Most AI systems break when you swap the model. Mine didn’t — three orchestrators, 27 calls, zero server changes.
Will you still be using the same AI next year?
What if GPT raises prices? What if Claude changes its policy? What if a better open-source model drops? Do you rebuild every agent from scratch?
When building a multi-agent AI system, the first question to answer isn’t “which LLM should I use?” It’s “when I swap the LLM, do I have to rebuild the server?”
The Experiment: One Server, Three Orchestrators
In my previous article, I built a 6-agent MCP system on GCP — Email, CRM, Calendar, CS, Helpdesk, and Report agents orchestrated by Claude Desktop. I ended with a question: can you freely swap out the client and AI without changing a single line of server code?
This article is the answer.

Same run_email_agent, run_crm_agent, run_calendar_agent tools, same GCP VM, same ports (9000/9001/9501). Only the client and its AI changed. I tested each setup three times over two days to confirm the results were repeatable.
The result: 27 calls. Server code changes: zero. Success rate: 100%.
Architecture: What Changed, What Didn’t
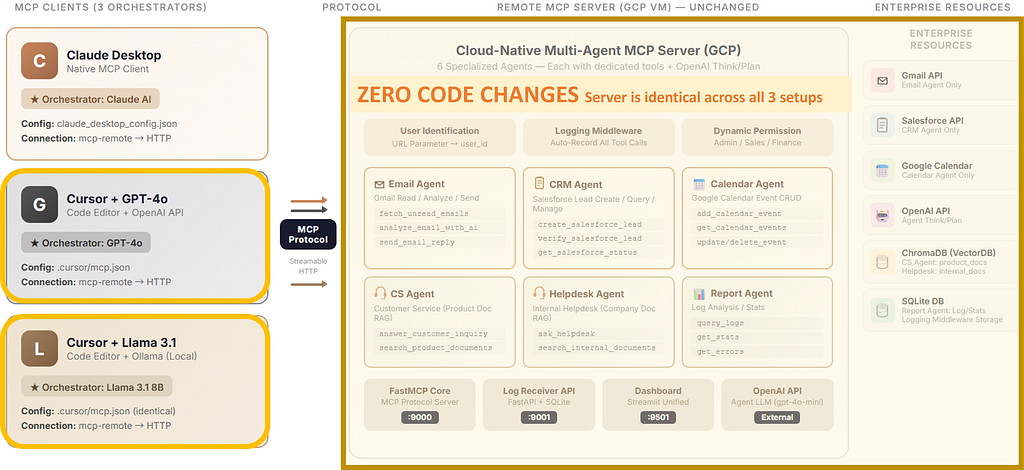
The MCP server doesn’t know which AI is calling it. It receives tool calls and returns results. The intelligence — which agent to call, in what order — lives entirely in the client-side AI.
Setup B: Cursor + GPT
Cursor uses a .cursor/mcp.json file to define MCP server connections. The configuration is nearly identical to Claude Desktop's:
{
"mcpServers": {
"multi-agent": {
"command": "npx",
"args": [
"-y", "mcp-remote",
"http://34.xxx.xx.64:9000/mcp?user_id=admin",
"--allow-http"
]
}
}
}The only differences are the file location (.cursor/mcp.json instead of claude_desktop_config.json) and adding an OpenAI API key in Cursor's settings. When I asked "Check my unread emails," GPT read the MCP tool descriptions and correctly called run_email_agent — exactly like Claude does.
Setup C: Cursor + Llama 3.1 (Local Open-Source)
Running a local open-source AI as the orchestrator for a cloud-based multi-agent system.
Installing Ollama and Connecting to Cursor
Ollama packages open-source LLMs for local execution. Install it, pull a model, and you get an API on localhost:11434 that speaks the same format as OpenAI's API. Any code that calls OpenAI can call Ollama by just changing the URL.
# Pull Meta's Llama 3.1 (8B parameters, ~4.9GB)
ollama pull llama3.1
In Cursor: Settings → Models → set Override OpenAI Base URL to http://localhost:11434/v1. The MCP configuration (mcp.json) stays identical to Setup B. Only the AI inference location changes — from OpenAI's cloud to your local CPU.
Note: on Cursor’s free plan, enabling the URL override routes all requests to Ollama, disabling GPT. You toggle between them.
Hardware Reality Check
Llama 3.1 8B ran on my laptop:
- CPU: Intel Core Ultra 5 225H (14 cores)
- RAM: 16GB (model uses ~5GB)
- GPU: Intel Arc 130 (integrated — no dedicated GPU)
No NVIDIA GPU. No cloud compute. A regular laptop orchestrating cloud-based enterprise agents.
Result
Llama 3.1 correctly selected run_email_agent for "Check my unread emails," and the MCP server processed it identically. An 8-billion parameter model on a laptop CPU successfully orchestrated the same multi-agent system that Claude and GPT were driving.
The Three-Way Comparison: Real Production Logs
I sent the same three requests (service status, calendar, unread emails) to all three orchestrators — not once, but three separate rounds over two days. 27 total calls, all captured in the dashboard.
Round 1: First Attempt (March 22)

Llama’s 568ms status check stood out. The local 8B model needed time to parse the tool schema on its first encounter.
Rounds 2 & 3: Repeated Tests (March 23)
I ran the exact same requests again — twice — the next day.
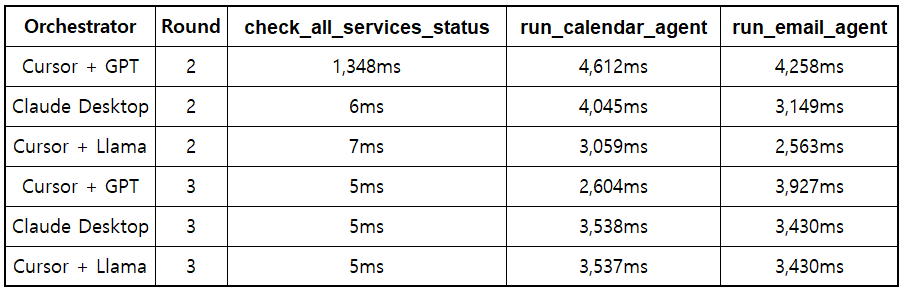
27 calls, 100% success rate across all rounds.
What the Repeated Tests Revealed
The first call after a server restart pays the cold-start penalty — regardless of orchestrator. In Round 2, GPT-4o happened to go first after the MCP server restarted and hit 1,348ms on check_all_services_status. This wasn't a GPT-specific issue — it was the server warming up. By Round 3, the same call took 5ms for all three. Llama's 568ms in Round 1 was also a first-encounter overhead (parsing tool schemas locally), which disappeared once Ollama had the model loaded in memory.
Agent call times converge across all orchestrators. The initial round suggested Claude was consistently faster, but repeated rounds show all three settling into a similar 2.5–4.5s range for agent calls. In Round 2, Llama actually recorded the fastest times (3,059ms calendar, 2,563ms email) — because by the time it ran third, the server was fully warmed up. The variation is server-side noise (network latency, GCP load), not orchestrator-dependent.
The server is the bottleneck, not the orchestrator. Whether the request comes from Claude, GPT, or a local Llama, agent execution takes roughly the same time. The server runs the same gpt-4o-mini reasoning regardless of who called it. The call order matters more than the caller.
Beyond Speed
Tool selection accuracy: All three correctly identified the right tool every time. Clear tool naming like run_email_agent helps even an 8B model.
Response synthesis: Claude adds the richest context, GPT-4o structures cleanly, Llama 3.1 reports literally.
Multi-step reasoning: For complex chained requests, Claude excels. Llama at 8B parameters can struggle — model size matters here.
Cost and privacy: Claude/GPT-4o incur per-request API costs. Llama is free, and orchestration-layer data stays on your machine.
What This Experiment Proved — and What It Didn’t
What proved
The client-side orchestrator is freely swappable. MCP separates “which agent to call” (client’s job) from “how to execute” (server’s job).
Open-source AI can orchestrate enterprise tools. A free model on a laptop CPU successfully routed requests to Gmail, Salesforce, and Google Calendar agents.
Client choice is real. A chat UI (Claude Desktop) and a code editor (Cursor) connected to the same MCP server with nearly identical configuration.
What didn’t touch
The server-side agent LLM stayed the same. This system has two layers of AI:

This experiment only swapped the client layer. Replacing the server-side LLM — for example, swapping out the gpt-4o-mini that runs inside each agent to think and plan — is architecturally possible. The agent code is abstracted through a service module, so the internal LLM can be swapped independently. But that’s a separate experiment. The challenge is that as models get smaller, their ability to accurately generate a structured JSON execution plan — “which tools to call, in what order, for this request” — starts to degrade. That’s the key challenge we’ll be looking at in the next experiment.
The takeaway
MCP’s value here is specific: it decouples the orchestration layer from the tool execution layer. You can freely choose the routing AI without touching agents or infrastructure. That’s significant — but it’s not the same as “MCP makes everything model-agnostic.” The agent-internal LLM is a separate concern, and that’s already covered above.
What’s Next
The MCP server stays unchanged. The next experiments push the orchestration layer further — this time beyond desktop clients entirely. The first question: does the same MCP server work with web and mobile apps, with zero server-side changes?
The second: what happens when we replace the agent-internal LLM itself — the one doing the actual planning and execution — with an open-source model?.
The experiments continue:
- Google ADK + MCP Server — Same agents, called from web and mobile
- LangGraph / CrewAI + MCP Server — Open-source orchestration frameworks with explicit graph-based workflows vs implicit orchestration
- Server-side LLM swap — Replace agent-internal gpt-4o-mini with an open-source model. Is a fully model-independent stack possible?
The full implementation is demonstrated in video on SunnyLab TV. Find me on Medium for the previous articles in this series.
Tags: MCP Server, Multi-Agent Systems, Claude, GPT-4o, Llama, Ollama, Cursor, Open Source AI, AI Architecture
Claude, GPT, or Llama? My 6-Agent MCP Server Doesn’t Care Which One You Pick was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.




