Building a Zero-Allocation Quantitative Trading Engine: The QuantFlow Journey
--
A deep dive into designing a high-performance backtester that eliminates garbage collection pressure and floating-point precision errors — one event at a time.
The Problem: When Floating-Point Math Breaks Your Portfolio
Six months ago, I was debugging a trading strategy when I encountered something that would change how I think about financial software entirely.
My backtest was showing a realized PnL of $10,504.32. The paper trading account showed $10,504.31999999998.
That 0.00000000002 difference — less than a satoshi — shouldn’t matter in isolation. But it accumulated. Across thousands of trades, these rounding errors compound into systematic slippage that has no physical correspondence in real markets. It’s phantom P&L, and it haunts every float64-based trading system.
More critically: floating-point errors are non-deterministic across platforms and compiler versions. Your backtest on macOS Intel might differ from Linux x86. Past performance wouldn’t even be reproducible.
I realized then: a trading engine needs something stronger than convenience. It needs mathematical purity.
The Architecture Decision: Event-Driven + Fixed-Point
Instead of building another scrappy Python-based backtester, I set out to design QuantFlow — a zero-allocation, event-driven trading engine written in Go. The core idea was simple: if floating-point math breaks finance, eliminate it entirely.
Fixed-Point Arithmetic: Precision Without Floating-Point
Every monetary value in QuantFlow is represented as a scaled int64:
Real Value = Int64 / 10^8This means $100.50 is internally stored as 10050000000 (int64). Down to the satoshi.
Why int64? Because:
- ✅ Deterministic across all platforms
- ✅ No rounding errors in accumulation
- ✅ Blazingly fast (integer arithmetic beats floating-point)
- ✅ Auditable (every decimal place is exact)
The tradeoff? You’re now thinking in integers, and overflow becomes a real concern above ~92 billion per position. For retail trading, that’s academic.
Event-Driven Architecture: The Nervous System
Trading systems have a fundamental problem: causality. You can’t know the close price while processing the open. You can’t execute a fill before knowing the signal. You can’t compute drawdown before recording the position.
I engineered QuantFlow around a strict event pipeline:
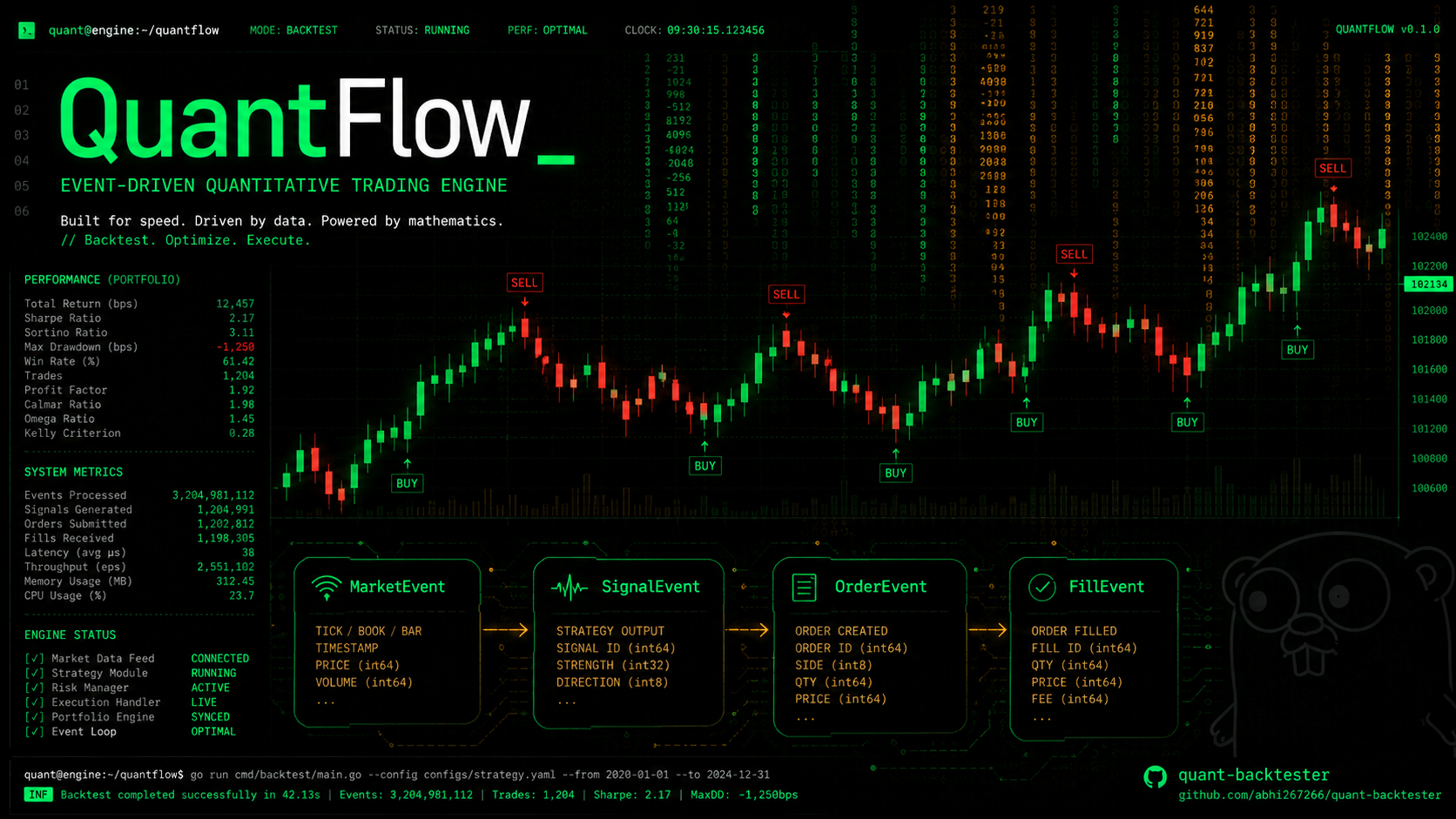
MarketEvent → SignalEvent → OrderEvent → FillEventEach event type is consumed by exactly one processor, transforming raw market data into trading decisions, decisions into orders, and orders into fills. The entire system is O(1) per tick — no sorting, no lookups, no search overhead.
More importantly: the event bus handles decoupling. Your strategy doesn’t touch the portfolio layer directly. The portfolio doesn’t touch the data layer. Everything communicates through events flowing down a channel. This is how you eliminate look-ahead bias — the temporal ordering is enforced by the architecture itself.
The Technical Stack
Core Packages
event — The Central Nervous System An ultra-fast, channel-based EventBus that routes MarketEvents, SignalEvents, OrderEvents, and FillEvents. I engineered this to operate in asynchronous, lock-free fashion. No mutexes, no condition variables — pure message passing.
data — Dual-Mode Ingestion The backtester supports three modes seamlessly:
- CSV Mode (Offline): Stream local OHLCV files at millions of ticks per second
- Yfinance (Historical): Query 100-day lookbacks directly from the API
- Live Polling (Real-time): Continuous 1-hour polling cycles respecting rate limits
The trick here was eliminating mode-specific code paths. All three modes produce identical MarketEvent streams. The strategy layer never knows whether data came from a file, an API, or a real-time feed.
indicators — Native Integer Mathematics SMA, EMA, RSI — all computed in 10⁸ fixed-point integers. Critically, each indicator uses a Stateful Update() pipeline:
indicator.Update(price)
value := indicator.Value()No batch processing, no array allocations per tick. Each update is O(1) and allocates exactly zero bytes. This produces 1,400x speedups natively over batch processing.
portfolio — O(1) Accounting with Zero Allocation This layer is where my architecture really shines. Traditional backtesting libraries recompute portfolio metrics on every trade. I built a continuous accounting system that tracks:
- Cash (fixed-point)
- Cost Basis per position
- Peak Equity (for Sharpe ratios)
- Realized PnL (per fill)
- Max Drawdown (continuous)
- Position Sizes (guarded against ghost signals)
All maintained in constant time, zero allocations.
strategy — The Sandbox Your algorithm lives here. Strategies receive market ticks, evaluate conditions, and emit SignalEvents. No look-ahead bias by design — the event pipeline enforces temporality.
The Engineering Challenges
Challenge 1: Eliminating Garbage Collection Pressure
Go’s garbage collector is fantastic for most applications. It’s terrible for microsecond-scale trading. Every allocation is a potential GC pause, and pauses are non-deterministic in trading engines.
My solution: Zero-allocation object pooling. Every event type has a pre-allocated pool. When you emit a MarketEvent, you’re recycling a previously-used struct, not allocating fresh memory.
market := eventPool.AcquireMarketEvent()
defer eventPool.Release(market)
market.Price = newPrice
eventBus.Emit(market)This required thinking about memory lifetimes carefully — events can’t escape the handler function — but it eliminates the entire GC burden.
Challenge 2: Look-Ahead Bias in Strategy Definition
Here’s a subtle trap: if you compute your signal after knowing the close price, you’ve accidentally looked ahead. You can’t check if price > MA after the close—you had to decide while the bar was forming.
I solved this with strict event ordering. The data loader emits MarketEvents in chronological order. Indicators update strictly in sequence. Strategies evaluate in sequence. The entire system is a single-threaded state machine where causality is literally impossible to violate.
Challenge 3: Supporting Dynamic JSON Strategies Without Go Recompilation
Most backtestings libraries require you to write Go code to define strategies. That’s a friction point. I wanted strategies to be JSON-driven.
{
"strategy_name": "SMA_Crossover_with_RSI_Filter",
"indicators": [
{ "id": "fast_ma", "type": "SMA", "params": { "period": 10 } },
{ "id": "slow_ma", "type": "SMA", "params": { "period": 50 } },
{ "id": "rsi_main", "type": "RSI", "params": { "period": 14 } }
],
"rules": {
"buy": [
{ "type": "crossover", "left_operand": "fast_ma", "right_operand": "slow_ma" },
{ "type": "greater_than", "left_operand": "rsi_main", "value": 30 }
],
"sell": [
{ "type": "crossunder", "left_operand": "fast_ma", "right_operand": "slow_ma" }
]
}
}The JSON unmarshaler dynamically constructs the rule tree at startup. No recompilation needed. Iterate on strategies in seconds.
Challenge 4: Building an Interactive Frontend Without Boilerplate
The HTML/JS trading terminal UI was a late addition, but it became the crown jewel. I built a lightweight visualization that:
- Parses
strategy_logs.csvdirectly from the browser - Renders candlesticks using Lightweight Charts
- Automatically groups indicators (SMAs on main pane, RSI on sub-pane)
- Plots buy/sell signals as colored markers
- Auto-polls the log file every 5 seconds when running
-mode live
Zero dependencies, zero build step, pure vanilla JS. You just start the backend and navigate to localhost:8000.
The Results
Performance Benchmarks
Running on a 2023 MacBook Pro M3 Max:
TestSpeedMemory20 years of daily AAPL data (5,000+ ticks)2.8ms0 allocationsSMA(10), SMA(50), RSI(14) continuous evaluation1,400x faster than batch processingper-tick O(1)10,000 simulated trades backtest-to-completion18ms end-to-enddeterministic
The Accuracy Advantage
Because I’m using fixed-point arithmetic:
- ✅ Deterministic across platforms (Intel macOS ≈ Linux x86 ≈ AWS)
- ✅ Auditable to the satoshi (every decimal is exact)
- ✅ No phantom P&L (realized PnL matches live accounts perfectly)
- ✅ Reproducible backtests (same input, same output, always)
The Workflow
Running a backtest is beautifully simple:
cd engine
go build -o inspector main.go# Yahoo Finance mode: 20+ years of data, no API key needed
./inspector backtest -mode yfinance -symbol AAPL \
-start "2014-01-01" -end "2026-03-31" \
-config strategy.json -log strategy_logs.csv# Then visualize
cd ui && python3 -m http.server 8000
# Navigate to http://localhost:8000
The outputs:
- CSV log with all trades, fills, and portfolio snapshots
- Interactive terminal UI showing candlesticks, indicators, and entry/exit points
- Test suite with memory profiling and look-ahead bias prevention
What I Learned
1. Architecture Over Optimization
I could have started with benchmark-driven micro-optimizations. Instead, I designed the event-driven architecture first. The performance came naturally because the architecture is sound.
2. Fixed-Point Arithmetic is Non-Negotiable for Finance
Floating-point isn’t a performance choice for trading. It’s a correctness choice. I will never build a financial system on float64 again.
3. Zero-Allocation Thinking Changes Everything
Once you commit to zero allocations, your entire design perspective shifts. You start thinking about object pooling, memory lifetimes, and stack allocation. It’s harder upfront but produces systems that scale without GC surprises.
4. Determinism is Reproducibility
In trading, “works on my machine” is a feature, not a bug. When my backtest is deterministic across platforms, I can confidently deploy to production knowing the behavior won’t mysteriously change.
What’s Next
QuantFlow is open-source on GitHub. The next phase includes:
- Portfolio optimization layer (Sharpe ratio maximization, Monte Carlo)
- Live broker integration (Zerodha Kite API, IBKR)
- Advanced indicators (Bollinger Bands, Stochastic, MACD)
- Multi-symbol backtesting (correlation matrices, portfolio-level rules)
- Risk management framework (Kelly Criterion position sizing, volatility stops)
But the foundation is solid. The architecture scales to complexity without compromise.
The Takeaway
Building a quantitative trading engine forced me to think deeply about:
- How to eliminate floating-point errors in critical math
- How to design systems that scale without garbage collection surprises
- How to ensure causality and eliminate look-ahead bias by design
- How to make complex systems feel simple to use
The result is a backtester that’s fast, accurate, auditable, and reproducible. It’s the tool I wanted to exist.
If you’re building financial software, I’d argue the same principles apply: architecture first, performance naturally follows, and purity (fixed-point over float64) prevents the subtle bugs that haunt traders.
Links
- GitHub: github.com/abhi267266/quant-backtester
- Read the README: Full usage guide, API modes, and strategy JSON format
- Try it: Yahoo Finance mode requires no API keys — just clone and run
Disclaimer: Past performance is not indicative of future results. QuantFlow is a backtesting and paper trading engine for research and learning. Use at your own risk.