AI PoC to Production: Why 87% of AI Projects Fail (And How to Fix It)

Sarah Chen stood at the front of a boardroom on the 14th floor, clicking through a slide deck that made the future look inevitable. Her team’s AI proof of concept could predict customer churn 30 days before it happened — with 94% accuracy. The demo was flawless. Real-time dashboards. Beautiful visualizations.
The board approved $2 million in funding before she finished her coffee. Eight months later, the project was dead. Not because the model stopped working. It never started working — not in the way that mattered. The churn prediction engine, so stunning in the boardroom, could not survive contact with the company’s actual data infrastructure, its legacy CRM, or the 10,000 concurrent API calls it needed to handle every hour.
Sarah is a composite, but her story is not fiction. According to Gartner and corroborating research from the RAND Corporation, roughly 87% of AI projects never make it past the pilot stage into full production. Nearly nine out of ten AI initiatives die somewhere between the demo and deployment.
Here is the uncomfortable truth most AI vendors will not tell you: the gap between PoC and production is not a technical problem. It is a structural one. Companies fail because they treat the proof of concept like a scaled-down version of the final product, when it is actually a completely different thing — built for a completely different purpose, in a completely different environment, under completely different constraints. This article is the field guide for understanding that gap and closing it.
The Demo That Fooled the Board — Why PoCs Lie
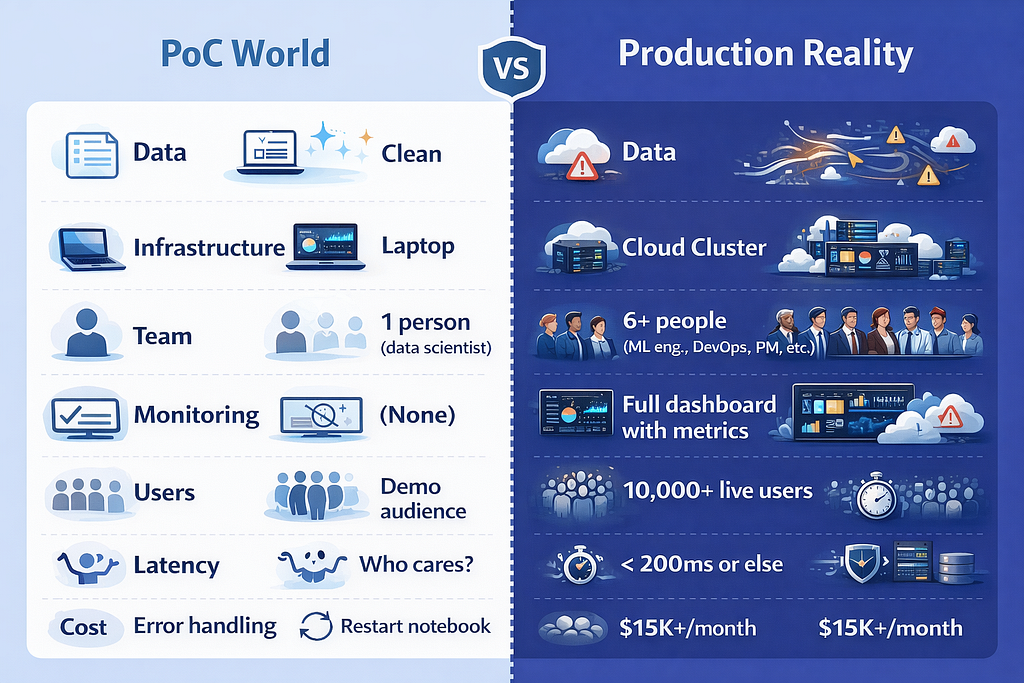
A proof of concept is not a product. It is a sales pitch to your own organization. And like any good sales pitch, it shows you the best version of reality — not the whole picture.
A PoC is a movie set. From the front, it looks like a real building — brick facade, glass windows, a working front door. But walk around to the back, and there is nothing. No plumbing. No wiring. No foundation. It was never designed to be lived in. It was designed to look good on camera for exactly one scene.
Three illusions make PoCs particularly dangerous.
The clean data illusion. Every successful PoC runs on curated data. A data scientist spent weeks preparing 50,000 perfectly labeled records — removing duplicates, filling gaps, standardizing formats. Production data looks nothing like this. It is messy, incomplete, arriving in real time from dozens of sources with different schemas and varying quality. Informatica's 2025 CDO Insights survey found that data quality and readiness are the single biggest obstacles to AI success, cited by 43% of organizations.
The single-user fantasy. The PoC handles ten requests gracefully. Maybe a hundred. But production needs to handle 10,000 requests per second without breaking a sweat. The architecture that works for a demo collapses under the weight of real-world concurrency, and nobody thought to stress-test it because the demo never needed to scale.
The sunny-day scenario. PoCs show the happy path. The model predicts correctly. The user inputs clean data. The network connection is stable. Production faces edge cases daily — malformed inputs, network timeouts, upstream services going down at 2 AM, users doing things nobody anticipated. The 6% of scenarios your PoC never tested become the 60% of support tickets your operations team drowns in.
These illusions are not the fault of the data science team. They are the natural result of a system that rewards impressive demos over production readiness. When the success metric is “wow the board,” you get a movie set. When the success metric is “reduce churn by 12% in Q3,” you get a building people can live in.
The 6 Gaps That Kill AI Projects

Every failed AI deployment I have examined can be traced back to one or more of these six gaps. They are predictable. They are measurable. And if you address them from Day 1 instead of Day 300, you change the math entirely.
Gap 1: The Data Gap
In the PoC: A clean CSV file with 10,000 rows. Every field is populated. Every label accurate. A data scientist spent three weeks perfecting it.
In production: Messy APIs pushing data in three different formats. Missing values in 23% of records. Real-time streams that occasionally duplicate, drop, or arrive out of order. A model that delivered 94% accuracy on curated data can drop below 75% when it meets the real world.
Gartner's research predicts that through 2026, organizations will abandon 60% of AI projects specifically because their data is not AI-ready. The data that makes a PoC shine is almost never the data that production systems have to digest.
The fix: Budget 40% of your AI project timeline for data engineering. Not as an afterthought — as the foundation. Build your data pipelines during the PoC, not after. Ingest real production data — messy and all — from the start. If your model cannot handle dirty data during the proof of concept, it will not survive deployment. Invest in schema enforcement, data validation, and drift detection before you write your first line of model code.
Gap 2: The Infrastructure Gap
In the PoC, the model runs on a data scientist's laptop. Or a single GPU instance in Google Colab. Inference takes five seconds? Fine for a demo.
In production: You need Kubernetes to orchestrate containers across multiple nodes. Auto-scaling to handle traffic spikes. Failover for when — not if — something goes down. CI/CD pipelines for model updates. Monitoring, logging, and alerting. GPU orchestration that does not bankrupt you on idle compute.
The fix: Build the PoC on production infrastructure from Day 1. Deploy on Kubernetes or a managed ML platform from the start. Yes, it feels like overkill for a proof of concept. That is the point. If your PoC cannot run on the infrastructure that production will use, you have not validated anything. You have built an expensive notebook.
Gap 3: The Integration Gap
In the PoC: A standalone Jupyter notebook. Data goes in, predictions come out. It connects to nothing.
In production: That model needs to send predictions to your CRM in real time, pull data from your warehouse on a schedule, authenticate through your SSO provider, log every inference for compliance, and play nicely with your ERP system from 2017 that has three competing data schemas and an authentication layer that was not designed with ML inference endpoints in mind.
S&P Global's 2025 survey found that 42% of companies abandoned most of their AI initiatives this year — up from 17% in 2024 — and integration complexity is consistently among the top reasons.
The fix: Map all integration points before writing a single line of model code. Identify every upstream data source and every downstream consumer. Build API contracts early. Define authentication flows. If you cannot draw the complete integration architecture on a whiteboard today, you are not ready to start building.
Gap 4: The Performance Gap
In the PoC, 92% accuracy sounds great in a presentation. The board applauds.
In production: That 8% error rate means 800 wrong answers per 10,000 customers. If you are running fraud detection, 800 false flags per 10,000 transactions means your support team is drowning, and your customers are furious. If you are running medical triage, 8% errors have a very different cost.
Performance is not just about accuracy. Production AI applications typically require response times of 100-200 milliseconds to preserve natural user interaction. Your PoC that takes five seconds per inference? Unusable.
The fix: Define acceptable error rates per use case before building, not after. A recommendation engine can tolerate a 10% miss rate. A loan approval system cannot. Set latency budgets early. Explore model distillation, quantization, and caching strategies during the PoC phase. A model that is 2% less accurate but 10x faster often delivers more business value.
Gap 5: The Governance Gap
In the PoC: Nobody asks about bias. Nobody asks about explainability. Nobody asks about audit trails. Nobody asks what happens when the model is wrong, and a customer gets hurt.
In production: Everyone asks those questions. The EU AI Act — in effect since August 2025 — requires transparency documentation, bias audits, and traceable decision-making for covered systems. Non-compliance penalties reach up to 30 million euros or 6% of annual global turnover. Even outside the EU, your legal team, your compliance officer, and your customers will demand answers.
The fix: Include governance checkpoints in every sprint, not as a final gate. Create model cards documenting training data, known limitations, and performance across demographic groups. Build bias testing into your CI/CD pipeline. Implement model versioning and inference logging so you can answer “why did the model make this decision?” six months after deployment. Governance bolted on after launch is expensive and fragile. Governance built in from Day 1 is a competitive advantage.
Gap 6: The Team Gap
In the PoC, one brilliant data scientist built the whole thing. Maybe two. They are exceptional at model architecture and feature engineering. They have never configured a load balancer in their lives.
In production: You need ML engineers for model serving and retraining. DevOps engineers for infrastructure. Security engineers for inference endpoints. Product managers for success metrics and user experience. Domain experts to validate that outputs make business sense. RAND Corporation’s research found that 84% of AI project failures are leadership- and organization-driven rather than technical.
The fix: Hire the production team when you approve the PoC, not when the PoC “succeeds.” If your PoC team does not include at least one person who has shipped a production ML system, you are already behind.
The 4-Phase Framework That Actually Works
Most organizations treat the PoC and production as two separate projects. Build the demo first, then figure out deployment later. That sequencing is the root cause of the 87% failure rate.
The alternative: treat the PoC as Phase 1 of a production deployment, not a standalone experiment.** Here is a four-phase framework that replaces hope with structure.
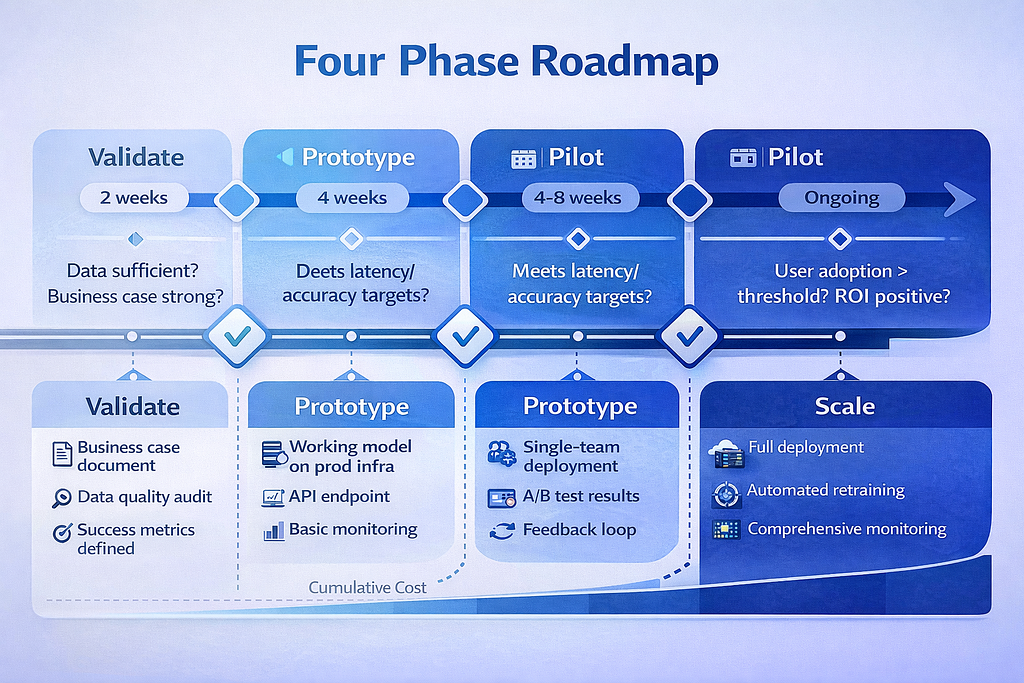
Phase 1: Validate (2 Weeks)
Goal: Confirm the business case and data feasibility before anyone writes code.
This is not technical validation. It is business validation. Can you define the problem in one measurable sentence? Does the data exist, in a usable format, at sufficient volume? If this works perfectly, is the ROI worth the investment?
Deliverable: A one-page AI Project Brief containing the problem statement, success metric, data availability assessment, integration map, and cost-benefit analysis.
Decision gate: If you cannot define the success metric in one sentence, or if the data does not exist, stop here. You just saved yourself six months and a million dollars.
Phase 2: Prototype (4 Weeks)
Goal: Build a working model on production infrastructure with real data.
This is where most organizations go wrong. The prototype is not a Jupyter notebook. It is a working system deployed on production-grade infrastructure, trained on actual production data, with API endpoints that match the integration architecture and monitoring instrumented from day one.
This is why at Intuz, we insist on building prototypes on production infrastructure from the start — even when it feels like overkill. Because a prototype that runs on a laptop proves exactly one thing: that the model works on a laptop. It proves nothing about production readiness.
Deliverable: Working prototype with production-grade data pipeline, baseline performance metrics (accuracy, latency, throughput), and initial governance documentation, including model card and bias assessment.
Decision gate: Does the model meet the minimum accuracy threshold on real data? Can it serve predictions within the latency budget? If not, iterate or kill.
Phase 3: Pilot (4–8 Weeks)
Goal: Deploy to one team or one geography and measure real-world impact.
The pilot is where theory meets reality. You are not testing the model anymore — you are testing the system. Does the integration hold? Do users actually adopt it? Does performance degrade over time? Does the feedback loop work for model retraining?
Deliverable: Pilot results report with go/no-go recommendation, including A/B test results against the existing baseline, a performance dashboard, and user adoption metrics.
Decision gate: Is the model delivering measurable business value against the pre-defined KPIs? Is the gap between pilot and prototype performance acceptable? Are users adopting it, or are they working around it?
Phase 4: Scale (Ongoing)
Goal: Gradual rollout with continuous monitoring and improvement.
Scale is not a milestone — it is a mode of operation. Successful AI systems are living systems. They require automated retraining pipelines triggered by data drift, continuous monitoring of model performance and infrastructure health, A/B testing against existing processes, and rollback procedures for when things go wrong.
Deliverable: Production system with SLAs, automated retraining pipelines, monitoring and alerting dashboards, operations runbooks, and ongoing ROI measurement against the original business case.
Decision gate: This phase does not end. The question is never “are we done?” It is “Are we improving?”
The CEO’s 10-Question Checklist
Before you greenlight your next AI initiative — or evaluate one that is already in flight — run it through these ten questions. Print this out. Bring it to your next steering committee. If you cannot answer "yes" to at least eight, you are likely headed for the 87%.

1. Can we define the business outcome in one sentence?
Not “improve customer experience” but “reduce average support resolution time from 4.2 minutes to 2.8 minutes.” If you cannot measure it, you cannot manage it.
2. Do we have 12+ months of relevant data in a usable format?
Not “we probably have data somewhere” but “here is the dataset, here is the access method, and here is proof it represents production conditions.” AI without quality data is just expensive guessing.
3. Is the production infrastructure planned (not “we’ll figure it out”)?
If the deployment plan ends at “deliver a working model,” you have planned for the 87%. The production infrastructure plan should be in place before the PoC plan is approved.
4. Have legal and compliance reviewed the data and model approach?
Not after the model is built. Before. Especially if you operate in or sell into the EU, healthcare, financial services, or any regulated industry. Retrofitting governance is five times more expensive than building it in.
5. Is there a model retraining plan (not just a model training plan)?
Models decay. Data drifts. The world changes. A model deployed and forgotten will silently degrade until it causes a visible, expensive failure. You need an automated retraining pipeline, not a calendar reminder.
6. Do we have a human fallback for when the model fails?
Because it will fail. What happens when the fraud detection system flags a legitimate transaction? What happens when the recommendation engine serves something offensive? A human-in-the-loop plan is not optional.
7. Is the team staffed for production (not just the PoC)?
Data scientists build models. Production systems need ML engineers, DevOps engineers, security experts, product managers, and domain experts. If you have not budgeted for the production team, you have not budgeted for production.
8. Are integration points mapped and API contracts defined?
Every upstream data source. Every downstream consumer. Every authentication layer. If you cannot draw this diagram on a whiteboard, you are not ready.
9. Do we have a kill switch and rollback plan?
What happens when the model starts producing bad outputs at 2 AM? Can you roll back to the previous version in minutes, not days? Can you disable the AI path and fall back to the manual process instantly?
10. Can we measure ROI within 90 days of deployment?
Not 18 months. Not “eventually.” Ninety days. If you cannot demonstrate measurable business value within a quarter, you either have the wrong metric or the wrong project.
Score yourself: 8–10 “yes” answers means you are ready to proceed.
5–7 means you have specific gaps to close before committing budget.
Below 5 means you are not ready — and starting anyway is how you join the 87%.
The Failure Rate Is a Choice
Remember Sarah Chen from the opening? The CTO who watched her $2 million churn prediction project die after eight months? Here is how her story could have gone differently.
In the alternate version, Sarah runs the 10-question checklist before requesting the budget. She discovers that customer data lives in three separate systems with incompatible schemas — failing Question 2. She spends two weeks in the Validate phase, maps the integration architecture, and staffs a cross-functional team from Day 1.
The prototype runs on the same Kubernetes cluster that will serve production. The pilot deploys to one geographic region for six weeks. The model achieves 88% accuracy on real data — lower than the PoC’s 94%, but the team expected that because they tested with dirty data from the start. Twelve months later, the system processes 50,000 predictions daily, churn is down 18%, and the finance team can point to $4.3 million in retained revenue.
Same company. Same problem. Same AI capability. Different outcome — because the team closed the six gaps before they became six-figure surprises.
Whether you are building generative AI applications or traditional ML pipelines, the gaps remain the same. The 87% failure rate is not about bad AI. It is not about a lack of talent or immature technology. It is about skipping the boring infrastructure, governance, and integration work that turns a demo into a system.
The companies that win at AI are not the ones with the best models. They have the best systems.
Written by Pratik K Rupareliya, Co-Founder & Head of Strategy at Intuz — where we’ve helped enterprises navigate the PoC-to-production journey across 1,700+ projects.
Planning an AI initiative? → Book a free 30-minute strategy call — we'll review your approach and share a mini roadmap.
AI Investment Readiness: 10 Questions Every CEO Should Ask Before Funding AI was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.



