Building an Evidence-First AI Copilot for AML Compliance
How I engineered a production-grade agentic system that can explain every material claim it makes.
 Rishikesh Yadav9 min read·Just now
Rishikesh Yadav9 min read·Just now--
Most AI demos in compliance look impressive for about three minutes.
Ask a general-purpose LLM to draft an AML case narrative and it will often produce something that sounds polished, authoritative, and completely unsafe for a regulated workflow. It may cite the wrong regulation, infer facts that never existed in the source data, or smooth over missing information with plausible language. In a bank, that is not a UX bug. That is an exam problem.
I built Comply AI around a stricter premise: the model should never be the source of truth. Its job is to reason over an already-validated body of evidence, not invent one.
That design choice ended up shaping the entire platform — from the ingestion layer and evidence graph, to the law database, casefile hashing, and analyst review workflow. The result is an evidence-first AML copilot that automates alert investigation while preserving what matters most in financial crime operations: traceability, reproducibility, and trust.
Why AML automation is harder than “just use an LLM”?
The operational pain is real. A mid-market bank analyst may spend 45 to 90 minutes on a single alert: pull customer KYC, inspect the triggering transaction, gather lookback aggregates, check sanctions hits, map the activity to the right citation, draft a narrative, and decide whether the case should be closed, escalated, or prepared for SAR filing.
That workload is repetitive, but it is not low-stakes. Every narrative can be questioned by internal QA, external auditors, or regulators. If an examiner asks why case #2847 was escalated, the institution needs more than a persuasive paragraph. It needs a chain of evidence.
This is exactly where naive AI fails. In regulated environments, a fluent answer is worthless unless every important statement can be traced back to a real source fact. So I treated the trust problem as the core systems problem.
The engineering rule was simple:
If the platform cannot prove a claim from a validated evidence snapshot, it should not say it.
That principle sounds narrow, but it drives several non-obvious architectural decisions:
- regulatory citations should never come from the model,
- evidence should be frozen before reasoning begins,
- missing data should be surfaced explicitly,
- and every model output should be tied to a logged invocation and a bounded pointer set.
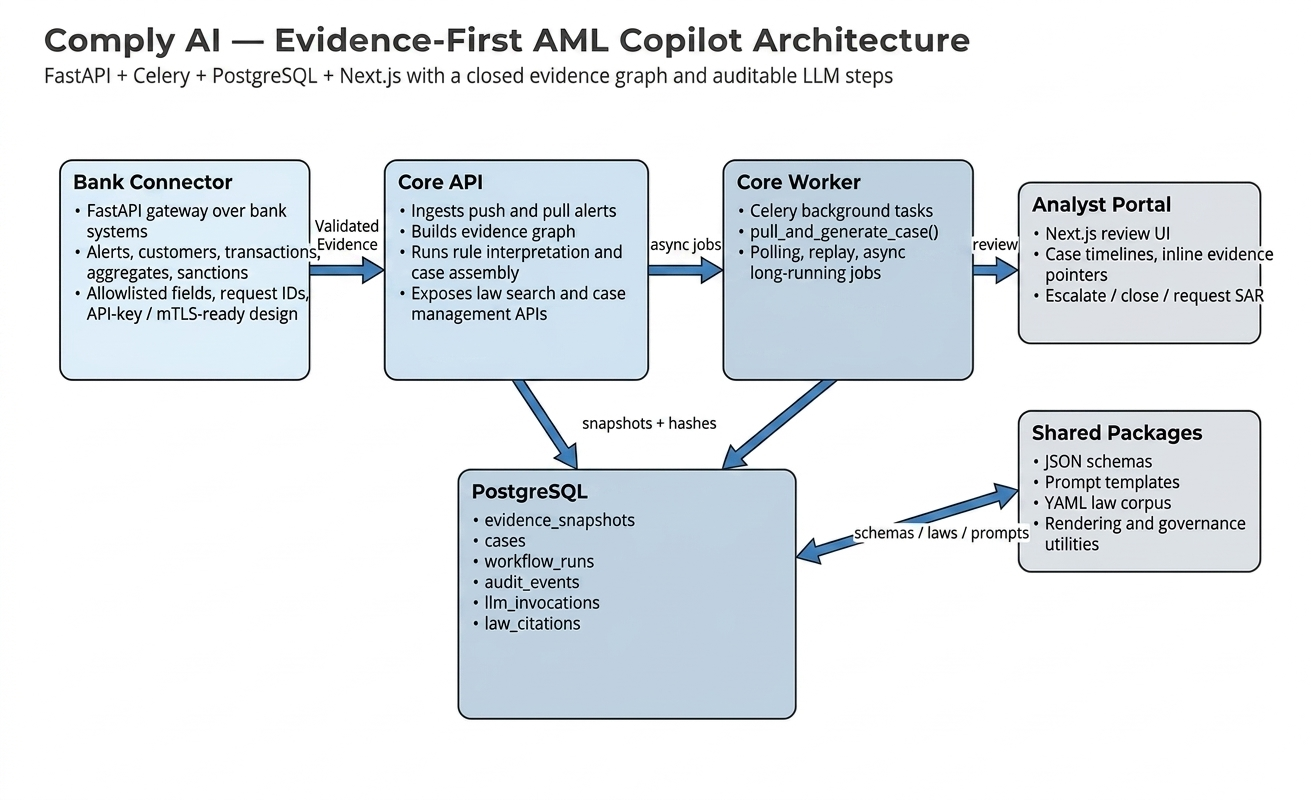
System Design
At the infrastructure layer, the system is split into four deployable services inside a monorepo.
1. Bank Connector (FastAPI)
This is the boundary layer between Comply AI and the bank’s data systems. In production, it wraps real customer, transaction, alert, aggregate, and sanctions sources. In development, it can run a full simulator so the rest of the pipeline is testable without bank access.
The connector does more than fetch data. It enforces an explicit field allowlist, validates payload shape, assigns request IDs, and prepares the integration surface for signed requests and mTLS-style deployments.
2. Core API (FastAPI)
This is the orchestration engine. It accepts alert events, coordinates evidence retrieval, triggers the agentic workflow, exposes case management APIs, and serves law-search endpoints for the analyst portal.
3. Core Worker (Celery)
Case generation is not a synchronous HTTP concern. Long-running workflows — evidence pulls, replay jobs, background polling, and case assembly — run in Celery workers so the platform can separate ingestion from processing.
4. Analyst Portal (Next.js)
The front end is not a chat window. It is a structured review system. Analysts see a generated casefile, the workflow timeline, inline evidence pointers, the law mapping, and the actions that matter operationally: close, escalate, or request SAR drafting.
This separation of concerns matters. It lets the product behave like a governed system rather than a single “AI endpoint.”
The real center of the platform: the evidence graph
The most important component in the system is not an LLM agent. It is `EvidenceService.build_evidence_graph()`.
That function is fully deterministic. For each alert, it retrieves:
- the alert payload,
- the customer KYC snapshot,
- the primary transaction,
- the lookback aggregates,
- sanctions hits when applicable,
- and the relevant regulatory citations from a local law corpus.
Those facts are assembled into a typed graph of nodes and edges, where each node gets a deterministic `evidence_pointer`. That pointer is the atomic reference used everywhere else in the platform.
A simplified node taxonomy looks like this:
```python
"ALERT"
"RULE_CONDITION"
"CUSTOMER"
"TRANSACTION"
"AGGREGATE"
"SANCTIONS_HIT"
"LAW_CITATION"
```Two separate hashes are then computed:
- a `source_payload_hash`, representing the upstream factual payloads,
- and an `evidence_hash`, representing the full graph built from that payload.
That distinction is critical. If the bank changes a customer record later, I can detect that the upstream data changed. If I want to replay the workflow on the original evidence, I can prove which exact evidence graph was used the first time.
Before the pipeline continues, the graph is validated against JSON Schema. If the connector returns malformed data, the run fails at the boundary. It does not limp into later stages and produce something that merely looks acceptable.
The workflow: agentic, but not unconstrained
Once the evidence graph is frozen, the platform runs a staged workflow that looks roughly like this:
The key idea is that the LLM never performs open-ended retrieval. It reasons over a closed, pre-validated input.
Stage 1: Fetch evidence
This stage is entirely non-LLM. It builds the graph, validates the source facts, and records the initial workflow state.
Stage 2: Commit the snapshot
The evidence snapshot is hashed and persisted. From this point onward, reasoning operates against a frozen record.
Stage 3: Interpret the rule
The first model call is the `RuleInterpreterAgent`. It receives the evidence graph as structured JSON and is asked to explain what condition triggered and why it matters. The prompt is intentionally restrictive:
- use only facts from the graph,
- attach evidence pointers,
- declare missing values as `”NOT PROVIDED”`,
- output JSON only.
That prompt design does not make hallucination impossible by itself. What matters is that the model is operating inside a system that limits what counts as a valid factual reference.
Stage 4: Build the casefile
The `CaseFileBuilderAgent` is where the platform starts to feel like a complete investigator workflow. But even here, most of the output is not model-generated.
I kept the majority of the casefile deterministic:
- complexity scoring,
- behavioral comparisons,
- reason codes,
- five-Ws style SAR preparation fields,
- data-gap manifests,
- transaction-pattern indicators,
- and rule evaluation tables.
The model is used only where language compression adds value: executive summary bullets and disposition framing.
That choice was deliberate. Deterministic analysis is easier to test, easier to explain to auditors, and easier to replay later. There is no reason to ask a model to compute a risk score or derive prior-alert counts when those can be expressed directly in code.
Guardrails that actually matter: closed evidence namespaces
One of the strongest anti-hallucination guarantees in the system is the evidence guard.
After the casefile is built, the platform walks every evidence pointer in the output and checks it against the set of real pointers in the graph. If a pointer is not present in that closed set, it is rewritten to “NOT PROVIDED”.
Conceptually, it looks like this:
```python
allowed = {str(node["evidence_pointer"]) for node in evidence_graph["nodes"]}
allowed.add("NOT PROVIDED")
```This is more important than prompt wording. Even if a model tries to invent an evidence pointer, the output normalization layer invalidates it. The only pointers that can survive are the ones created at graph-construction time from real connector responses.
That means the model cannot fabricate a claim and then fabricate a citation trail for it. The namespace is closed before generation begins.
Why I removed the model from the citation path
A lot of compliance tooling gets this wrong. It lets the model “help” with regulatory mapping. That is exactly where the risk surface expands.
In Comply AI, regulatory citations come from a curated local corpus stored as YAML and seeded into PostgreSQL. Matching is deterministic: bank, alert type, and triggered rule form the first pass, with controlled search fallbacks where necessary.
This gives two major benefits.
First, it makes old outputs reproducible. A casefile generated last quarter can be replayed against the law dataset that existed at that time, without relying on a live external source that may have changed.
Second, it removes citation invention from the model’s job description entirely. The LLM never gets to decide what law applies in the sense of generating a citation string out of thin air. It can only reason about citations that are already present in the evidence graph.
For regulated AI, that distinction is enormous.
Persisting the right things: evidence, outputs, and governance
To make the platform examiner-ready, I designed the data model around three concerns.
Operational state
`workflow_runs`, `alert_ingest_events`, and connector poll state capture what happened, when it happened, and how a given alert entered the system.
Evidence and outputs
`evidence_snapshots` persist the frozen graph. `cases` persist the generated casefile, rendered narrative, and the content hashes that identify the evidence and output versions.
Governance
`audit_events` capture actions by system actors, models, and humans. `llm_invocations` persist prompt IDs, versions, hashes, providers, model names, and request/response records.
This is the part many AI products bolt on later. I treated it as a first-class design surface from the start, because in compliance, “what happened?” is not a support question. It is the product.
Hashing for replay, immutability, and tamper evidence
A casefile is not just stored. It is content-addressed.
The system computes:
- `evidence_hash` for the immutable evidence graph,
- `casefile_hash` for the final case representation.
When an analyst takes an action — close, escalate, request SAR — the casefile hash is recomputed and persisted again. That gives the platform a tamper-evident lifecycle, not just a row with mutable JSON.
The bigger advantage is replay. Given the same stored evidence snapshot, I can rerun the case-generation pipeline and compare the new output to the original. That makes debugging, QA, and regulatory review fundamentally easier, because the question becomes: did the system behave consistently on the same evidence?
That is the kind of question you can only answer when immutability is part of the architecture.
Ingestion and deduplication: building for messy real banks
Real banking infrastructure rarely gives you one clean event stream. So the ingestion layer supports:
- background polling,
- push webhooks,
- and manual pull-based recovery.
All three paths converge through a shared dispatch flow with a unique constraint on the event identity. In practice, the deduplication strategy is database-backed: if the same alert arrives from multiple channels, the duplicate insert fails and the later path is dropped.
This sounds like a small implementation detail, but it is exactly the kind of real-world reliability work that determines whether an AI system can survive outside a demo environment.
Testability without an API key
Another design decision I care about deeply: the entire pipeline runs locally without requiring a live model provider.
The platform uses an `LLMProvider` interface and defaults to a deterministic mock provider in local development and tests. That means I can test:
- evidence graph construction,
- schema validation,
- case assembly,
- hash generation,
- workflow logging,
- and analyst action flows
without depending on an external API.
That speeds up iteration, makes CI reliable, and forces the architecture to be cleanly separated. If your AI system only works when a live model is attached, you usually have not isolated the intelligence layer from the core product logic.
What this project says about building AI systems from scratch
What I wanted to prove with Comply AI was not just that I could wire an LLM into a banking workflow. I wanted to design an AI-native system where:
- the data contracts are explicit,
- the orchestration is production-minded,
- the failure modes are intentional,
- the governance model is built in,
- and the model is treated as one component in a larger reliability architecture.
That required building across the stack:
- FastAPI services for integration and orchestration,
- Celery workers for asynchronous execution,
- PostgreSQL for evidence, case, and governance persistence,
- Next.js for analyst review workflows,
- JSON Schema for hard boundaries,
- deterministic evidence graphs and pointer systems,
- hash-based replay and immutability,
- and a provider abstraction so model choice does not leak into core product behavior.
The end result is not “an LLM app.” It is a traceable decision-support system for a regulated environment.
Final thought
There is a broader lesson here that applies well beyond AML.
In high-stakes domains, the hardest part of AI is not generation. It is building the architecture around generation so that outputs remain explainable, bounded, and reviewable under pressure.
That is what I optimized for here.
Instead of asking, “How do I get a model to sound smart?”, I asked, “How do I make sure the system can prove what it says?”
That single shift in perspective changes almost everything about how you design production AI.


