Deterministic Verification for Autonomous AI Coding Systems: A Practitioner’s Architecture
--
*How to make AI-generated code trustworthy in environments where “mostly correct” isn’t good enough.*
— -
The Problem With Letting AI Write Code Unsupervised
Autonomous AI coding agents are no longer experimental. Many engineering organizations are exploring or beginning to deploy them to implement features, write tests, and prepare merge requests with varying degrees of human supervision. In environments where a failed build is an inconvenience, this works well enough. In production-critical systems where a defect can trigger an audit finding, a security incident, or downstream financial impact, “well enough” is insufficient.
The core issue is architectural, not behavioral. A large language model generating code operates as a stochastic sampling process. At each token position, the model selects from a probability distribution. This process is non-deterministic: identical prompts may yield different outputs, and the probability of a correct output at any single decision point is bounded below unity. In an autonomous pipeline where the model makes dozens of sequential decisions (which files to modify, which interfaces to implement, which dependencies to install), the compound probability of a fully correct execution degrades rapidly.
At an empirically reasonable per-decision reliability of 85–90%, a pipeline with ten independent decision points encounters at least one deviation roughly 65–75% of the time. This is not a model deficiency. It is a mathematical property of probabilistic sequence generation applied to a domain where correctness is binary. Code compiles or it does not. A test passes or it fails. A vulnerability exists or it does not.
— -
Why Prompting Alone Is Insufficient
The instinctive response to unreliable AI output is better prompting: more detailed instructions, more examples, more constraints in the system prompt. This helps (it biases the probability distribution toward the correct region of the output space) but it cannot provide the guarantees that high-assurance systems require.
Three structural problems remain regardless of prompt quality:
Self-reported status is stochastic. When you ask an AI agent whether its code compiles, the answer is itself a generated token drawn from a probability distribution. The model can report `build_status: “success”` even when no code was actually written. This failure mode, a phantom build where the agent describes what it would write rather than writing it, is undetectable by any prompt-based mitigation because the report and the reality share the same probabilistic generation mechanism.
Compound reliability degrades with pipeline depth. A single LLM invocation might be 90% reliable. A ten-step pipeline operating at 90% per step delivers a fully correct end-to-end result roughly 35% of the time. Prompting each step better shifts the per-step rate from 90% to perhaps 93%, but compound reliability still degrades with depth.
High-assurance systems require deterministic controls. In domains where software changes carry legal, financial, or safety implications, governance frameworks demand demonstrable, repeatable controls over the change process. A control that produces different verdicts on identical inputs, which any LLM-based evaluation might, cannot satisfy these requirements. The control must be deterministic: same input, same verdict, every time.
— -
Deterministic Verification as an Architectural Boundary
The resolution is to stop treating generation reliability and output correctness as the same problem. They are not. The generation function should remain probabilistic, because that flexibility is what makes it useful. The acceptance boundary should be deterministic, because that rigidity is what makes it safe.
This separation draws on a well-established paradigm from formal methods: Counterexample-Guided Abstraction Refinement (CEGAR). A candidate solution is generated, verified against formal properties, and if verification fails, the counterexample refines the next candidate. Applied to AI-generated code: the model generates freely, deterministic oracles verify mechanically, and failure diagnostics guide the next attempt.
The key architectural principle: never trust the generator’s self-assessment. Trust only the output of deterministic verification tools (compilers, test runners, static analyzers) whose verdicts are reproducible and auditable.
— -
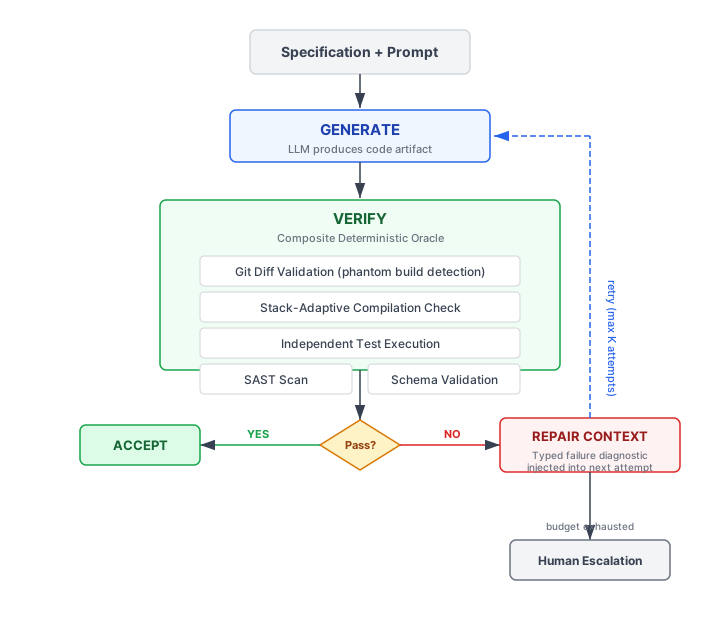
The Generate-Verify-Repair Model
The architecture implements a closed loop with three phases: generate, verify, repair. The generator produces code. A composite verification oracle evaluates it against multiple independent correctness predicates. If any predicate fails, the specific diagnostic output is fed back as repair context for the next generation attempt.
The Verification Oracle Stack
Verification is not a single check. It is a pipeline of independent oracles, each targeting a distinct failure class:
Git state validation. The most elementary oracle verifies that the generator produced actual file modifications, not a textual description of intended modifications. This catches phantom builds by comparing the workspace against an immutable baseline commit captured before generation begins. If `git diff — stat` is empty but the agent claims success, the output is rejected.
Stack-adaptive compilation. Enterprise repositories are frequently polyglot. The verification system detects which technology stacks are present (via marker files like `package.json`, `go.mod`, `pyproject.toml`), determines which stacks were affected by the current change (via file extension mapping), and executes only the relevant compilers. A Python-only change does not trigger TypeScript type checking.
detect stacks present in workspace
filter to stacks affected by current change set
for each affected stack:
execute stack-specific compilation validation
if compilation fails:
reject output with deterministic failure diagnosticIndependent test execution. The test oracle runs the test suite independently of the agent’s self-reported results. The agent may claim all tests pass; the oracle verifies by executing the test runner and checking the exit code. This dual-channel validation catches both false positives (agent claims pass, tests fail) and status inconsistencies (agent reports test failures but still claims overall success).
Static application security testing. AI-generated code inherits vulnerability patterns from training data. A SAST oracle scans only files modified by the current attempt, avoiding false failures from pre-existing issues, and rejects outputs containing critical or high-severity findings.
The Repair Loop
When verification fails, the diagnostic output is not discarded. It is injected as structured context for the next generation attempt:
for each attempt within bounded budget:
generate output from prompt + accumulated repair context
run composite verification oracle
if all oracles pass:
accept output
else:
extract typed failure diagnostic
inject as repair context for next attempt
if budget exhausted:
escalate to human reviewThree design decisions make this effective:
Workspace preservation on verification failures. When verification fails (compilation error, test regression), the partially-correct code remains on disk. The next attempt performs a targeted repair, fixing the specific type errors the compiler identified, rather than regenerating everything from scratch. Conversely, when the failure is an invocation error (crash, timeout), the workspace is reset because prior state may be corrupt.
Typed error signals, not generic retries. The repair context contains the actual compiler stderr, the test runner’s failure trace, the SAST tool’s finding summary. This transforms the retry from an independent re-sample into a directed search guided by specific failure information. The model is not told “try again.” It is told exactly what broke and where.
Bounded attempt budget. The loop terminates after a fixed number of attempts (typically 2–3). Unbounded retries risk cost explosion and infinite loops. If the budget is exhausted without convergence, the pipeline fails and escalates to human review.
— -
Why This Matters in Production-Critical Systems
In financial services, healthcare, defense, and other high-assurance domains, the verification architecture addresses requirements that no amount of prompt engineering can satisfy:
Auditability. Each verification oracle produces an independent, timestamped verdict. These verdicts form an audit trail demonstrating that every AI-generated change was mechanically validated before acceptance. When someone asks “how do you control AI-generated changes?”, the answer is a reproducible verification pipeline with recorded evidence, not “we wrote a really good system prompt.”
Deterministic controls. Governance frameworks require controls that produce consistent results. A compiler’s exit code is deterministic. A test suite’s pass/fail verdict is deterministic (given the same code and environment). These satisfy control requirements in a way that LLM-based review, which might produce different assessments on different days, cannot.
Defense in depth. A single verification layer can be escaped. Code that compiles might still contain vulnerabilities. Code that passes tests might still introduce phantom builds. The composite oracle structure ensures that each failure class has an independent detection mechanism, following the same defense-in-depth principle used in network security.
Risk-aware gating. Beyond mechanical verification, changes can be scored by risk factors: total lines changed, fraction of security-critical files modified, confidence scores from independent quality evaluation. High-risk changes route to mandatory human review regardless of whether mechanical checks pass.
In practice, deterministic verification architectures are most effective when operating alongside human engineering review for high-risk or architecturally sensitive changes. The goal is not to eliminate human judgment but to ensure that autonomous systems meet a verifiable minimum standard before human attention is applied where it matters most.
— -
Practical Limitations
Any honest discussion of this architecture must acknowledge what it cannot do:
Semantic verification remains unsolved. The oracle stack catches mechanically-verifiable defects: compilation errors, test failures, known vulnerability patterns, phantom builds. It cannot evaluate whether an abstraction boundary is well-designed, whether method decomposition follows codebase conventions, or whether the implementation represents good engineering judgment. These properties are not expressible as deterministic predicates; they require contextual reasoning about how similar problems are solved elsewhere in the codebase.
In practice, this often manifests as a qualitative gap. Conceptually, GVR-style systems are strongest on dimensions amenable to mechanical validation, such as specification compliance and test coverage, while human engineers remain essential for architectural judgment and codebase-specific design quality.
Architecture-level decisions are beyond scope. The verification oracle can confirm that generated code compiles and passes tests. It cannot determine whether the code should have been a library rather than inline logic, whether the module boundaries are appropriate, or whether the implementation will create maintenance burden. These are judgment calls that currently require human review for high-stakes systems.
Benchmarking is limited by topology. Results from a single codebase topology (monorepo with specific technology stacks) may not generalize to different architectures (microservices with distributed test suites), different task complexities (greenfield development vs. feature additions), or different model families. The verification architecture’s effectiveness depends on the quality and coverage of the mechanical verification tools available for a given stack.
Cost-convergence tradeoffs are real. Each repair cycle consumes additional compute and wall-clock time. The optimal attempt budget depends on API costs, latency requirements, and the probability distribution of convergence per attempt, a tradeoff that requires empirical tuning per deployment context.
— -
Conclusion: The Future of Trustworthy AI-Assisted Engineering
The Generate-Verify-Repair architecture represents a specific instance of a broader principle: the safe deployment of probabilistic AI systems requires deterministic boundaries that are independent of the AI’s self-assessment. The generator’s flexibility is what makes it useful. The verifier’s rigidity is what makes it safe. These properties are complementary, not contradictory.
As AI-accelerated development becomes standard practice, the ability to deploy autonomous coding agents with demonstrable, auditable, deterministic controls becomes a prerequisite, not just for governance, but for basic engineering confidence. The verification architecture does not slow adoption of AI in production-critical environments. It enables it, by providing the formal assurance mechanisms that engineering leaders require before permitting autonomous systems to modify production-relevant code.
The frontier challenge is clear: closing the gap between “does it compile and pass tests?” and “is it well-engineered?” The GVR architecture establishes a floor, a minimum safety net below which no output escapes, but the ceiling of engineering quality remains dependent on the generative model’s capacity to internalize human engineering judgment. Advancing that ceiling through better contextual prompting, codebase-aware generation strategies, or hybrid human-AI workflows is where the field moves next.
The systems most likely to earn trust in high-assurance environments are not necessarily those that generate code fastest, but those capable of demonstrating reproducible and independently verifiable control over generated artifacts.
The views expressed here are my own and do not represent any employer or organization.
— -
*This article is based on my working paper, “Convergent Correctness in Stochastic Code Generation: A Generate-Verify-Repair Architecture for Deterministic Validation of Autonomous AI Coding Agents in Regulated Environments,” available on SSRN: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6754899*
*Rafael Cadenas is a software engineer focused on AI-assisted development systems, enterprise software reliability, and secure financial technology infrastructure.*

