From Transaction Graph to Agentic Identity: How PayPal Is Rebuilding the Stack for Agentic Commerce
--
Three intersecting shifts — a payments foundation model, a verified identity substrate, and the agentic commerce layer — and what they look like when they ship together at the scale of 25B+ transactions.
1. The Failure Mode
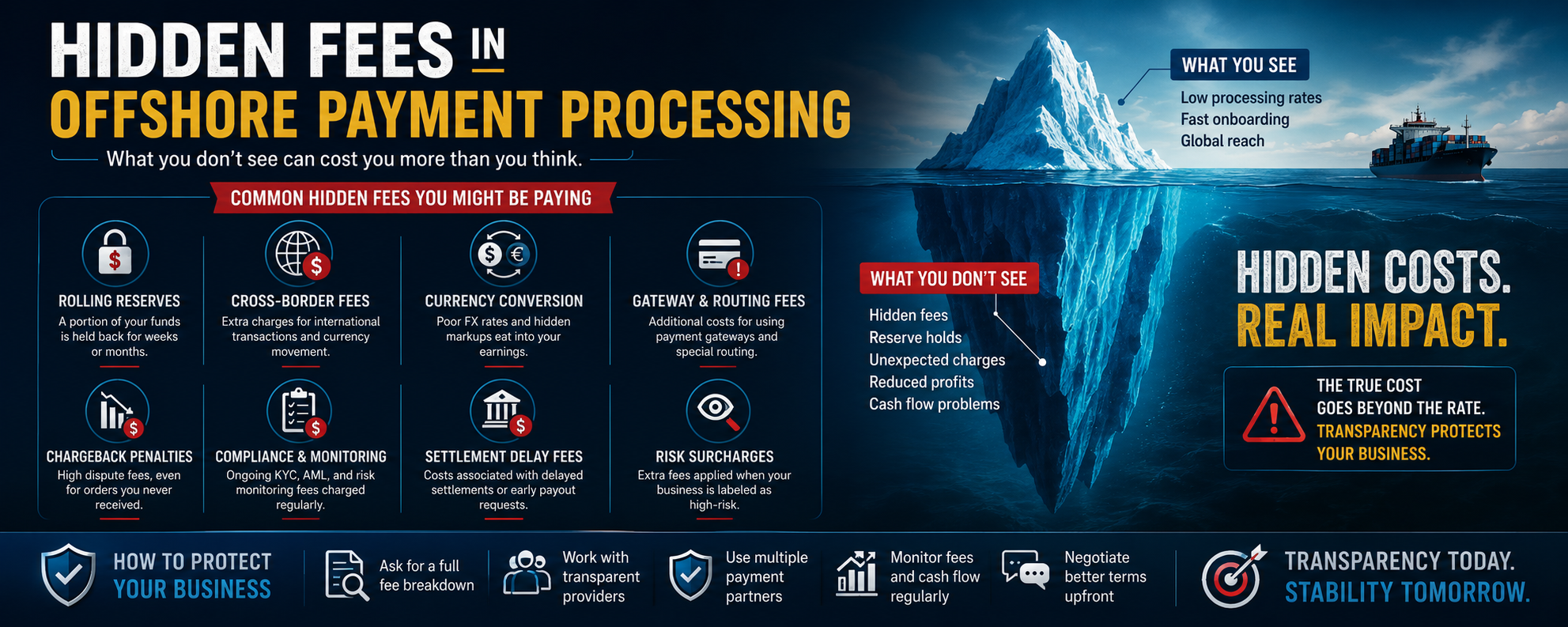
The most quoted number in the 2025 State of the Industry report is that only 21% of brands, agencies, and publishers say they are very confident they can accurately identify and reach their target audiences across digital channels. Read that twice. Four out of five of the people whose entire job is reaching audiences are not confident they can reach audiences.
This is not a marketing problem. It is an identity infrastructure problem that has been hiding under a marketing surface for fifteen years.
Cookies are deprecating with no real successor. The top identity graphs — RampID, Unified ID 2.0, ConnectID — are still largely cookie-derived at the source layer, hashed and stitched and re-presented as if the substrate had changed. Probabilistic graphs degrade at the point of activation, which is precisely where money changes hands. Device IDs fragment across platforms. IP addresses are unstable by design. None of this is news inside ad tech. What is new is that the failure compounds.
Agentic systems are arriving into this broken identity layer. Agents transact on behalf of users. Agents accept delegated authority. Agents move money. And the identity layer they are arriving onto cannot reliably tell one human from another, let alone one human-delegated agent from another. Visa reported hundreds of agent-initiated transactions completing in live production in late 2025 and expects millions by holiday 2026. Mastercard rolled out Agent Pay to all US cardholders in November 2025. The volume is no longer theoretical. The identity layer it runs on is.
Underneath the identity problem sits a related ML failure mode. The financial industry has built specialized machine learning models for individual tasks — fraud detection, authorization optimization, dispute resolution, churn prediction — for two decades. Each model has its own feature engineering, its own retraining cadence, its own production system, its own audit trail. The marginal cost of adding a new model is high. The shared substrate underneath those models has been mostly absent.
This is the moment the underlying data — verified, sequenced, multi-merchant transaction histories — stopped being a database query and started being the substrate for a foundation model. Stripe announced its Payments Foundation Model in May 2025, trained on tens of billions of transactions, and reported a 64% improvement in attack detection rate on large businesses practically overnight. Revolut shipped PRAGMA in early 2026. PayPal has been assembling the same architecture under the Transaction Graph framing across late 2025 and 2026.
Three things are happening at once. Cookies are dying. Agents are arriving. Foundation models are eating the per-task ML stack from underneath. Anyone trying to solve any of these problems in isolation is solving the wrong problem.
The piece that follows is one operator’s take on how those three shifts converge — what they look like when they ship together, what they fail to do today, and what comes next. It is grounded in what PayPal has been building, but the structural argument applies anywhere there is a verified transaction graph of meaningful scale. The destinations are advertising, commerce, and identity. The substrate underneath them is the same.
2. Three Domains, One Substrate
The conventional view is that advertising technology, commerce platforms, and identity systems are three different engineering stacks. Different vendors, different protocols, different data models, different teams. A retail media network is not a payment gateway is not an identity graph is not an attribution pipeline.
This view is wrong, or more precisely, it is about to be wrong.
The structural argument of this piece is that all three stacks resolve to the same underlying data — verified, sequenced, multi-party transaction events — and that AI does not transform them as three separate problems. AI collapses them onto a single substrate. The substrate is the transaction graph. The reasoning layer above it is the payments foundation model. The output layer that ships to advertisers, merchants, agents, and consumers is the identity primitive.
There is a clean reason this convergence has not happened until now. The transaction data was sitting in payment networks that treated it as operational data, not training data. PayPal, Stripe, Visa, Mastercard, Block, Adyen — every payment company has been processing transactions for decades. Almost none of them was treating those transactions as the input to a foundation model until 2024 and 2025. The data sat. The substrate was always there. The architecture to use it was not.
What changed is the architecture, not the data. Transformer-based foundation models work on transactions for the same reason they work on language. Transactions form sequences. Sequences have temporal structure, contextual dependencies, latent regularities. A merchant code is a token. A timestamp is a position. A counterparty is a relationship. A 24-month transaction history is a corpus.
Once that substrate exists and reasons over sequences, it changes what every downstream surface can do. An advertiser stops asking “is this user likely to buy something” and starts asking “where in this user’s transaction sequence is this purchase, and what does the sequence say about intent.” A merchant stops asking “is this agent legitimate” and starts asking “is this agent operating within the mandate this user previously authorized, and does the requested transaction match the user’s sequence.” An identity system stops asking “is this device the same as the device we saw yesterday” and starts asking “does this account-level behavior match the account we have authenticated.”
These three downstream questions have been treated as separate problems for years because the data underneath them was separated by org charts, vendor boundaries, and data residency rules. The data was never actually separated by nature.
The rest of this piece walks the stack. First the graph, then the foundation model, then the identity primitive that comes out of it. Then the three application domains — advertising, commerce, identity for agents — that get rebuilt on top. Then the production-realism layers most pieces in this space skip: cost structure, regulatory frame, competitive map. Then forward-looking use cases and business impact. Then the close.
Architecture first. The applications come out of it.
3. The Transaction Graph as Data Foundation
PayPal’s Transaction Graph aggregates commerce and engagement signals across PayPal and Venmo — 25 billion plus transactions across 430 million plus consumer accounts across tens of millions of merchants. The publicly disclosed coverage works out to roughly 30 percent of global purchase volume, per PPC Land’s analysis. That last number is the one to hold in mind because it distinguishes the substrate from every retail media network in the market.
A retail media network like Amazon Ads or Walmart Connect sees purchases that happen inside its own ecosystem. The view is vertical and deep but narrow. A payment network sees purchases across millions of merchants but historically did not retain the cross-merchant relationships at training-data resolution. The Transaction Graph is the first architecture to treat that cross-merchant view as a first-class data asset rather than operational metadata.
What the graph actually is, from the ML side, is a multi-relational temporal graph. Nodes include consumers, merchants, devices, payment instruments, and increasingly delegated agents. Edges include transactions, settlements, disputes, refunds, peer-to-peer transfers, savings and rewards events, and Venmo social interactions. Each edge carries time, amount, geography, merchant category, payment method, fraud signal, dispute outcome, and a long tail of contextual metadata. The graph is updated in near real time and is queried at two latencies: training-time batch for foundation model pretraining, and impression-time online for production inference.
The ML problems underneath the graph are not exotic individually. They are exotic in combination at this scale.
Entity resolution is the first one. A consumer with a PayPal account, a Venmo account, multiple devices, a primary card on file, and a secondary card might appear as five entities to a naive system and as one entity to the graph. Resolving them requires sequence-aware matching against transaction patterns, device fingerprints used carefully given regulatory constraints, and authenticated cross-product behaviors. The matching has to be conservative — false merges in an identity system are catastrophic — and it has to operate at hundreds of millions of accounts.
Representation learning is the second. Sparse, heterogeneous transaction sequences have to map into dense embeddings that preserve temporal order, contextual structure, and behavioral signal. The TREASURE paper from KDD 2026 — A Transformer-Based Foundation Model for High-Volume Transaction Understanding — frames this problem cleanly: the unit of representation is not a row but a sequence, and the embedding has to support multiple downstream tasks without retraining from scratch.
Privacy-preserving aggregation is the third. Encryption in transit and at rest is the table stakes. The real work is engineering aggregation pipelines that allow product surfaces — Ads ID, Insights and Measurement — to use the embedded signal without exposing underlying transactions. PayPal’s public framing describes the identifier as individually encrypted, aggregated, and deidentified. That phrasing describes a multi-layer pipeline where the downstream consumer of the signal never has access to the upstream data. Architecturally this means secure enclaves, differential privacy budgets, and aggregation thresholds.
Real-time inference is the fourth. Programmatic ad auctions resolve in 100 milliseconds end to end. Agent-initiated transactions need verification at the same scale. The model that took weeks to pretrain has to serve embeddings at single-digit milliseconds at the production edge.
These four problems are not new individually. None of the four becomes manageable until you have a substrate sized like the Transaction Graph and a team that has solved them in production rather than in a paper. The product surfaces — Transaction Graph Insights and Measurement, PayPal Ads ID, the AI risk and fraud systems — are the result of all four converging.
The substrate is the unsexy part. It is also the part that determines whether everything above it works.
4. The Payments Foundation Model
The thing that is genuinely new in payments AI in 2025 and 2026 is not the data and is not the agents. It is the foundation model trained on the data.
The conventional payments ML stack is task-specific. A fraud model. An authorization optimization model. A dispute prediction model. A churn model. A merchant risk model. Each one is its own feature engineering pipeline, its own training cadence, its own production system, its own audit trail. The marginal cost of adding a new task is the cost of building a new model. The shared substrate underneath the models is, in most companies, nothing more sophisticated than a data warehouse.
A payments foundation model inverts this. Pretrain a single transformer on tens of billions of transactions with a self-supervised objective. Produce dense embeddings — typically hundreds of dimensions per transaction or per user — that capture the structure of how money moves. Use those embeddings as the input layer for any downstream task. The downstream tasks become small fine-tunes or even zero-shot classifications against the foundation embeddings. The marginal cost of a new task collapses.
Stripe announced its Payments Foundation Model in May 2025 at Stripe Sessions, trained on tens of billions of transactions across roughly $1.4 trillion in annual payment volume. The publicly reported result that matters most: a 64 percent improvement in card-testing attack detection on large businesses, achieved practically overnight after deploying the foundation model. Stripe’s head of data and AI Emily Sands described the operational consequence on the Cognitive Revolution podcast: once you have a shared embedding, spinning up a new model becomes a weekend project rather than a quarter project.
Revolut followed in early 2026 with PRAGMA, a foundation model designed for consumer finance. The PRAGMA paper explicitly situates itself against the prior work — nuFormer focused on product recommendation, TransactionGPT on anomaly detection and trajectory generation — and argues that the next generation of these models needs to fuse tokenized transaction sequences with static profile state and serve multiple tasks rather than one. The architectural critique is the right one. First-generation payments foundation models were single-purpose. Second-generation models — and PayPal’s framing of the Transaction Graph implies it sits in the second generation — are multi-task by design.
What does a payments foundation model actually look like architecturally? The tokenization layer is the first interesting question. A transaction is not a word. Each event carries categorical features (merchant, MCC, payment instrument, geography, payment method), numerical features (amount, time delta, recency), and identity features (counterparty, device, account). A hybrid tokenization strategy maps categorical features to learned embeddings, bins or normalizes numerical features, and concatenates them into a per-transaction token vector. A sequence of transactions becomes a sequence of token vectors, and the transformer learns the structure across positions.
The pretraining objective is the second. Next-transaction prediction works for many use cases — given the last 50 transactions, predict the next one. Masked transaction modeling, analogous to BERT, works for others. Sequence-level contrastive learning works for entity resolution and behavioral clustering. Production systems typically use a combination.
The merchant tokenization problem is the part the Enhancing Foundation Models in Transaction Understanding paper pinpoints sharply. Mapping “Costco” to a learned index loses everything that “Costco” actually means — wholesale, membership-based, bulk purchasing, household-level frequency. LLM-derived semantic embeddings of merchant names give the model a richer prior than learned indices alone. The architectural detail matters because the bulk of behavioral signal in a transaction graph lives in the merchant axis, and treating merchants as opaque indices throws away most of the signal you actually have.
Production constraints shape the architecture as much as research constraints. The model has to serve embeddings at programmatic latency — single-digit milliseconds at the edge — which means KV cache reuse across decisions for the same user, careful management of the decode tax in multi-step inference loops, and quantization or distillation for inference cost control. The fraction of cost in inference rather than training, for any production foundation model, is typically 70 to 90 percent. The architecture choices that look academic at the pretraining stage are economic choices at the production stage.
There is a regulatory layer that has to be co-designed with the architecture. SR 11–7 model risk management applies the moment the foundation model is making credit, fraud, or eligibility decisions, which is from the first deployed task. EU AI Act high-risk classifications apply to biometric and identity systems built on top of the embeddings. PCI DSS controls govern any system touching payment data. None of these are added at the end of the design cycle. They are constraints that shape the training data, the inference pipeline, the explainability layer, and the audit trail from day one.
The economics of a payments foundation model are also genuinely different from the economics of a per-task ML stack. The pretraining cost is large and one-time-ish — refreshed quarterly or semi-annually as new data accumulates. The inference cost is amortized across every downstream task that uses the embeddings. The cost per new use case is the fine-tune plus the marginal inference, not the full model retrain. Over a horizon of 8 to 12 use cases, the total cost is materially lower than running 8 to 12 separate task-specific stacks. Below that horizon, the foundation model approach is more expensive. The breakeven point is the strategic decision.
PayPal’s positioning around the Transaction Graph suggests the model is in production and is increasingly the substrate for the AI surface — ads, identity, fraud, merchant insights — rather than a separate ML system. The public framing has been more product-led than architecture-led, which is appropriate for the audiences PayPal Ads is selling to. The architecture is the part that matters in the longer run.
5. Identity as the Output of the Stack
PayPal Ads ID is the most visible externalization of the substrate, but it is not the substrate itself. This distinction matters because most public commentary treats Ads ID as the product. It is not. It is one output of the architecture that sits underneath.
The architecture, in the order it actually runs, is: Transaction Graph (the substrate) → Payments Foundation Model (the reasoning layer) → embeddings (the shared representation) → application-specific surfaces (the products). Ads ID is one application-specific surface. The same substrate and reasoning layer also produce fraud signals, dispute predictions, merchant risk scores, and increasingly the verified identity primitives that agentic commerce needs.
What makes Ads ID structurally different from probabilistic identity graphs is the layer it is built on. Cookie-based identity graphs derive identity from browsing artifacts — third-party cookies, device fingerprints, IP addresses, hashed emails stitched across consortia. The signal is inferred, the inference is brittle across browsers and devices, and the inference quality degrades exactly at activation. Transaction-graph identity is the inverse: identity is verified at point of purchase, persistent across sessions because the substrate is the account rather than the cookie, and the signal does not degrade when activated because activation is the same surface as authentication.
This is the verification-over-inference shift. It is the same shift cookieless advertising has been promising for half a decade and mostly failing to deliver. The reason transaction-graph identity actually delivers it is that the verification is upstream of the user’s interaction with media. The user verified themselves the last time they spent money. Every downstream signal is a function of that prior verification, not a guess about the user’s identity at impression time.
The privacy engineering that makes Ads ID shippable is more interesting than the marketing copy suggests. The identifier is individually encrypted at the user level. Aggregation thresholds prevent reconstruction of individual transactions from cohort-level statistics. Deidentification pipelines strip merchant names and transaction details before any signal leaves PayPal’s perimeter. Consumer controls give users explicit opt-out at the account level. The downstream consumer of the signal — Magnite, PubMatic, Rokt, Taboola in the launch cohort — gets the verified ID, not the underlying behavior.
This is the part most public discussion conflates. Verified identity is not surveillance. Surveillance is the unauthorized observation of behavior. Verified identity is the consented binding of an authenticated account to a media-facing identifier, with the underlying behavior never leaving the perimeter. The distinction is architectural, not rhetorical. The architecture is what makes the distinction defensible to regulators, advertisers, and consumers simultaneously.
The reason this matters beyond advertising is that the same identity primitive — verified at point of purchase, encrypted, aggregated, deidentified — is the primitive agentic commerce needs. When an agent transacts on a user’s behalf, the merchant needs to verify the user without the agent revealing the user’s full identity. The Ads ID architecture is one step away from being the Agent ID architecture. The technical work has already been done. The product surface for agents will look different, but the substrate is the same.
The identity layer is not the destination. It is the output of the substrate plus the model. The destination is what runs on top.
Show Image
Figure 1. The three-layer stack. The substrate is the unsexy part. It is also the part that determines whether everything above it works.
6. Advertising Transformed
The first domain. Advertising is the easiest one to explain because the failure mode is so visible.
Cookie deprecation has been announced, delayed, half-implemented, and announced again since 2020. The reason the industry has been able to absorb the uncertainty is that the substitutes have been mostly cookies wearing different costumes. Universal IDs from The Trade Desk, LiveRamp, Yahoo — the source signal is still largely a third-party cookie or a hashed email that came from a third-party cookie. The substrate did not change. The marketing did.
The Transaction Graph plus foundation model plus Ads ID changes the substrate. Closed-loop attribution stops being an inference and starts being a measurement. The identity layer and the transaction layer are the same layer, which means an advertiser can move from estimating whether an ad drove a purchase to observing whether it did. The economic consequence is a step-change in measurable ROAS. The downstream consequence is that advertiser budgets move toward surfaces where measurement is real and away from surfaces where it is implied.
The strategic logic of releasing the ID free to commercial partners is worth pausing on. PayPal is not in the business of selling identity. Charging CPMs or per-seat software fees on the ID would create a small revenue line and slow ecosystem adoption to a crawl. Releasing the ID free across Magnite, PubMatic, Rokt, and Taboola creates ecosystem adoption velocity and shifts the economics one layer down the stack — into the commerce relationships the identity enables. The ID is a public good for the ecosystem. The economics live in the transaction graph it points back to.
Position this against the alternatives. Retail media networks — Amazon Ads, Walmart Connect, Target Roundel — are vertical and ecosystem-locked. They see what happens inside their own ecosystem and lose visibility at the edge. Walled gardens — Google, Meta — are deep and broad but closed. Advertisers do not get to see what happens inside the wall, only the attribution claim the wall is willing to share. The Transaction Graph is horizontal across millions of merchants and the attribution is grounded in the same transaction the consumer actually made, not a model of what the consumer might have done.
What this unlocks at the campaign level is hard to capture in a paragraph but is genuinely structural. Audiences can be defined by sequence rather than snapshot — not just “lapsed customer” but “lapsed customer whose recent transactions suggest they are about to switch categories.” Match rates do not degrade at activation because the underlying account is the activation key. Frequency capping works across sessions and devices because the cap is bound to the account, not the cookie. Cross-device reach is the default rather than a feature.
The pricing transparency matters more than the campaign tactics. Free distribution of the ID changes who can use it. A mid-market advertiser running through PubMatic does not need to budget for a separate identity layer. The cost of using verified commerce identity drops from a line item to a feature. Mid-market and SMB advertisers, in aggregate, are larger than the enterprise budget pool. Lowering the floor on identity access is how you grow the category.
The transformation of advertising is the most legible of the three because the industry has been begging for this substrate for half a decade. The harder transformations are the next two.
7. Commerce Transformed
The second domain. This is the one where the substrate, the model, and the identity primitive start to compose into something the press releases have not fully described yet.
Commerce in 2026 is in the middle of a structural shift from human-mediated checkout to agent-mediated checkout. The agent is not a metaphor. Visa reported hundreds of agent-initiated transactions completing in live production environments in late 2025, with a stated expectation of millions of consumer-facing AI purchases by holiday 2026. Mastercard rolled out Agent Pay to all US cardholders in November 2025. OpenAI and Stripe co-built the Agentic Commerce Protocol and have it in live production for ChatGPT-mediated checkout. Google built AP2 with cryptographic mandates. Anthropic open-sourced MCP. The protocol layer is real.
PayPal’s positioning in this shift is structurally different from the protocol authors. PayPal does not need to invent the protocol because protocol-level work has been commoditizing fast. PayPal needs to be the institution agents settle through, because settlement requires merchant-of-record status, regulatory licenses, dispute resolution capacity, and consumer trust — none of which a protocol provides on its own.
The PayPal AI stack assembling around this shift includes Agent Ready (the commerce surface for agent-initiated transactions), the integration with OpenAI’s Agentic Commerce Protocol (live in production for ChatGPT shopping), and the PayPal MCP server (the tool layer agents call when they need PayPal’s capabilities). Each of these is a separate product surface. None of them works end-to-end without a verified, persistent, deterministic identity layer underneath. The identity layer is the Transaction Graph plus the foundation model plus the Ads-ID-style externalization rebuilt for agent verification.
The IMF Note on agentic payments described PayPal’s position as the “trust layer for the agentic web” — agents using PayPal’s transaction graph and secure vaults to facilitate settlement while PayPal maintains merchant-of-record status for the retailer. If that framing is accurate as a public characterization, it is structurally apt. The agent operates the user-facing intent layer. The merchant operates the supply-side fulfillment layer. PayPal operates the trust layer between them — verifying the agent, verifying the user mandate, settling the transaction, handling disputes when the agent does the wrong thing.
What this changes about commerce is the buyer surface. A merchant in the agent-mediated world no longer optimizes for a human clicking through a checkout page. The merchant optimizes for an agent reading a machine-readable catalog, comparing options against the user’s mandate, settling against a verified payment instrument, and providing a clean attribution trail. Static catalogs do not work. Demand-responsive pricing becomes a real-time API call. Composable merchant APIs become a hard requirement.
The supply side restructures because the demand side restructures. Merchants that were optimized for SEO and search-driven discovery have to also be optimized for agent discovery — exposed through MCP-style tool surfaces, indexed through agent-readable catalogs, queryable through standardized APIs like UCP and ACP. The merchants that have been investing in composable commerce since 2023 have a structural advantage in 2026. The merchants that have not will discover their search rank does not matter when the buyer is software.
The transformation of commerce is the one most underestimated in 2026 mainstream coverage. Advertising shifts are visible to anyone reading AdExchanger. Commerce shifts are happening at the merchant-API layer where the consumer never sees them. The cumulative effect over 24 months is larger than the visible advertising shift.
8. Identity for the Agentic Era
The third domain. The least developed, the most contested, the most strategically important.
When agents transact on behalf of users, two identities have to be verified simultaneously: the user who delegated the authority, and the agent that received it. The protocol landscape that has emerged in 2025 and 2026 addresses different parts of this problem with different mechanisms.
The Survey of Agent Interoperability Protocols paper maps the layers cleanly. MCP from Anthropic is the universal adapter — agents call tools and data through a JSON-RPC interface. A2A from Google is the inter-agent communication layer. ACP from OpenAI and Stripe handles checkout transactions. UCP from Google and Shopify handles the broader shopping journey. AP2 from Google handles payment authorization through cryptographic mandates. Visa’s Trusted Agent Protocol signs agent identity into HTTP headers. Mastercard’s Agentic Tokens encode agent identity into the transaction record.
No single protocol solves the full identity problem. They solve adjacent slices of it. The composability is the point — and also the failure mode.
The Zero-Trust Runtime Verification for Agentic Payment Protocols paper from eBay makes the failure-mode argument with surgical precision. AP2 provides specification-level guarantees through signature verification, explicit binding, and expiration semantics. Real-world agentic execution introduces retries, concurrency, and orchestration that challenge those implicit assumptions. The specification works on paper. The runtime is where the assumptions break. The paper proposes a zero-trust runtime verification layer that enforces context-binding and consume-once mandate semantics. The architectural point underneath it: protocol specs are necessary but not sufficient. The verification layer between protocol and production is its own engineering problem.
The SoK: Security of Autonomous LLM Agents in Agentic Commerce paper is sober about deployment status. ERC-8004 and ERC-8183 are Ethereum proposals in draft. AP2 is a research proposal with no widely adopted reference implementation. x402 has early adopter deployment by Coinbase. MPP from Stripe and Tempo has a live mainnet deployment and is the most operationally mature. ACP is deployed on Virtuals Protocol’s platform. The protocols are real. The interoperability between them is still mostly aspirational.
This is where PayPal’s transaction graph identity primitive becomes structurally important. The protocols are layered on top of the identity layer, not under it. A transaction graph that can deterministically verify the user account, persistently track agent delegations against that account, and provide a cryptographic attestation of “this user authorized this agent for this scope” is the substrate the protocols need. None of the protocols solve the substrate problem. They presume a substrate exists.
The four criteria the agentic identity layer has to satisfy are concrete.
The first is clustering preferences across real economic behavior rather than browsing artifacts. The transaction graph and the foundation model embeddings give the substrate to do this. Probabilistic graphs cannot.
The second is attributing outcomes back to a verified entity. The deterministic account-level verification at point of purchase is the only architecture that gives merchants an attributable counterparty when the buyer is software.
The third is defending against synthetic identity attacks at agent scale. Synthetic identity is already a meaningful fraction of payment fraud. Agent-scale automation will increase it by orders of magnitude. The substrate that can verify identity from historical transaction patterns rather than registration artifacts is the only substrate that can defend against this.
The fourth is surviving the collapse of cookie-based reach as agents bypass conventional ad surfaces. When the agent does the shopping, the cookie was never going to be on the device anyway. Cookie-derived identity was already dying. Agent-mediated commerce kills it operationally.
Identity for the agentic era is not a feature on top of advertising identity. It is the substrate everything else runs on. The institutions that hold transaction graphs are the institutions positioned to provide it. PayPal is one of those institutions. So are Stripe, Block, Adyen, Visa, Mastercard. The competitive question is not who has the data. The competitive question is who builds the substrate-plus-model-plus-identity-primitive stack fastest.
Show Image
Figure 2. Agentic identity verification flow. Each step in the sequence has a corresponding failure mode if the verified substrate is absent. Protocols cover authorization semantics; the substrate covers verification.
9. The TCO Reality
The cost structure of this stack is the part most analysis quietly avoids. The numbers in production are not the numbers in pretraining decks.
Pretraining a payments foundation model on tens of billions of transactions costs in the high seven figures to low eight figures depending on the architecture, compute pricing, and team scale. The training cost is not the binding constraint. The binding constraint is the inference economics over the model’s production life.
For a foundation model serving multiple downstream tasks at production scale, inference cost typically runs 70 to 90 percent of total ML spend. Every embedding lookup, every fine-tuned task head, every agent-mediated transaction that calls the model accumulates. The KV cache management, decode tax in multi-step inference loops, and quantization choices that look academic at training time are economic choices at production time. Decisions about cache reuse policy, sequence length truncation, and quantization precision are decisions about whether the unit economics work.
Agentic inference is where the cost curve gets worst. A single human-initiated transaction is one inference call. A single agent-initiated transaction is typically 5 to 20 inference calls — for intent verification, mandate checking, fraud scoring, merchant verification, payment authorization, post-transaction logging. Each call accumulates tokens against the foundation model. The O(n²) accumulation in long agentic loops is real, not theoretical. The cost per dollar of GMV at agentic scale, without careful inference architecture, runs 5 to 10 times higher than the cost per dollar at human-mediated scale.
Human escalation is the underestimated cost line. When an agent encounters an ambiguous transaction — a fraud-flagged purchase, a disputed return, a permission conflict — the resolution path goes to a human reviewer. Human review at agent scale, even at a 0.1 percent escalation rate, is a meaningful headcount line. Most enterprise AI TCO models underestimate this by 5 to 100 times.
Compliance overhead is not a footnote. SR 11–7 model risk management requires documented validation, ongoing monitoring, and periodic re-validation for every model making credit, fraud, or eligibility decisions. The foundation model approach concentrates this overhead — instead of validating 12 task-specific models, you validate one substrate model plus the task-specific fine-tunes — but the absolute overhead is non-trivial. A typical SR 11–7 validation cycle for a high-criticality model runs 6 to 18 months of cross-functional work.
EU AI Act high-risk system compliance overlays additional requirements: technical documentation, human oversight provisions, transparency obligations, post-market monitoring. The compliance line on a regulated-industry AI deployment is in the high single-digit to low double-digit percentage of total program cost. This is not optional and it does not scale with usage in the way pure infrastructure scales.
The reason the TCO matters for the argument of this piece is that the foundation model approach is not unambiguously cheaper than the per-task ML stack. It is cheaper over a portfolio of 8 to 12 production use cases. Below that portfolio breakeven, it is more expensive. Above it, the marginal cost of each new use case collapses toward the cost of a fine-tune plus inference, and the strategic flywheel that compounds with each new use case starts to dominate.
The strategic choice to invest in the foundation model architecture is a bet on use case breadth. PayPal is making that bet across advertising, identity, fraud, commerce, agent-mediated transactions, and dispute resolution. Stripe is making it across payment optimization, fraud, and dispute prediction. Revolut is making it across consumer finance broadly. The cost structure works for institutions with use case breadth and does not work for institutions trying to apply foundation models to single tasks.
Production realism is not a side comment. It is the difference between an architecture that ships and an architecture that demos.
10. The Regulatory Frame
Every architectural decision in the stack above intersects with at least one regulatory regime. The institutions that treat these as constraints applied at the end of the design cycle ship architectures that have to be rebuilt eighteen months later. The institutions that co-design with the regulatory frame from day one ship architectures that survive examination.
SR 11–7 is the foundational framework for US banks. It governs model risk management — how models are developed, validated, monitored, and retired. The payments foundation model approach concentrates model risk into a smaller number of models with broader scope, which simplifies SR 11–7 governance in some ways and complicates it in others. The foundation model itself is one model under one validation regime, but each fine-tuned task that uses its embeddings inherits a portion of the foundation model’s risk profile. Documentation of lineage from foundation model to task model becomes critical. The audit trail has to follow the embedding from training to production decision.
The EU AI Act classifies certain systems as high-risk based on their use, not their architecture. Biometric identification, credit scoring, fraud assessment for credit decisions, and increasingly identity verification at consumer scale are all candidate high-risk classifications. Once classified high-risk, systems require technical documentation, conformity assessment, human oversight provisions, transparency obligations to data subjects, and post-market monitoring. The compliance overhead is substantial and ongoing. Architectures that bake explainability, audit trail, and human-in-the-loop affordances in from the substrate level handle this more cheaply than architectures that bolt them on at the application layer.
PCI DSS governs systems that touch payment card data. Every layer of the transaction graph that ingests, stores, or processes cardholder data falls under PCI DSS controls. The privacy engineering described earlier — encryption, aggregation, deidentification, secure enclaves — is partly an SR 11–7 requirement, partly a PCI DSS requirement, partly a GDPR/CCPA requirement, and partly an EU AI Act requirement. The architecture that satisfies all four simultaneously is the only architecture worth shipping.
DORA — the EU Digital Operational Resilience Act — adds operational resilience requirements for financial services firms, including third-party risk management for AI systems built on foundation models trained on financial data. The provisions matter most when the foundation model is shared across business units or licensed externally. Resilience requirements drive architectural choices about model versioning, rollback, and incident response.
The Treasury Financial Services AI Risk Management Framework, issued in 2024, provides US-specific guidance on AI risk management in financial services. It aligns broadly with NIST’s AI Risk Management Framework but adds financial-services-specific risk categories. The framework is non-binding but is increasingly the reference for what supervisory expectation looks like.
The reason this section is in the middle of the piece rather than at the end is that regulatory frames are not the close — they are the constraint that shapes everything that came before. The architecture choices in sections 3 through 8 are not arbitrary engineering preferences. They are the architecture choices that survive SR 11–7, EU AI Act, PCI DSS, DORA, and the FS AI RMF simultaneously. The institutions that approach this stack from outside payments — the AI labs without a regulated business, the pure ad tech vendors, the protocol authors — will hit these constraints late and architecturally. The institutions that approach this stack from inside payments have been operating under these constraints for years.
Regulatory expertise is not a moat that gets celebrated in keynote announcements. It is the moat that is hardest to replicate.
11. The Fintech Category Move
Zoom out. PayPal is not alone in this architecture.
Every major payments network sits on a verified transaction graph of meaningful scale. Stripe processes roughly $1.4 trillion in annual payment volume. Visa and Mastercard process tens of trillions across their networks. Block sees the Cash App network plus Afterpay plus Square’s merchant base. Adyen sees the unified processing graph for thousands of enterprise merchants. The aggregate transaction graph held across the top six payment networks is most of global non-cash commerce.
The question is not who has the data. The question is who turns the data into the substrate-plus-model-plus-identity-primitive stack first, and who builds the agent-facing surfaces on top of it.
Stripe shipped its Payments Foundation Model in May 2025, with concrete production gains reported within months. Stripe co-built the Agentic Commerce Protocol with OpenAI and has it in live production. Stripe and Tempo co-authored the Merchant Payment Protocol with a live mainnet deployment. Stripe’s positioning is foundation model plus protocol leadership, optimized for the developer and SaaS commerce end of the market.
Visa launched Intelligent Commerce with 100-plus partners building against it, 30-plus in sandbox, and 20-plus agents integrating directly. Visa launched the Trusted Agent Protocol with Cloudflare in October 2025 to address agent identity at the network layer. Visa completed hundreds of secure agent-initiated transactions in December 2025. The positioning is network-level trust infrastructure, leveraging Visa’s existing rails and tokenization expertise.
Mastercard rolled out Agent Pay to all US cardholders in November 2025 and is integrated into Microsoft Copilot Checkout. Mastercard’s Agentic Tokens encode agent identity directly into the transaction record so disputes can attribute correctly. The positioning is consumer-facing reach at scale through the existing card network plus integration into the largest agent-facing surfaces.
Block has Cash App, Square, and Afterpay, with the buy-now-pay-later layer giving it a different shape of transaction graph. Block’s positioning has been less public on the foundation model side but the architectural pieces are present.
Adyen processes for the largest enterprise merchants in the world. The transaction graph is broad rather than deep across SMB the way PayPal’s is, and the customer-facing identity primitive does not exist in the same way because Adyen does not have a consumer-facing brand. The strategic answer for Adyen has historically been deep integration into enterprise merchant stacks rather than ecosystem distribution.
PayPal’s positioning is structurally different from each of these. The Transaction Graph is horizontal across millions of merchants — broader than retail media networks, broader than enterprise processors. Venmo adds a social commerce graph that no other major payment network has. The free-distribution play on Ads ID is a different distribution strategy than Visa’s network-fee model or Mastercard’s bundled-product model. The merchant-of-record positioning gives PayPal a different role in agentic commerce than a pure rails provider.
What this category move means in aggregate is that the next 24 months in payments AI are not about who has the data. They are about who turns the data into the production stack first, who builds the right agent-facing surfaces on top, and who navigates the regulatory frame without rebuilding in 18 months. The competitive dimension that will matter most is execution speed in regulated production rather than research depth or protocol authorship.
This is also the layer where most analyst coverage falls short. The narrative is usually framed as “company X launched Y feature.” The structural question is which institutions are building the full three-layer stack and which are shipping point solutions that look like the stack from the outside. The first category is small. The second is large. The next 24 months will tell which is which.
Show Image
Figure 3. The fintech category map. Six payments networks positioned across the dimensions that matter for the substrate-plus-model-plus-identity stack. The competitive answer is not visible in any single row — it emerges from the combination.
12. Future Use Cases
The architecture described above generates a use case surface much wider than advertising and commerce. Six concrete extensions worth thinking about, each grounded in the substrate rather than speculation.
Personalized dynamic underwriting. Sequence-level transaction embeddings let credit decisions move from snapshot underwriting — credit score at a point in time, plus a handful of attributes — to continuous behavioral underwriting. The substrate carries the full sequence of how a user has spent, saved, and managed money. Underwriting models can score against the sequence rather than the snapshot, with materially higher predictive power for thin-file consumers and small businesses. The block in legacy systems was data sparsity. The substrate solves it.
Agent-mediated subscriptions and recurring commerce. When agents manage subscriptions on a user’s behalf, every recurring transaction needs to verify the user’s mandate and the agent’s authority. The mandate is not just “this user authorized this agent” — it is “this user authorized this agent for this category, at this price ceiling, with these exception conditions.” The transaction graph tracks every prior recurring authorization, the foundation model verifies whether the new transaction matches the historical pattern, and the identity layer surfaces the verified agent credential to the merchant. Subscription churn, cancellation flows, plan upgrades, and renegotiation all run through the same architecture.
B2B agentic procurement. The largest dollar volume in agent-initiated commerce will not be consumer. It will be enterprise procurement, where supplier agents negotiate with buyer agents at machine speed for repeat purchases, contract pricing, and bulk fulfillment. The identity layer has to verify both the enterprise’s procurement mandate and the supplier’s agent authority. PayPal’s enterprise commerce relationships position the substrate for this segment, even though most current public framing emphasizes consumer use cases.
Cross-border agent transactions with stablecoin settlement. The intersection of agentic commerce and stablecoin settlement is the surface where PayPal’s PYUSD positioning becomes structurally important. Agents transacting across borders need a settlement layer that is faster than card networks, lower in friction than traditional cross-border wires, and verifiable at the identity layer. PYUSD on its native rails plus the Transaction Graph identity primitive plus the agent verification protocol forms a complete stack. Most current commentary treats stablecoins and agentic commerce as separate stories. They are the same story.
Real-time disputes and chargebacks with attributable agent identity. The chargeback model assumes a human pressed the buy button. When an agent did it, dispute resolution needs verified agent identity in the transaction record, mandate history showing the user’s authorization, and an audit trail that survives examination. PayPal’s combined position as identity provider and merchant of record makes this resolvable in ways pure rails providers cannot replicate alone. Mastercard’s Agentic Tokens and ACP’s Shared Payment Tokens are addressing the same problem from the network side; PayPal addresses it from the identity-plus-settlement side.
Preference cluster-based commerce. Once user preferences are vectorized at the transaction level, the substrate supports a different commerce optimization than mass marketing or individual personalization. Users cluster by behavior — their transaction sequences embed near other users with similar economic patterns. The supply side can respond to cluster-level demand signals rather than individual signals, which is more privacy-preserving, more statistically robust, and operationally simpler. The optimization shifts from “which ad converts this user” to “which inventory matches this cluster’s near-term demand.” This is genuinely new territory and underexplored in most academic and industry coverage.
These six are illustrative rather than exhaustive. The pattern across all of them is that the substrate makes each application simpler than its current implementation, because the verification, embedding, and identity work has been done upstream. The cost of building each new use case collapses, which is the operational consequence of the foundation model architecture.
13. Business Impact
The business case for the stack is three concentric layers. Each layer is a different conversation with a different stakeholder.
The P&L layer is the most immediate. Closed-loop attribution lifts measurable ROAS, which lifts advertiser spend per dollar of PayPal Ads revenue, which compounds the AI flywheel because more spend generates more data. The free-distribution model on Ads ID looks counterintuitive from a software economics perspective. It is the right move when the economics live one layer down the stack, in the transaction relationships the identity unlocks. The take rate on commerce-driven media is materially higher than the take rate on standalone payment processing.
The foundation model approach also compresses the cost line. A per-task ML stack with 12 production models is 12 feature engineering pipelines, 12 retraining cadences, 12 monitoring systems, 12 audit trails. A foundation model approach is one substrate plus 12 fine-tunes. The unit economics of new use cases collapse. Stripe’s published number — moving from 80 percent reduction in card testing attacks over two years to 64 percent improvement on large business detection rate practically overnight — is the operational consequence of the architecture. Step-function improvements show up in operating margin, not just product metrics.
Fraud and dispute resolution is its own line. Sequence-level fraud detection catches patterns that transaction-level detection misses. Chargeback rates decrease. Dispute resolution costs decrease. Synthetic identity attacks, which will scale with agent automation, are defended through the substrate rather than through post-hoc detection. The bottom-line effect is a measurable reduction in fraud losses and operational cost per transaction.
The strategic moat layer is harder to quantify and more durable. The substrate plus model plus identity primitive forms a flywheel: every transaction processed improves the foundation model, which improves the identity layer, which improves the agentic commerce surface, which attracts more transactions. The flywheel is not architecture, not compute, not model size. It is proprietary data closed by network effects. This is the only form of moat that has held up in AI through 2025 and 2026.
The flywheel also generates compounding option value. New use cases — underwriting, B2B procurement, stablecoin settlement, preference cluster commerce — become incrementally cheaper as the substrate matures. The institution that hits 12 production use cases before the next institution hits 6 has structurally better unit economics for use case 13. This is what compounding looks like in AI.
The addressable market layer is the third. PayPal’s positioning shifts from payment processor (commodity rails, take rate compression) to trust layer for the agentic web (premium infrastructure, expandable take rate). New TAM segments open. B2B agentic procurement is large and underserved. Embedded finance for AI-native applications is a category that did not exist three years ago. Agent-to-agent settlement is the longer-horizon TAM expansion as the agent economy matures. None of these segments existed at meaningful scale in 2023. All of them will exist at meaningful scale by 2028.
The honest counter is the part that has to be on the page if the rest of the argument is to be credible.
Probabilistic identity graphs with sufficient scale could narrow the deterministic advantage. The Trade Desk’s UID 2.0 has 30 to 40 percent reach across the open web. If the gap between deterministic and probabilistic narrows, the marketing case for verified-only identity weakens.
Walled gardens could deepen their attribution loops faster than open-substrate identity providers can build cross-platform attribution. Google and Meta are not standing still on agent-mediated commerce.
Regulatory headwinds on transaction data use — particularly under the EU AI Act and emerging US state-level AI legislation — could constrain the embedding surface. The substrate is only as useful as the law allows it to be used.
Competitive entrants from outside payments — large tech companies acquiring or partnering into payment graphs, foundation model labs offering vertical-specific models — could compress the speed-of-execution moat.
None of these counters invalidates the thesis. All of them are reasons the next 24 months matter more than the last 24 months. The institutions that ship the full stack into regulated production fastest will define the category. The institutions that ship features will be acquired or compressed.
14. What’s Next
The substrate is built. The model is shipping. The identity layer is in market. The first agent-facing surfaces are live in production at PayPal, Stripe, Visa, and Mastercard. The protocol layer is real and growing. The next 24 months are not about whether this stack exists. They are about who finishes building it.
The unsolved problems are concrete and worth naming.
Agent-to-agent commerce protocols are not yet standardized. MCP, A2A, ACP, UCP, AP2, MPP, x402 — the alphabet is dense and the interoperability between protocols is mostly aspirational. The institution that bridges the protocol fragmentation with a verified identity primitive underneath has an outsize position.
Cross-network identity portability is the next question. A verified identity at PayPal does not automatically interoperate with a verified identity at Stripe, Visa, or Mastercard. The user does not want to manage four identities. The agent ecosystem will not scale without portability. Whether portability is achieved through industry standards, regulatory mandate, or commercial agreement is genuinely open in 2026.
The regulatory framework for fully agent-mediated finance is not yet drafted. The CFPB, the SEC, the OCC, the EU’s AI Office, and equivalents in Asia are all studying agentic finance. The regulations that emerge in 2027 and 2028 will reshape the architecture. The institutions co-designing with regulators today will ship architectures that survive. The institutions waiting for clarity will rebuild.
Attribution and dispute resolution when the buyer is software is its own deep problem. The chargeback model assumes a human pressed the buy button. The agent did. The legal framework for who bears responsibility — the user who gave the mandate, the agent that executed it, the platform that ran the agent, the merchant that accepted it — is undefined. The technical infrastructure exists. The legal infrastructure does not yet.
The closing principle is the simplest part. In agentic commerce, the identity layer is not a feature. It is the substrate everything else runs on. The institutions that operate verified transaction graphs at scale, that have built foundation models on top of those graphs, and that ship deterministic identity primitives into the ecosystem are the institutions positioned to operate that substrate.
PayPal is one of those institutions. So are Stripe, Block, Adyen, Visa, Mastercard. The competitive question over the next 24 months is which of them ships the full stack into regulated production fastest, which builds the most credible agent-facing surfaces on top, and which navigates the regulatory frame without rebuilding. The institutions outside payments will discover that protocols and foundation models are necessary but not sufficient. The substrate is the constraint.
The advertising transformation is the visible layer. The commerce transformation is the structural layer. The identity transformation is the substrate. They are not three separate stories. They are one story told from three angles.
References
Academic papers cited
- TREASURE: A Transformer-Based Foundation Model for High-Volume Transaction Understanding. KDD 2026. Frames the unit of representation in payments as the transaction sequence rather than the row, and motivates the multi-task embedding architecture used in second-generation payments foundation models.
- PRAGMA: Revolut Foundation Model. arXiv:2604.08649, April 2026. The most recent publicly described production financial foundation model. Positions itself against nuFormer and TransactionGPT and argues for multi-task design with static profile state fused into transaction sequences. https://arxiv.org/html/2604.08649v1
- TransactionGPT. Dou et al., arXiv:2511.08939, November 2025. First-generation transformer-based model trained on transaction ledgers for anomaly detection and trajectory generation. https://arxiv.org/abs/2511.08939
- Enhancing Foundation Models in Transaction Understanding with LLM-based Sentence Embeddings. arXiv:2601.05271. Addresses the merchant tokenization problem — mapping merchant names to learned indices throws away most of the behavioral signal that lives in the merchant axis. LLM-derived semantic embeddings provide a richer prior. https://arxiv.org/pdf/2601.05271
- A Survey of Agent Interoperability Protocols: MCP, ACP, A2A, ANP. Ehtesham et al., arXiv:2505.02279, May 2025. The canonical citation for the protocol landscape underneath agentic commerce. https://arxiv.org/abs/2505.02279
- Zero-Trust Runtime Verification for Agentic Payment Protocols: Mitigating Replay and Context-Binding Failures in AP2. Lan, Kaul, Jones, Westrum (eBay). arXiv:2602.06345, February 2026. The failure-mode argument for why specification-level guarantees do not survive production runtime. Foundational reading for anyone building on AP2. https://arxiv.org/abs/2602.06345
- SoK: Security of Autonomous LLM Agents in Agentic Commerce. arXiv:2604.15367, early 2026. Sober deployment-status assessment across ERC-8004, ERC-8183, AP2, x402, MPP, and ACP — useful for separating shipped reality from announced protocol. https://arxiv.org/html/2604.15367v1
Industry sources
- PayPal Brings New Commerce-Grade Identity Solution to Advertising Industry. PayPal Newsroom, April 27, 2026. Official launch announcement for PayPal Ads ID.
- Even PayPal Ads Has Its Own ID Now. James Hercher, AdExchanger, April 27, 2026. Industry coverage with commentary from Dan Robbins (PayPal Ads head of growth and strategy).
- PayPal bets on payment data to fix advertising’s identity problem. PPC Land, April 27, 2026. The sharpest analytical take, including the ~30% global purchase volume framing.
- PayPal Ads Launches Transaction Graph Insights and Measurement. PayPal Newsroom, January 6, 2026 (CES 2026). Earlier launch establishing the Transaction Graph as a product surface for merchants and advertisers.
- Using AI to Optimize Payments Performance with the Payments Intelligence Suite. Stripe Blog, May 15, 2025. Stripe’s PFM launch announcement with the 64% improvement in card-testing attack detection.
- Stripe’s Payments Foundation Model: How Data and Infra Create Compounding Advantage. Emily Sands on The Cognitive Revolution podcast, January 2026. Source for the “spinning up a new model becomes a weekend project” framing.
- How Agentic AI Will Reshape Payments. IMF Note NOTE/2026/004. Source for the “trust layer for the agentic web” positioning of PayPal in agentic commerce architecture.
- The Agentic Commerce Landscape: Who’s Building What in 2026. Rye, March 2026. Mapping of venture activity in the identity and payments layer, plus the consolidated protocol overview.
- When Agents Go Shopping: The Infrastructure Behind Agentic Commerce. Insignia Business Review, April 24, 2026. Source for the x402 deployment stats and the identity-and-trust-as-bottleneck framing.
- Visa AI-Initiated Payments: What Fintech Must Know in 2026. ALM Corp, March 2026. Detailed coverage of Visa Intelligent Commerce and the Trusted Agent Protocol architecture.
- 2025 State of the Industry Report. Source for the 21% identity confidence statistic in Section 1.
Regulatory frameworks referenced
- SR 11–7 — Federal Reserve Guidance on Model Risk Management
- EU AI Act — Regulation (EU) 2024/1689
- PCI DSS — Payment Card Industry Data Security Standard
- DORA — Digital Operational Resilience Act (EU 2022/2554)
- Treasury FS AI RMF — US Treasury Financial Services AI Risk Management Framework, 2024
- NIST AI RMF — NIST AI Risk Management Framework (referenced as the basis for the Treasury FS AI RMF)