
One of the early themes of 2026 has been a growing debate over whether SaaS moats hold up as AI models keep improving. Anthropic’s new AI tooling for its Claude “Cowork” agent is a good example of why this question is getting louder: it’s designed to take on complex, real-world professional workflows — the same kind of work many software and data providers package and sell as their core product.
The reactions have been polarized. Some have dubbed this the “SaaSpocalypse.” Others, like Nvidia CEO Jensen Huang, pushed back against the notion, calling the idea that software is in decline and will be replaced by AI “the most illogical thing in the world.”
On a personal level I understand why software investors would be concerned. Just a few weeks ago I migrated my personal website from a visual builder to a self-hosted solution using Claude. The process took a few minutes and saves me $17 per month.
To use another example, for Nudge, I built a Google Analytics analyst agent that would feed me data and analysis in the terminal, which was super convenient because I no longer had to fumble around with the Google Analytics UI. Now, I could just get answers where I needed them alongside the rest of my workflow.
In other words, the concern is real and one thing is clear: you cannot build SaaS products the old way.
So when my co-founder and I started working on RapidAccess.ai — a platform to help streamline the complex world of pharmaceutical market access, one of the questions we had at the forefront of our mind is what makes our product differentiated enough to actually add value to customers beyond what they’re already likely solving internally with AI.
Admittedly, this is a complex question and I don’t claim to have all the answers, but I thought I would share my perspective with anyone who is thinking about similar things.
My first assumption when thinking about product design is that our customers would also be using AI. There’s a spectrum here. Some customers will be interacting with AI using adhoc sessions via an interface while others will have more robust agentic flows and be utilizing long-term memory. Eventually, as operating systems become more AI native and more user interfaces are built, everyone will be using agentic AI flows.
To be successful under these assumptions, you have to cater to this reality. One implication is that customers won’t only interact with your product through your UI. They’ll increasingly want to plug your product into their AI, whether that’s a personal agent, a team copilot, or an internal workflow orchestrator with long-term memory. In practice, that means the product needs to be dual-surfaced: an API/tooling layer that lets agents reliably fetch context, run specialized functions, and write outcomes back into the system of record, alongside a human-facing experience that makes those capabilities legible and safe.
At the same time, I’m not convinced the UI disappears. A big part of the “LLM as interface” narrative assumes users already know what to ask. In reality, most valuable work starts as ambiguity. Great UIs reduce the prompt burden by helping users form the right questions and surface the relevant entities, constraints, and next best actions.
Let me give some concrete examples from RapidAccess.ai.
One of our core offerings is structured access to Canadian drug review data including HTA recommendations, PCPA negotiations, and pricing outcomes. A sophisticated user could absolutely prompt Claude to analyze a CADTH report. But first they’d need to find the right PDF, upload it, and craft a prompt that extracts the fields they care about. Then do it again next week when new reviews publish. And again when they need to compare across 50 drugs.
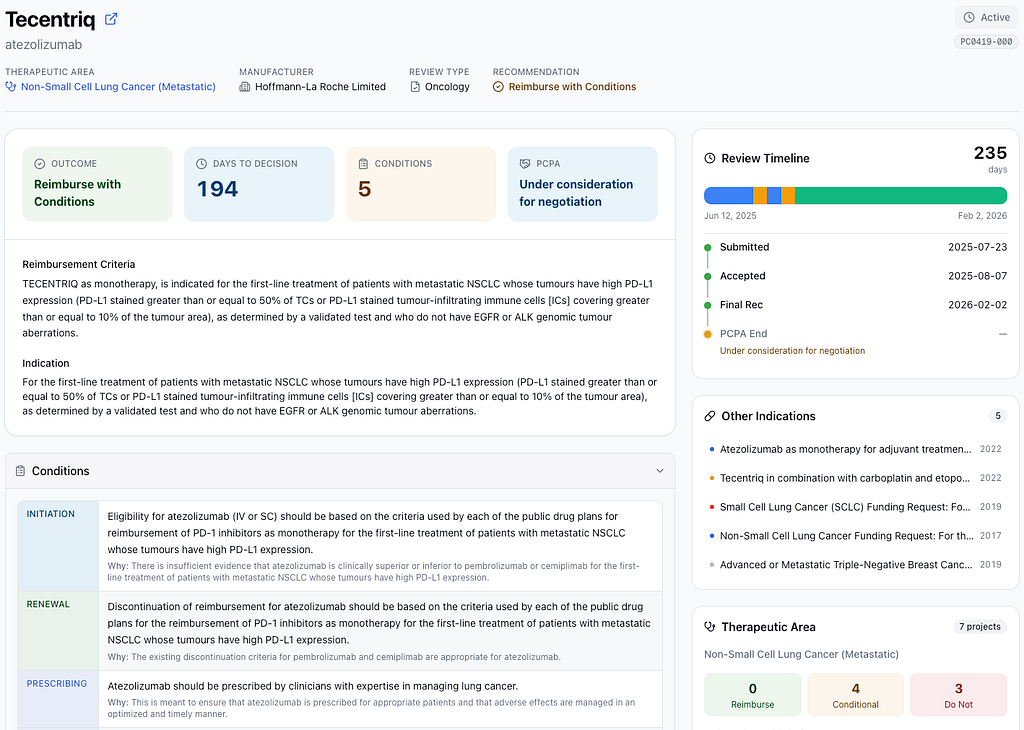
RapidAccess.ai handles that foundational part. We run a pipeline that continuously collects, normalizes, and version-controls the source material so it stays queryable. The day-to-day value is in having current, structured data that you can filter, join, and trend without rebuilding the context each time.
That matters because market-access data has edge cases, exceptions, and publication quirks that models regularly miss when they’re working from incomplete context.
Here’s a real example of failure using an out-of-the-box LLM setup. I asked ChatGPT: “How long did it take to get an Ontario formulary listing after pCPA negotiation for Nucala?” It pulled plausible dates from pcpacanada.ca and the Ontario formulary site, then produced a confident timeline. That’s pretty impressive but not totally accurate. The catch is that Exceptional Access products can be communicated through bulletins rather than appearing as standard listings on formulary.health.gov.on.ca, so the timeline was incomplete.
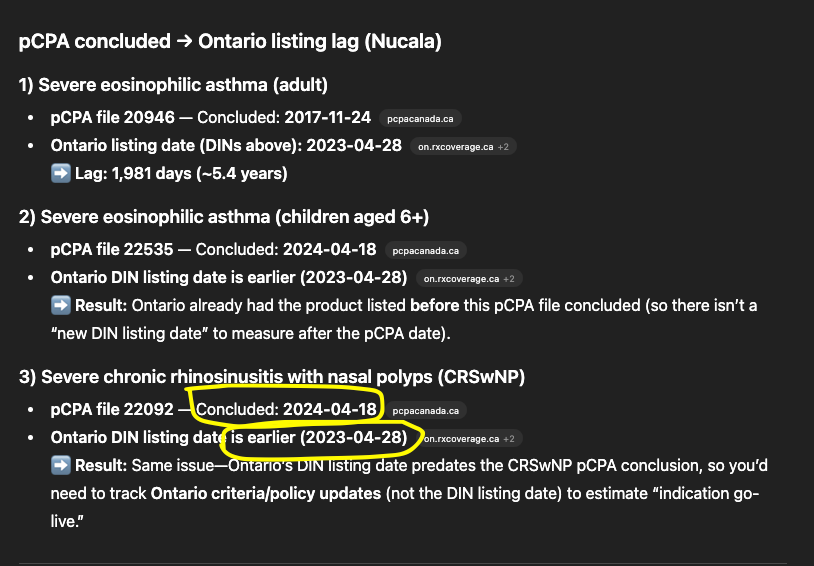
With RapidAccess.ai, we treat those exceptions as first-class data. We track which pathways use bulletins vs. standard listings, attach provenance to each milestone, and flag “missing-by-design” records so you don’t confuse an absence with a negative.

We do something similar inside our Insights Studio. Users build charts and dashboards by dragging fields onto a canvas, but the hard part is the field layer itself. We maintain a catalog of 35+ fields, including computed ones like price-reduction percentage, time-to-negotiation, recommendation conditions, and status transitions. Those computed fields are where the domain knowledge lives: the parsing rules, the definitions, and the transformations you’d otherwise have to reinvent in every analysis.
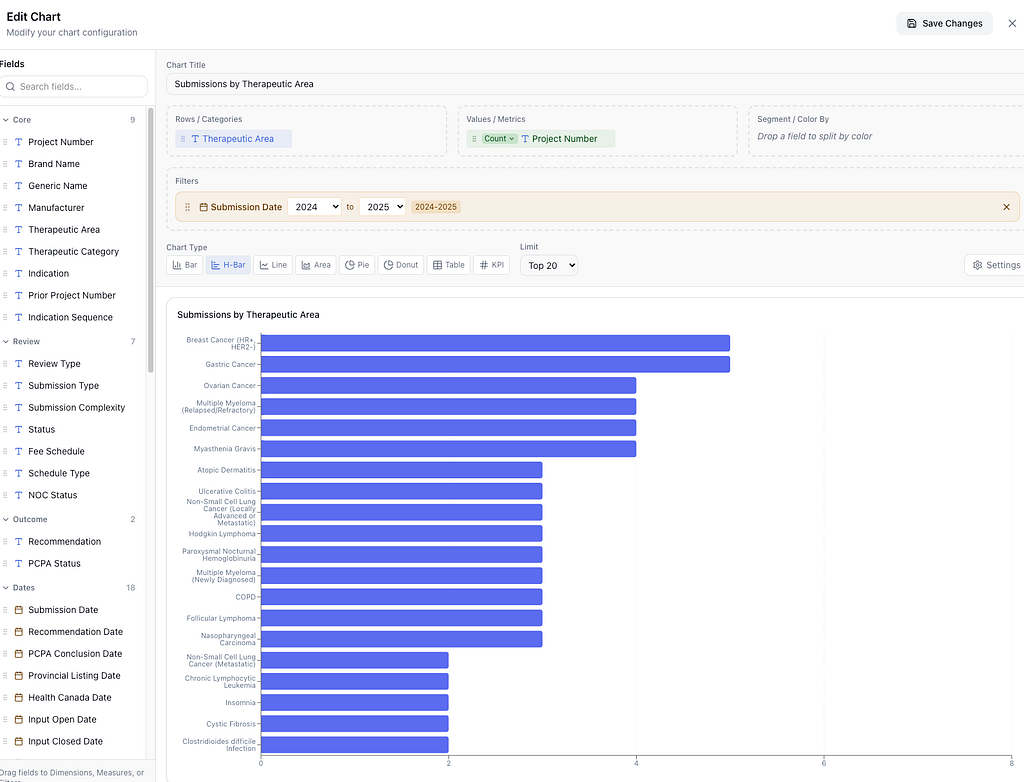
All of this changes the build-vs-buy question, but it doesn’t erase it. AI helps you get a prototype off the ground faster. Production is still production: pipelines break, sources change formatting, credentials expire, and somebody has to validate outputs when the stakes are real. If you’re doing it internally, you’re signing up for ongoing engineering work plus domain review, not just a weekend project.
RapidAccess.ai is the shortcut through that maintenance cycle. You get continuously updated market-access intelligence, domain rules that are already encoded into the data model, and the basics that teams tend to underestimate until they’re painful: multi-tenancy, authentication, data quality monitoring, and change tracking.
That’s why customers can’t “just use ChatGPT” for this category of work unless they also want to own the data product and the operational burden that comes with it.
We think smart SaaS products will still have a place in the enterprise tech stack for the forseeable future. It may look different, but we’re not ready to ring the alarms yet.
Can Your Customers Just Use ChatGPT (Or Claude)? was originally published in DataDrivenInvestor on Medium, where people are continuing the conversation by highlighting and responding to this story.



