Distributed Systems
What happens to client updates when your backend scales horizontally

This started as one of those production bugs that sends you looking in the wrong places first.
A user would trigger an action in the UI. Our backend would hand the work off for asynchronous processing. An external system would finish later and send a callback. The browser, connected through a streaming channel, should then receive the update almost immediately.
In staging, with a single service instance, it worked exactly as expected.
In production, after we added multiple Kubernetes replicas, some users simply stopped seeing updates. We could not reproduce it on demand, which made it even more frustrating. There were no 500 errors. No obvious timeouts. Our dashboards stayed green. Callback metrics looked normal.
And yet the real-time update never showed up in the browser.
What made this especially confusing was that nothing was technically “broken”. The system was doing what it had been designed to do.
It just was not designed for this coordination problem.
My first instinct was to suspect SSE, ingress behavior, or some flaky timeout between services. None of those turned out to be the real issue.
If your architecture combines asynchronous workflows, webhooks, and long-lived client connections, you will probably run into some version of this once you scale horizontally.
I now think of it as the distributed client-context problem: the work can finish anywhere in the cluster, but the client connection exists in exactly one process.
What We Saw in Production
Behind the scenes, the browser opened a long-lived connection to our backend-for-frontend service using Server-Sent Events (SSE). That service kicked off asynchronous work elsewhere. When the external system finished processing, it sent a callback. The backend then tried to push the result back to the browser over the existing stream.
In a single-instance deployment, that feels trivial. The same process that receives the callback also owns the client connection. No coordination is needed.
Once we introduced multiple replicas behind a load balancer, that assumption quietly fell apart.
The client connection might land on Pod A. The callback could arrive at Pod B. Pod B would still do all the “right” things: validate the request, log it, persist state, and return 200 OK. It would then try to notify the client.
But Pod B did not own the connection.
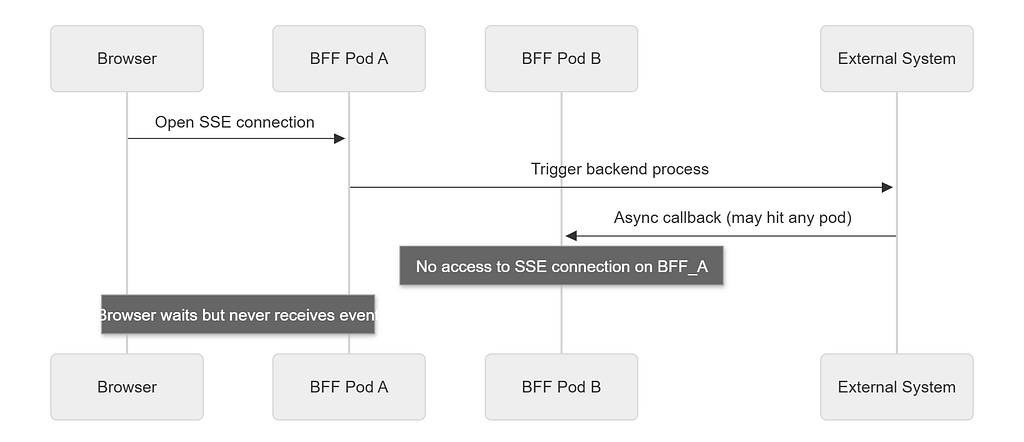
connection.
From an infrastructure perspective, everything looked healthy. From the user’s perspective, the update never arrived.
That silent gap between successful processing and successful delivery is the real problem.
The Assumption I Had Wrong
Cloud-native design pushes us toward stateless services, and for good reason. Stateless workloads scale cleanly, deploy predictably, and recover easily.
But long-lived client connections are not stateless.
When a browser establishes an SSE or WebSocket connection, that connection is bound to a specific process. It lives in memory. It is not automatically shared across replicas.
At the same time, asynchronous work is replica-agnostic. Webhooks, background jobs, and event-driven callbacks can land on any instance.
What finally clicked for me was this: execution had become distributed, but connection ownership had not.
That mismatch is invisible in a single-instance environment, which is why it often escapes testing. It only becomes obvious after horizontal scaling enters the picture.
We Fixed the Architecture, Not the Transport
Our first instinct was to question the transport:
- Should we switch from SSE to WebSockets?
- Should we enable sticky sessions?
Both ideas were reasonable, and I briefly went down that path myself, but neither addressed the root issue.
The problem was not how the browser talked to the backend. It was how the replicas coordinated after the callback arrived.
Once that became clear, the next step was straightforward: separate client delivery from replica coordination.
Instead of trying to route every callback back to the “right” pod, we introduced a lightweight broadcast layer between replicas.
When a callback arrives, the receiving replica publishes an event. All replicas subscribe. The replica that owns the client connection forwards the update.

the client.
In our case, Redis Pub/Sub was the right fit because it was already part of the platform and provided low-latency fan-out.
But Redis was not the main insight.
The real shift was recognizing that coordination is a separate concern from delivery.
Once we modeled it that way, scaling stopped being fragile.
Where the Implementation Gets Subtle
A coordination layer solves the core mismatch, but it introduces its own design concerns.
We derived channel identifiers from stable request or user IDs, and each pod maintained an in-memory map between those identifiers and active client connections.
Rather than opening a separate Redis subscription per client — which does not scale — each pod used a shared subscriber and routed messages internally.
Connection lifecycle management became critical. When clients disconnected, those mappings had to be cleaned up immediately. Channel ownership needed to stay short-lived. Otherwise, stale references accumulated under load.
None of these details were particularly difficult in isolation.
Under real traffic, however, small oversights became visible: lingering subscriptions, memory growth, and race conditions during reconnects.
Adding a coordination layer is architectural work. It is not just “wire up Redis and move on”.
The Part Our Monitoring Missed
This issue was difficult to diagnose precisely because nothing looked broken in the usual dashboards.
CPU was stable. Latency was healthy. Error rates were low.
But users were still missing updates.
We eventually realized we were monitoring processing, not delivery.
So we started tracing the flow end-to-end: request initiation, callback receipt, event publication, and final delivery to the client connection.
By propagating a correlation ID across the full path, we could finally see where the system diverged: callbacks were being processed successfully, but notifications were not always being delivered.
That gap was invisible in traditional infrastructure metrics.
Our alerting changed accordingly. Instead of tracking only system health, we began tracking coordination health — whether published events consistently resulted in client delivery.
Without that visibility, this class of failure remains silent.
Real-Time Delivery Should Not Define Correctness
Redis Pub/Sub is fast, but it is not durable. Messages are transient. If Redis restarts, in-flight notifications can be lost.
That forced us to be more disciplined about what “real-time” meant.
We stopped treating streaming notifications as the source of truth. Instead, they became signals that prompt the client to reconcile against authoritative backend state.
All updates were idempotent. If a notification arrived twice, nothing broke. If a notification was missed, the client could safely fetch the latest state.
Real-time delivery improves the user experience.
It should not be the thing that determines correctness.
Why This Problem Shows Up More Often Now
This coordination gap is not new, but modern architecture makes it increasingly common.
Horizontal scaling is the default. Kubernetes makes it easy to add and remove replicas dynamically. Traffic is distributed automatically. Connection ownership becomes transient.
At the same time, asynchronous workflows dominate modern SaaS systems. Third-party platforms rely on webhooks. Background jobs process long-running tasks. Real-time dashboards and streaming interfaces are now expected.
Execution paths are increasingly decoupled from request lifecycles.
When you combine stateless replicas, webhook-driven workflows, and real-time UI expectations, the separation between execution context and connection context becomes unavoidable.
As event-driven systems expand — including AI-assisted streaming experiences — this issue shows up more often.
In practice, it is not a strange corner case. It is a fairly natural outcome of combining horizontal scaling with long-lived client connections.
A Practical Design Checklist
If your system depends on real-time notifications, a few design rules help prevent this class of bug:
- Treat client connections as process-local state. They do not magically follow the request across replicas.
- Decouple callback handling from client delivery. Use an internal coordination channel when work can complete on any node.
- Propagate correlation IDs end-to-end. Measure delivery, not just processing.
- Make client updates idempotent. Duplicate notifications should be harmless.
- Keep backend state authoritative. Real-time messages should accelerate UX, not define correctness.
Final Takeaway
If I were designing this flow again from scratch, I would start with a simpler question: which instance actually owns the client connection, and how will the rest of the system know that?
That turned out to matter more than whether we used SSE or some other real-time protocol.
Once you scale horizontally, connection ownership becomes a distributed-state problem. If replicas do not coordinate explicitly, successful delivery starts to depend on luck.
Separating client delivery from backend event distribution made the system much more predictable for us.
Stateless services are powerful. They do not eliminate state; they just move it somewhere else.
Once we saw that clearly, the design decisions became much easier.
I plan to follow this article with a small Node.js example that shows the behavior end-to-end: how it works in a single instance, how it fails after horizontal scaling, and how a coordination layer fixes it.
Everything Worked — Until We Scaled: The Hidden Coordination Problem in Stateless Systems was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.




