Automated Instruction Revision (AIR): A Comparison of Task Adaptation Strategies for LLM-based agents

Modern LLM-based agents are becoming central to workflows that require planning and automation, tool use, and repeated decision-making, but their performance is fragile in environments that change over time. New data arriving in production often is different from the examples seen during agent development, additionally creating data and concept drift that can quickly make existing prompts outdated. The problem is intensified by model churn: organisations increasingly migrate between foundational models and versions, each with different strengths, weaknesses, and instruction-following sensitivity. In this setting, initial instructions become difficult to maintain because even small changes in the underlying model can alter the agent’s behaviour.
Fine-tuning is not always the best practical solution; it demands hosting or computing budget, monitoring, and strong safeguards to avoid degrading general knowledge, safety, or alignment. It can also fragment systems into many specialised fine-tuned models across nodes or tasks, which increases operational complexity. At the same time, LLM-based agents often need continuous or periodic expert support to diagnose failures, revise instructions, and keep behaviour aligned with dynamic requirements/data. This dependency on human intervention slows adaptation and makes scaling brittle when many agents or workflows must be maintained simultaneously.
The case for automated instruction revision
Automated prompt and instruction revision methods offer a more structured alternative by updating agent behaviour directly from observed task performance and feedback. Such methods can reduce the need for manual re-engineering while keeping adaptation lightweight, repeatable, and easier to deploy across changing environments. They also improve transparency by making the revision process explicit, so it becomes clearer what was changed, which observations influenced the update, and which samples were excluded because they were contradictory or unsupported. For these reasons, automated instruction revision is emerging as an important direction for keeping LLM-based agents reliable, adaptable, and operationally manageable in modern agentic systems.
Related work
Existing approaches to automated instruction revision span a spectrum from lightweight prompt selection to full parameter adaptation. DSPy BootstrapFewShot focuses on automatically selecting high-quality in-context examples from labelled data, effectively improving performance without modifying the original instruction itself. More advanced prompt optimisation methods, such as DSPy MIPROv2, treat instruction design as a search problem, jointly exploring candidate instructions and demonstrations to identify high-performing prompt configurations.

Extending this idea, DSPy GEPA introduces a reflective loop with a stronger teacher model that iteratively revises instructions based on execution feedback, enabling more informed and adaptive improvements.
Finally, TextGrad frames instruction revision as a continuous optimisation process in text space, updating the prompt through gradient-like signals derived from task loss while keeping the underlying model fixed.

Together, these methods illustrate different trade-offs between simplicity, interpretability, computational cost, and adaptability in automated instruction revision. There are other methods like CoachLM and Prewrite, but to sum up, the literature reveals two main tendencies. The first is the movement from manual prompt writing toward automated optimisation of prompts, examples, and full LLM pipelines. The second is the growing interest in interpretable decision structures such as rules or trees. Our work lies at the intersection of these directions: like prompt optimisation methods, it seeks to automatically improve LLM behaviour, but like tree-based approaches, it emphasises the discovery of explicit and reusable decision logic.
What AIR does differently
Our proposed Automated Instruction Revision (AIR) method is the same data-driven prompt adaptation pipeline that learns explicit task guidance from labelled examples instead of relying on continuous manual prompt engineering. But unlike the described methods, the central idea is to transform supervised task data into a compact set of task-specific decision rules, convert these rules into an executable system prompt, and iteratively refine them using additional sampled cases from the training set. This approach helps to reach comparable/top results with computational budgets that are times lower. If you’re interested in achieved results, please proceed to the RESULTS section directly.
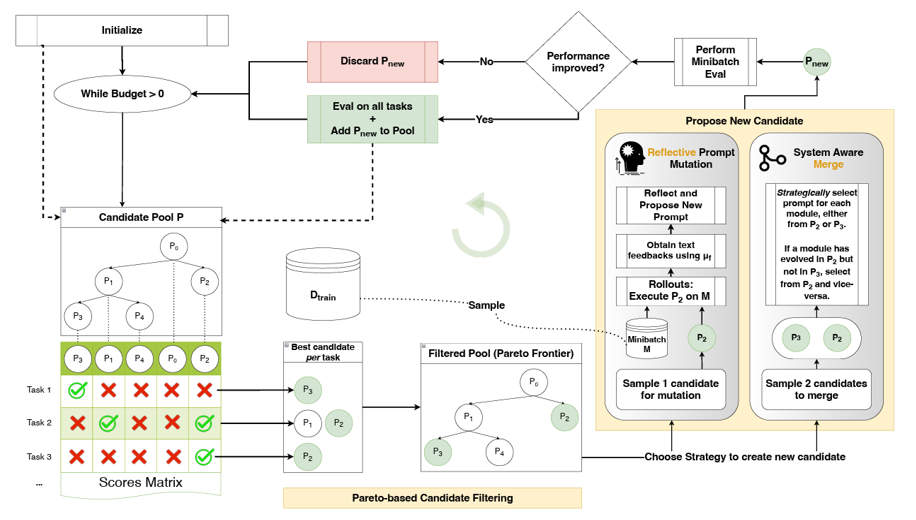
The AIR pipeline
The AIR pipeline proceeds through clustering, rule induction, rule aggregation, and targeted refinement. Starting from labelled training data, it constructs an executable instruction set in the following stages.
So the very first task is to create your init prompt, which can be pretty simple, like “Please, classify/answer according to some primary rule/instruction…”. In our benchmarking, we call this the initial prompt performance. Then we need to process our dataset: as stated above, here we need some feedback or supervision, thus it is not a self-learning approach, similar to comparison improvement techniques. So here AIR first maps each dataset into canonical input and output columns and computes embeddings for both sides (independent and target) of the supervision signal. This creates a uniform representation across tasks and provides the structure used later for clustering and local comparison.
Then we should understand how to sample our data and form batches. This task is important because we can’t overload context with the entire dataset (even if it fits 1M tokens or any future RoPE-like improved size). Also, when we feed, for example, some sorted or one-class or fully randomly formed batch, it won’t help us efficiently to form any semantic decision boundaries. Our idea is to make some initial semantic grouping of the inputs, but take different targets (or mimic the targets' distribution in the general sample). This can be achieved by clustering using a few objectives (input similarity, target variety). The number of clusters is treated as a hyperparameter and is set to the default value of 5 in our experiments. Finally, AIR performs a repair step (automated blind clustering is not always perfect for different tasks (like discrete classes vs enhanced answers)) that redistributes samples from clusters containing only one output class to nearby alternative clusters. This encourages groups to remain semantically coherent while still preserving output variation that is useful for distinguishing behaviour.
Then comes the rule learning part, which consists of a few steps. Firstly, after sampling balanced batches, these batches are passed to a reasoning model with an instruction to infer a small number of rules of the form “if condition on the input, then output action or pattern.” The purpose is not free-form explanation, but extraction of compact decision-boundary rules that distinguish competing output behaviours within the same semantic neighbourhood. After this, we need to aggregate and compile the rules into an executable prompt:

Because rule induction is repeated across clusters, the initial rule pool is usually large and partially redundant. AIR therefore applies a dedicated LLM-based rule-compilation stage. In this stage, a reasoning model receives the induced rules and, following a constrained compiler prompt, groups rules with semantically similar THEN actions, identifies the shared structure of their IF conditions, merges complementary signals, removes lexical noise, and preserves only the exclusions needed to avoid cross-rule collisions.
Aggregated rules produced by the above step are then concatenated with the task description to form a structured final prompt that instructs the model to follow the decision process encoded in the rules. AIR also creates a traced variant of this prompt that asks the model to return both the final prediction and the identifiers of the applied rules, enabling later refinement.
Talking about refinement, this also appeared in several of the mentioned approaches, and it is almost about the continuous improvement process. Here, rather than using the aggregated rules as final, AIR re-evaluates them on newly sampled examples and records predicted outputs, applied rule identifiers, and task metric values. For each rule, the pipeline separates participating cases into mistakes, where the prediction was incorrect, and anchors, where the prediction was correct according to the provided metric. Small refinement batches built from these two sets are then sent back to the reasoning model, which is asked to make the smallest necessary local revision to the current rule. In this way, AIR updates individual rules while attempting to preserve behaviour on successful anchor cases:

After refinement, the updated rules are assembled into the final system prompt used for downstream evaluation. A very important note here is that the final step will be used as the major part of the agent's continuous improvement loop, especially without the involvement of AI specialists.
In this way, AIR derives task-specific instructions from labelled examples through rule induction, aggregation, and revision:

Performance and benchmarks
This section describes the benchmark suite, the compared adaptation methods, and the models used in our experiments. The evaluation is designed to support a controlled comparison of prompting, retrieval-based adaptation, prompt optimisation, and fine-tuning under a shared task-specific setup.
We evaluate AIR on a deliberately diverse benchmark suite chosen to reflect different sources of adaptation difficulty rather than a single task family. The suite spans remapped-label classification, closed-book factual QA, schema-constrained extraction, PII identification, and event-order reasoning. The comparison is made via classical cross-validation using train, development, and test splits, with task-specific metrics (typically, the higher the better). The test set, which was outside the training and refining/tuning, was used for the final evaluation and is present in our resulting benchmarking tables.
Let's then review our tasks and datasets, which partially appear in different benchmarks and can be used for our evaluation. The first one is the example of a classification task, which typically can be solved by many different and proven simpler ML-based approaches rather than using LLMs (at least to decrease complexity/computing and increase the consistency and transparency), but sometimes the dependencies can be very close to huge variety of different semantics/knowledge behind, where the LLM-based agent with structured output may be the right way. Here, we used real customer support requests collected from Twitter, based on the Customer Support dataset (sample example on Kaggle), and constructed an 8-class benchmark by selecting requests addressed to eight companies. The main problem was that this is not a complicated task for LLM, which has a background at least around the companies that appeared in the dataset (or rather has seen the dataset during training/caught keyinfo distillation, etc.). Thus, firstly, we’ve removed any explicit company mentions and other direct lexical cues and reassigned the output labels so that each company is consistently mapped to a different description rather than its original one.

The final dataset is balanced across the selected companies, and performance is measured with exact match (accuracy).
Another, less discrete task is closed-book question answering, where we built a benchmark from Ever Young by Alice Gerstenberg and created question-answer pairs that must be answered without providing the full source text at inference time. The benchmark is intentionally designed so that the relevant source material is unlikely to be part of the model’s pretrained knowledge, but such leakage is valid for all LLM-based approaches, which we are benchmarking and is not decisive, which you’ll see from the evaluation.

To evaluate outputs, we use an LLM-as-a-judge rubric with four dimensions: correctness, completeness, absence of hallucination, and focus, each scored on a 0/0.5/1 scale (each interval has described decision boundaries, the same as for other tasks below, where there are such stochastic native measurements), with the final score defined as the average of the four subscores.
For information retrieval, we use campaign-finance filings for Philadelphia elections from the City of Philadelphia Campaign Finance Reports source, containing transaction-level records for contributions, expenditures, and debt. Each example is transformed from a structured table row into a raw CSV-style string consisting of a header and one data line, and the columns are randomly shuffled. This means the model must first reconstruct the field mapping before it can find and extract the requested outputs (this is not the ETL-related or data extraction tasks). In addition to recovering directly stated fields, the model must infer two derived labels: candidate_relationship, which categorises how the donor relates to the candidate, and contribution_context, which combines donor type and contribution size into labels.

Performance is measured as average exact match across the two target fields (approx MAP).
As we stated, we’ve tried to add different tasks and benchmarks to provide an overview of existing and proposed improvement approaches from as many possible perspectives. And the next task is PII extraction. Here, we used PUPA (Private User Prompt Annotations), a benchmark derived from real WildChat user-assistant conversations that contain explicit PII leakage.

In our benchmark, we isolated only the annotation component and converted it into a pure extraction task: given user_query, the model must output the gold pii_units directly, without rewriting, redaction, or response generation. Evaluation is performed with an entity-level exact-match F1 score.
For event logical reasoning, we adopt the Event Logic Reasoning subset of BizFinBench.v2. Each example describes a finance-related scenario involving multiple market events, and the task is to recover their correct logical order, either temporally or through cause-and-effect structure. The benchmark is intended to test whether this ordering logic can be induced through prompting, transferred from similar retrieved examples, or absorbed through fine-tuning.

The output is a compact event-index sequence, for example, “2,1,4,3,” rather than a free-form explanation. Performance is measured with an exact match.
We compare AIR against a set of adaptation strategies (partially listed at the beginning as related approaches) implemented within a shared task-specific workflow across our benchmarks. All methods start from the same manually written task instruction and use the available labelled training data, but they differ in whether they adapt the prompt, retrieve examples, or update model parameters.
- Initial prompt baseline. The model is evaluated with the manually written task prompt only, without retrieval, optimisation, or parameter updates. This baseline measures the performance of direct zero-shot prompting with human-authored instructions.
- KNN-based prompting. For each test example, we retrieve (this step is similar to the corresponding one in the RAG pipelines, which nowadays is probably more known for non-DS/AI/ML specialists and business), similar training samples, and append them as in-context examples to the initial prompt. This baseline tests whether instance-level adaptation through dynamic example selection is sufficient without modifying the instruction itself.
- DSPy BootstrapFewShot. DSPy automatically compiles a few-shot prompt by sampling labelled training examples and retaining demonstrations that satisfy the task metric. This yields an automatically selected demonstration set while keeping the base instruction fixed.
- Fine-tuning. We fine-tuned the base underlying foundation model (GPT family, as proposed in other improvement papers — described below after this section) on the training datasets using chat-formatted supervision constructed from the same initial system prompt, the task input, and the target, and the resulting model is evaluated on the test dataset. This baseline represents parameter adaptation rather than prompt-only adaptation.
- DSPy MIPROv2. MIPROv2 is used as a prompt optimisation baseline without a separate teacher or reflection model. In our experiments, it is run with DSPy’s auto=”medium” budget and task-specific limits on bootstrapped and labelled demonstrations, which are chosen separately for each benchmark. It jointly searches over instruction candidates and, when enabled, demonstration candidates to find a high-performing compiled prompt.
- DSPy GEPA. GEPA is used as a reflective prompt optimiser with the same auto=”medium” budget, but unlike MIPROv2, it relies on a separate reasoning model as a teacher for reflection (in AIR, we called the reflection conducted in a different way as refinement). So, the GEPA algorithm receives task-specific textual feedback through the metric and uses the teacher model to revise candidate instructions based on execution traces and validation-time search.
- TextGrad. TextGrad treats the system prompt as an optimizable text variable while keeping the model parameters fixed. In our experiments, we run one epoch over the full training set; within each minibatch, per-example losses are summed into a single minibatch loss, which is then used to update the prompt. This baseline, therefore, represents iterative text-space optimisation of the initial instruction.
- AIR. AIR induces explicit task-specific rules from labelled examples, aggregates them into a compact rule set, and refines them iteratively before assembling the final prompt.
Across this benchmarking, we used gpt-4.1-mini-2025–04–14 as the base task model for evaluation, at least because the GPT family was proposed and used in the described existing methods. This model is also used for the initial prompt baseline, KNN-based prompting, DSPy BootstrapFewShot, MIPROv2, and the final prompt evaluation in AIR, and it also serves as the starting point for fine-tuning. For methods that require a stronger auxiliary model for reflection or instruction refining/revision, we use gpt-5–2025–08–07 as the teacher model in GEPA, TextGrad, and AIR. In AIR, we additionally use text-embedding-3-small to compute input and output embeddings for clustering and rule induction. For the closed-book question answering benchmark, the LLM-as-a-judge metric uses gpt-5.1 as the judge model.
Results
This section reports the quantitative results for all compared methods across the five benchmark tasks. In addition to the task metric, each table includes the token usage reported in the original experiment slides, separating training-time token usage by model role and inference-time token usage for the base model.
Below is the first table showing the classification results. GEPA achieves the highest score, while AIR remains very close and also surpasses fine-tuning. This pattern suggests that, once brand priors are removed, the task behaves less like ordinary text classification and more like learning a remapped latent label system, where explicit prompt-level instruction discovery can be highly effective. Please also compare the computational budgets (or tokens used), which are quite high for DSPy/TextGrad families.

The closed-book QA results in Table 2 show different problem settings. KNN clearly performs best, while most prompt-optimisation methods fail to improve over the initial prompt. This shows that the benchmark is dominated by source-specific knowledge injection rather than by generic reasoning or procedural instruction improvement.
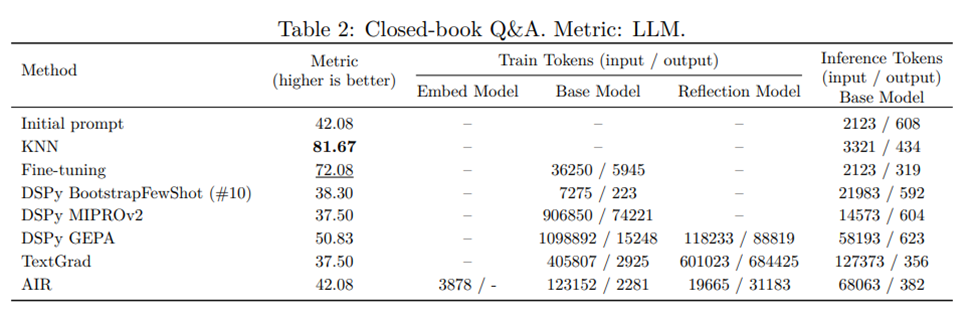
Table 3 shows that fine-tuning is dominant on the information retrieval task:

This is consistent with the structure of the benchmark: before performing extraction, the model must first reconstruct the field mapping from shuffled CSV-style rows. AIR performs substantially worse here (the same as other instruction revision methods), due to the difficulty of capturing this task through compact local rules alone.
The PUPA results in Table 4 again favour fine-tuning, with MIPROv2, AIR, and GEPA forming a second tier. This pattern suggests that the benchmark rewards not only general PII detection, but also adherence to dataset-specific annotation habits. AIR remains competitive with GEPA, but does not match the best parameter-adaptation result.
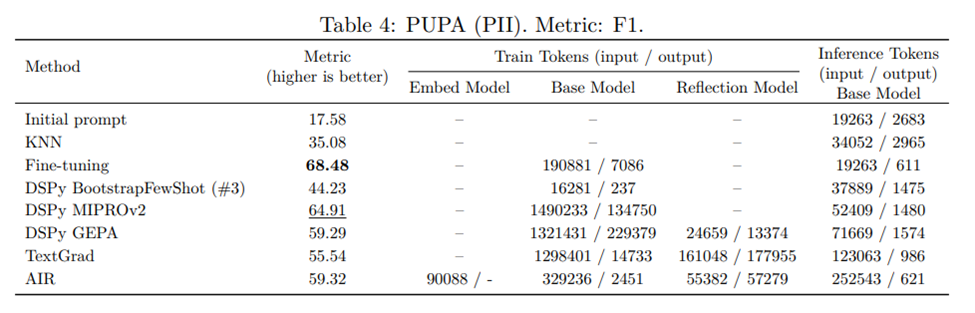
Note: In the source results, AIR on PUPA was terminated after 8 steps, including 5 consecutive steps with no improvement, using a batch size of 3.
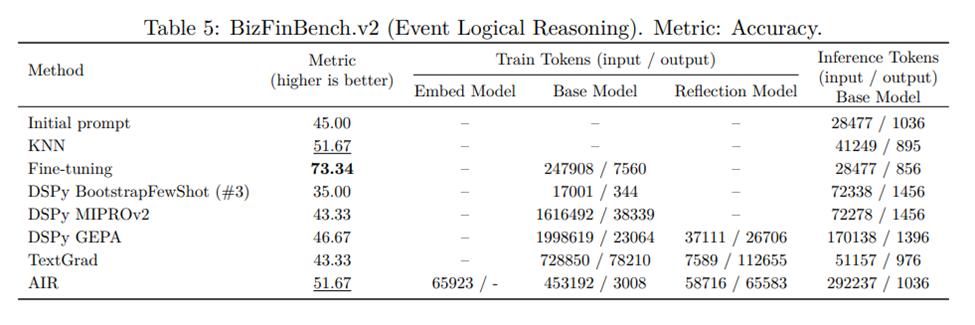
Finally, Table 5 shows that fine-tuning again performs best on event logical reasoning. The relatively strong initial-prompt score suggests that the base model already has some latent capability for financial event ordering, while fine-tuning appears to stabilise how that reasoning is mapped into the required output sequence. KNN and AIR both provide moderate gains, but neither approaches the fine-tuned model:
Conclusions
AIR is intended to provide several practical advantages. First, it is interpretable: the learned adaptation is represented as readable instruction text rather than hidden inside parameter updates. Second, it can support rule-level inspection and revision: individual rules can be examined and modified without changing model weights. Third, the pipeline preserves intermediate artefacts that can help analyse how the final prompt was constructed. Fourth, it reduces manual effort by automating a process that would otherwise require a person to inspect the data, identify recurring patterns, and summarise them as explicit rules. Fifth, the computing budget is quite moderate in comparison to other methods.
At the same time, AIR has important limitations. Its core assumption is that useful task behaviour can be guided by natural language or semantic rules. When labels are inconsistent, examples are noisy, or correct decisions depend on latent patterns that are difficult to verbalise, rule induction may become unstable. AIR can also suffer from rule interaction effects: a locally beneficial instruction may conflict with others after aggregation, and repeated revisions may reduce clarity instead of improving it.
The above benchmarking results do not support a single universal winner across all benchmarks. Instead, they show that different methods are strongest under different task conditions. Retrieval works best when the task is dominated by source-specific knowledge, fine-tuning is strongest when the task depends on stable dataset-specific mappings or output conventions, and instruction-based adaptation is most competitive when the target behaviour can be expressed as explicit decision rules. Within this picture, AIR occupies a clear practical niche. It does not win on every benchmark, but it remains especially competitive on tasks where the target behaviour can be captured as reusable rules within the optimised computational budget. This makes AIR attractive in settings where interpretability is important, and some loss relative to the best task-specific method is acceptable.
Another important point is that the compared adaptation methods still rely on a separate search or optimisation stage to identify a strong task-specific solution. When the data changes, this process may need to be repeated rather than updated incrementally. In principle, AIR may offer an advantage here, since new data could potentially be incorporated by extending or refining the rule set instead of rebuilding the adaptation from scratch. However, this possibility was not evaluated in the present experiments and remains a direction for future work.
For these reasons, we treat AIR not as a universal solution to task adaptation, but as a structured and interpretable option for settings in which task behaviour can be captured, at least in part, by explicit instruction rules derived from supervision.
Building LLM-based agents that need to keep up with changing data? Talk with our experts.
Do you have questions about the method or the benchmarks? Feel free to ask in the comments.
This article is an adapted version of the original research paper, edited for Medium. The full paper is available at https://arxiv.org/abs/2604.09418
Automated Instruction Revision (AIR): A Comparison of Task Adaptation Strategies for LLM-based… was originally published in DataDrivenInvestor on Medium, where people are continuing the conversation by highlighting and responding to this story.


