- Nemotron 3 Nano Omni is open-weights model with BF16, FP8, and NVFP4 available on HF.
- 30B total params, 3B active per token, hybrid Mamba + Transformer + MoE backbone, with C-RADIOv4-H for vision and Parakeet-TDT-0.6B for audio. 256K context.
- Tops six leaderboards including MMLongBench-Doc, OCRBenchV2, WorldSense, DailyOmni, VoiceBench.
- Beats Qwen3-Omni 30B-A3B in most categories that matter. I am not discounting Qwen3 yet
- Up to 9x throughput vs other open omni models at the same interactivity, and 2.9x single-stream reasoning speed.
- vLLM, SGLang, TRT-LLM, Unsloth, LM Studio, fal, AWS SageMaker, Crusoe, OpenRouter; the cookbook surface is genuinely large.
Free Link for everyone: 🔔 clap 50 | follow | Subscribe 🔔
Help me get my non-technical profile up and running by following and subscribing 👉 https://medium.com/@ThisWorld
Disclaimer: This story was written with the assistance of an AI writing program.
The architecture
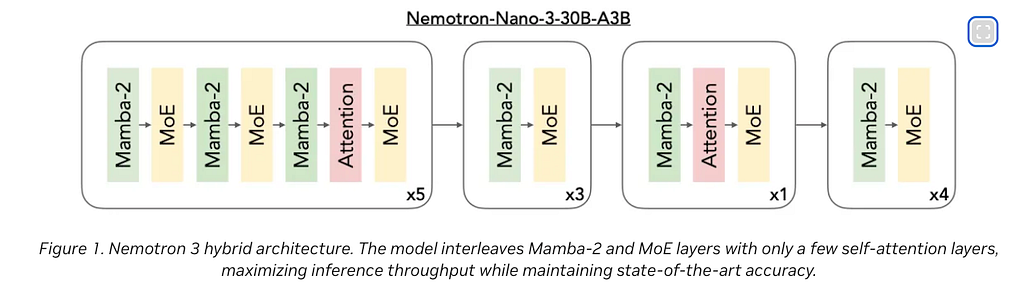
Mamba, Transformer, MoE in the same backbone
a few interesting architectural decisions. Nemotron 3 Nano Omni is built on the Nemotron 3 Nano 30B-A3B language backbone. Inside that backbone you get 23 Mamba selective state-space layers for cheap long-context, 23 MoE layers with 128 experts and top-6 routing plus a shared expert, and 6 grouped-query attention layers that keep global interaction expressive.
On the multimodal side of the equation C-RADIOv4-H was used for video and for audio Parakeet-TDT-0.6B-v2. Both of them talk to each other through a 2-layer MLP projector, then everything gets interleaved as one token stream so the LLM does cross-modal reasoning natively, not as a stitched-together pipeline.
It was not done previously by any other model, but now the merged back end of Mamba and Transformers, in an M O E is more efficient. Its not sticked together externally with a handover wired as a part of the package.
Context window
The context window grew from 128K (Nano V2 VL) to 256K.
Max Audio input is 1200 seconds.
For square images, the vision encoder scales from 512x512 up to 1840x1840 with anywhere from 1,024 to 13,312 patches per image.
On-paper this is pretty good for most of the day-to-day work.
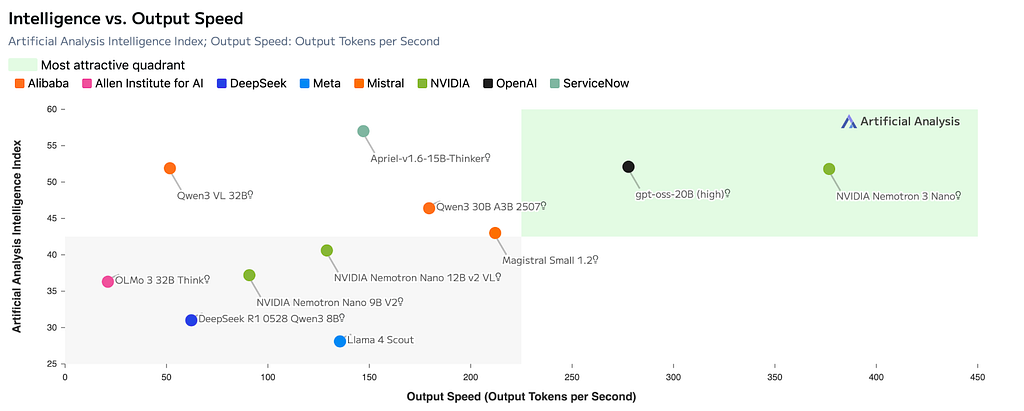
What the numbers actually say
The benchmakrs speak for themselves. Nano Omni has really broken through the ceiling.

Nemotron tops every document and GUI benchmark vs its own predecessor, beats Qwen3-Omni outright on MMLongBench-Doc (57.5 vs 49.5), CharXiv (63.6 vs 61.1), OSWorld (47.4 vs 29.0), Video-MME (72.2 vs 70.5), WorldSense, DailyOmni, VoiceBench, and ASR. Loses by 1.9 points on ScreenSpot-Pro. That’s the whole comparison.

OSWorld 11 to 47
OSWorld jumped from 11.0 (Nano V2 VL) to 47.4. OSWorld measures whether an agent can actually complete real desktop tasks in a sandboxed Ubuntu image; clicking through, filling forms, opening apps, finishing the job.
A 36-point gain there is the difference between “cute demo” and this could automate the IT helpdesk. Qwen3-Omni sits at 29.0. So Nemotron is roughly 18 points ahead of the closest open competitor on the benchmark that maps most cleanly to actual computer use.
MMLongBench-Doc 38 to 57
MMLongBench-Doc went from 38.0 to 57.5. That’s the long-document benchmark where the model has to find evidence buried 80 pages in and reason across multiple pages to answer one question. A 19.5-point bump means a lot of “the model lost track around page 40” failures just stopped happening.
ASR at 5.95 WER
Anyone who deals with various accents or patients or consumer in general, knows this really well. If you dont control the vocabulary then your ASR matters a lot.
A general ASR at 5.95 word error rate beats Qwen3-Omni’s 6.55. Half a point doesn’t sound dramatic until you remember that’s a 9% relative reduction on transcripts that already sit close to the human floor. For long meetings with overlapping speakers, that’s the difference between usable notes and “wait, who said that.”
The efficiency and consumer GPU fitness
Here’s the part that matters for anyone deploying this.
Up to 9x higher throughput vs other open omni models at the same per-user interactivity. 2.9x single-stream reasoning speed.
7.4x system efficiency on multi-document workloads. 9.2x on video. Hybrid Mamba + Transformer is doing real work here.
Mamba layers handle the long sequence cheaply; attention layers preserve global expressivity; MoE keeps active params at 3B even though you have 30B total. For inference, that means you’re paying for a 3B model’s worth of compute per token while getting reasoning quality of a much larger dense model.
The memory math, in plain terms
The memory math is friendlier than you’d expect. NVFP4 lands around 18B-equivalent footprint, which fits on a 24GB consumer card. FP8 is roughly 30GB. BF16 is the usual ~60GB.
So if you have a 4090 in a tower under your desk, NVFP4 is the realistic path. If you have an A100 80GB, FP8 is comfortable. If you have an H100 cluster, do whatever you want.
NVIDIA lists five intended use cases.
- long document analysis (100+ pages)
- automatic speech recognition
- long audio-video understanding
- agentic computer use
- and general multimodal reasoning.
Look at the OSWorld and ScreenSpot-Pro numbers and the priority becomes obvious. This is a screen-and-document agent first; the audio and video are real but secondary. Now, imagine this AI model being used for your private document understanding. One single model is able to handle audio, video, that is your notes or voice notes and also the long documents that you would likely use for reference.
It is not as fast as any dedicated, recurrent neural network based OCR model, it’s never going to be, but, it will generate the markdown format, that most of us need, whether we want to manage our memories in obsidian or somewhere else.
Imagine a mid-size legal team.
Three associates, one partner, a 240-page acquisition agreement, a deposition video of 90 minutes, and a stack of scanned exhibits. Today they spend two billable days extracting “what did the seller represent about IP indemnity on page 187, and does the deposition contradict that.”
A vLLM endpoint of Nano Omni handles the whole document at 256K context, listens to the deposition, cross-references the timestamp where the seller’s CTO said “we own all the source code,” and surfaces the contradiction with citations.
The agentic computer use
If it can, understand, what is, on the image, then, it can definitely understand, what is on the screen, as long as there is enough, fine-tuning done, on, how to work with the computers, this model was going to be a serious contender, for the computer use, the agentoc computer use.
This update is I am most intersted in (especially to control my parent’s computer). The OSWorld jump from 11 to 47 is buried in the launch post but it is the single most consequential number in the release.
The model is trained to interpret screenshots, monitor UI state, ground reasoning in on-screen visuals, and pick actions, with a built-in protocol that emits pyautogui code or structured tool calls like computer.wait and computer.terminate.
Successfully found the Driver License Eligibility Requirements page on the Virginia DMV website. The page contains comprehensive information about driver license eligibility including:
**General Requirements:**
- Must be a resident of the Commonwealth of Virginia
- Must be at least 16 years and 3 months of age
**First Time Drivers:**
- Must complete a state-approved driver education program
- Must obtain a learner's permit at least 60 days before taking the road skills test
- Must be at least 15 years and 6 months of age for a learner's permit
- No exceptions to age requirements
**New Residents:**
- Temporary residents: must obtain license within 6 months
- Permanent residents: must obtain license within 1 year
**Military Personnel:**
- Active-duty members of the Armed Forces stationed in Virginia
- Spouses and dependents 16 years and 3 months or older may drive with valid out-of-state license
- If vehicle is co-owned and out-of-state plates are used, all co-owners must be active duty members
**Out-of-State Students:**
- Full-time students enrolled in accredited Virginia schools (not employed) may drive with valid out-of-state license
- Full-time students who are employed are considered Virginia residents for vehicle laws
**Non-Residents:**
- Non-residents temporarily living in Virginia may drive with home state license for no more than 6 months
- Note: This does not apply to commercial vehicle drivers
- If becoming gainfully employed, must hold Virginia driver's license
**Identification and Residency Requirements:**
- Proof of identity (acceptable documents listed in DMV 141)
- Proof of legal presence in the U.S.
- Proof of Virginia residency
- Proof of Social Security number
- Proof of name change (if applicable)
Additional resources available: interactive document guide, "Acceptable Documents for Obtaining a Driver's License or Photo ID Card" (DMV 141), and Spanish language version.
The HuggingFace blog walks through one example where the model navigates the Virginia DMV website to find driver license eligibility requirements, clicks through three menus, scrolls, and produces a structured summary.
RL did the heavy lifting on reliability
The post-SFT stage uses NeMo-RL on a Ray-based distributed setup across B200 and H100 clusters, with multimodal deduplication so repeated rollouts don’t blow up image, video, and audio memory.
The detail that caught my eye is this one —
The verifier suite intentionally includes unanswerable cases to teach the model to abstain when evidence is insufficient.
When dealing with regulated industries, I have to deal with missingness quite a bit, and whenever a large language model sees missingness, it loves to gracefully fill something by confapulating or hallucinating some content to fill the gap. This training of abstention as a verifiable behavior with recurrent learning is an absolutely fantastic move, especially if it holds up under adversarial document corpus that I intend to test it with.
Tutorials and demos worth your time
NVIDIA shipped this with the most complete cookbook surface I’ve seen for an open release. The docs are not an afterthought. If you’re trying to actually run this thing, here is what to grab.
This could likely be the most useful part for future reference (bookmark the article)

Official NVIDIA cookbooks
- vLLM cookbook notebook walks you through serving the model via vLLM with audio support, FP8/NVFP4 quantization, reasoning parser, and tool-call parser configs: https://github.com/NVIDIA-NeMo/Nemotron/blob/main/usage-cookbook/Nemotron-3-Nano-Omni/vllm_cookbook.ipynb
- SGLang cookbook for high-throughput serving: https://github.com/NVIDIA-NeMo/Nemotron/blob/main/usage-cookbook/Nemotron-3-Nano-Omni/sglang_cookbook.ipynb
- TensorRT-LLM cookbook for optimized NVIDIA-stack inference: https://github.com/NVIDIA-NeMo/Nemotron/blob/main/usage-cookbook/Nemotron-3-Nano-Omni/trtllm_cookbook.ipynb
- Megatron-Bridge LoRA fine-tuning examples (the cord_v2 walkthrough is the one I’d start with): https://github.com/NVIDIA-NeMo/Nemotron/tree/main/usage-cookbook/Nemotron-3-Nano-Omni/Megatron-bridge
- NeMo-RL guide for running RL on the omni model: https://github.com/NVIDIA-NeMo/RL/blob/nano-v3-omni/docs/guides/nemotron-3-nano-omni.md
Community tutorials
- vLLM team’s official integration writeup: https://vllm.ai/blog/nemotron-omni
- Build Fast With AI’s full review with run-it-yourself steps via Unsloth and llama.cpp: https://www.buildfastwithai.com/blogs/nvidia-nemotron-3-nano-omni-2026
- Unsloth’s local inference and fine-tuning guide (NVFP4 GGUF on a 4090 path; do not use CUDA 13.2 for now, there’s a known gibberish-output bug NVIDIA is still patching): https://unsloth.ai/docs/models/nemotron-3-nano-omni
- Unsloth Colab notebook for the 30B model on an A100: https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Nemotron-3-Nano-30B-A3B_A100.ipynb
Hosted playgrounds (no GPU, no setup)
- fal.ai for one-click multimodal inference: https://fal.ai/nemotron
- LM Studio for one-click local on Mac/Windows/Linux: https://lmstudio.ai/models/nemotron-3-omni
- AWS SageMaker JumpStart deployment guide: https://aws.amazon.com/blogs/machine-learning/nvidia-nemotron-3-nano-omni-model-now-available-on-amazon-sagemaker-jumpstart/
- Crusoe Managed Inference: https://www.crusoe.ai/resources/blog/nvidia-nemotron-3-nano-omni-now-available
If you want the full data pipeline story, NeMo Data Designer ships with nine runnable recipes for VLM long-document SDG: https://github.com/NVIDIA-NeMo/DataDesigner/tree/main/docs/assets/recipes/vlm_long_doc
That recipe set deserves its own breakdown. Another time.
Closing thoughts
I cannot tell from the report whether the EVS token-pruning behavior holds up under adversarial video where every frame is genuinely different. Probably it falls back to keeping more tokens. The throughput numbers in that worst case are not in the report. Worth testing. Its not described or mentioned. So I guess one more tutorial in the future? !
Anyway..
If you are building anything that touches PDFs at scale, screen recordings, meeting captures, or GUI automation, you should be running this on a vLLM endpoint by next week and comparing it against whatever you currently use.
Especially if you were playing with Qwen VL Omni then please try this one and let me know how your experience was. I am going to have to finally bite the bullet and get GB10 chip machine. The cost gap, especially with NVFP4, makes the comparison cheap. The capability gap is the part that will surprise you.
If you have read it until this point, Thank you! You are a hero (and a Nerd ❤)! please don’t forget to 🔔 clap | follow | Subscribe 🔔
Nemotron 3 Nano Omni Could Be The Most Useful Model For Private AI was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.


