MiniMax teases M3 model with 15.6x faster decoding speed boost
The Shanghai-based AI firm's upcoming sparse attention architecture promises dramatic efficiency gains that could ripple through decentralized inference and crypto-native AI projects.
Share
Add us on Google by Editorial Team May. 27, 2026MiniMax, the Shanghai-based AI lab backed by Tencent, Alibaba, and miHoYo, just dropped a technical report on its M2 model series. Buried inside was a tease of its next-generation M3 model, which the company claims achieves a 15.6x faster decoding speed and 9.7x faster prefill speed compared to M2 when processing 1M-token contexts.
What MiniMax actually built
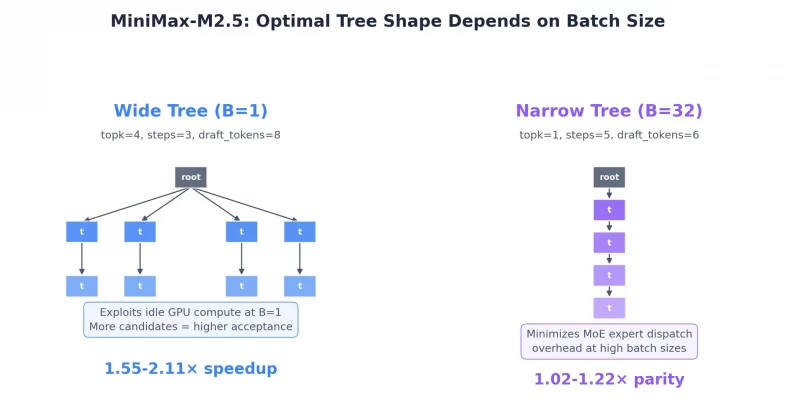
The secret sauce behind the M3 teaser is something MiniMax calls MiniMax Sparse Attention, or MSA. It’s built on a technique called GQA-driven dynamic block selection. Instead of having the model pay attention to every single piece of information in a massive context window, MSA intelligently picks which blocks of data actually matter for a given query. The result is dramatically less compute for roughly the same quality of output.
MiniMax claims the M3 model maintains output quality comparable to M2 despite these massive speed improvements.
The technical report itself covers the engineering innovations across the entire M2 lineup: M2, M2.5, and M2.7.
AdvertisementWorth noting: no confirmed parameter count, licensing details, or release timeline for M3 has been provided yet.
MiniMax’s growing footprint
Founded in early 2022, MiniMax listed on the Hong Kong Stock Exchange in January 2026. Its backers, Tencent, Alibaba, and miHoYo (the studio behind Genshin Impact), represent a cross-section of China’s tech and gaming elite.
Beyond text and code, MiniMax operates the Hailuo platform for video generation. Hailuo 2.3, the latest iteration, has processed billions of results according to the company.
Why crypto and AI investors should pay attention
Decentralized inference networks are perpetually bottlenecked by latency and cost. If MSA’s efficiency gains translate to smaller resource footprints per query, node operators could serve more requests without upgrading their rigs.
Crypto-native AI agents that monitor on-chain data, execute trades, or analyze smart contracts in real time are similarly constrained by how fast their underlying models can process information. A model that handles 1M-token contexts at nearly 16x the previous speed opens up use cases that were previously impractical.
No direct integrations between MiniMax’s technology and any blockchain platform or digital token have been confirmed. The connection between faster AI models and crypto applications remains a logical inference, not a product announcement.
For investors in the decentralized AI space, the key metric to watch isn’t M3’s release date. It’s whether the MSA architecture gets open-sourced alongside the model weights. If MiniMax follows its established pattern of permissive licensing, every decentralized inference project on the planet gets a free upgrade to their efficiency playbook. If the company keeps MSA proprietary, the competitive advantage stays centralized in Shanghai.
Disclosure: This article was edited by Editorial Team. For more information on how we create and review content, see our Editorial Policy.