The web learned long ago that untrusted content must never be given the same authority as the user. Many AI agent systems are now blurring that boundary again.
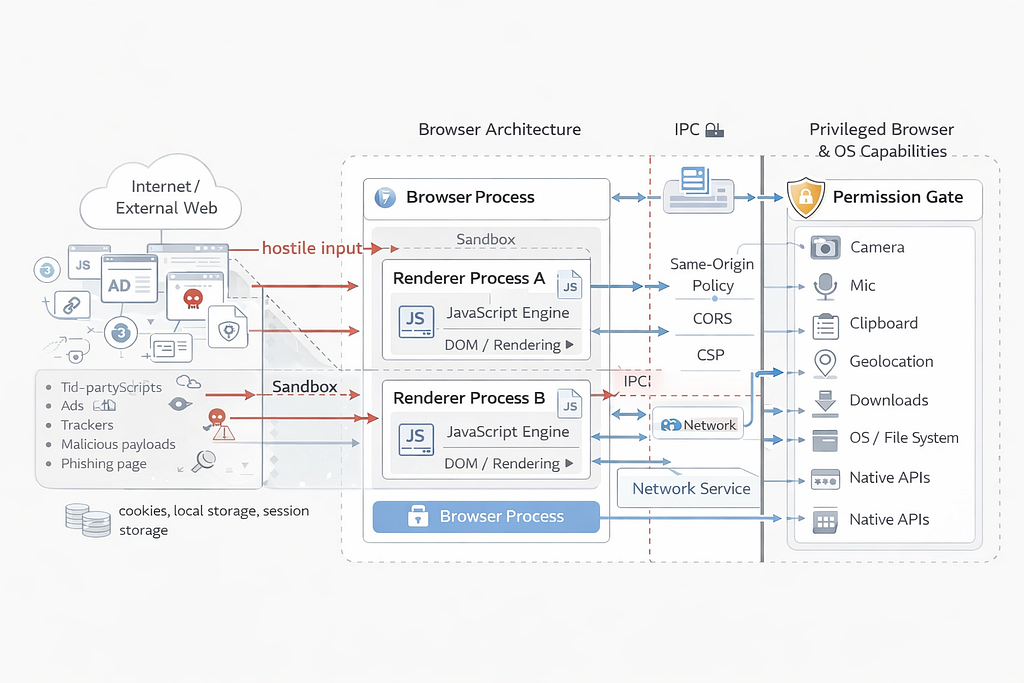
One of the most important lessons from the browser era was simple: just because a system can read content does not mean that content should be trusted to influence privileged behavior. Web security improved only after the industry accepted that pages, scripts, frames, and external inputs had to be contained behind strong boundaries. AI agents are now recreating the same problem by operating in environments full of untrusted content while also being given memory, tools, permissions, and the ability to act.
A website could be displayed in your browser, but that did not mean it should be able to access everything else in the browser, act across sites, read local files, or execute privileged actions on your behalf. That is why the web ended up with ideas like origin boundaries, sandboxing, and permission models. They were the result of learning, often painfully, that content and authority cannot be treated as the same thing.
That is the lesson a lot of AI agent systems now seem to be forgetting.
The conversation around agents is usually framed around model quality. Are they more capable? More accurate? Better at reasoning? But that is not the deepest issue. The deeper issue is architectural. These systems are being placed inside environments full of hostile or untrusted content while also being given memory, tools, permissions, and the ability to act.
Once that happens, the real question is no longer just whether the model gives a good answer. The real question is whether the system can reliably distinguish trusted user intent from untrusted external content.
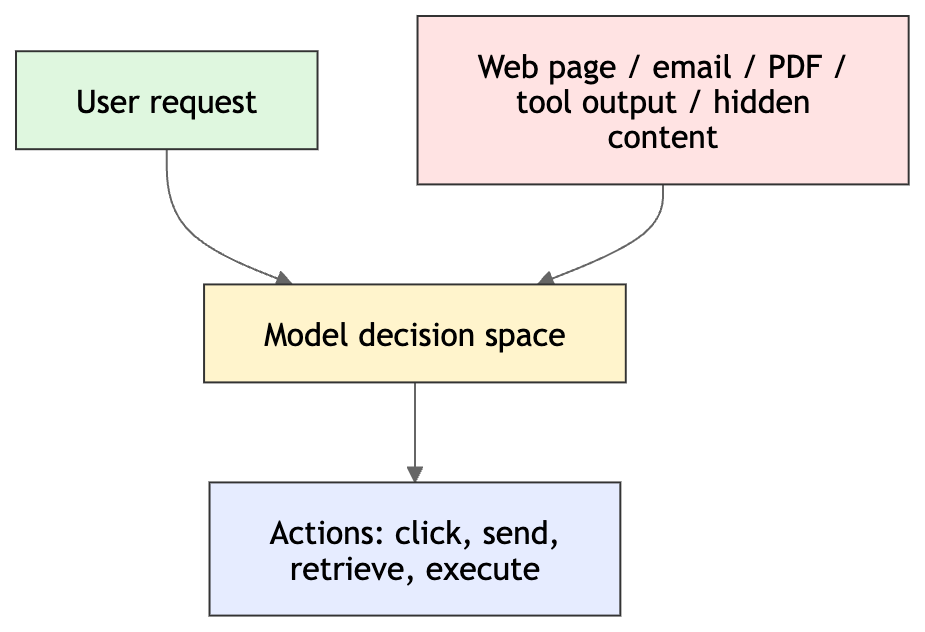
And that is exactly where things start to break.
A model does not inherently know which instruction came from the user and which came from an attacker. It sees tokens in context. If a web page, document, email, hidden frame, log file, or tool output ends up inside the same decision loop as the user’s request, the model can treat hostile input as if it were legitimate intent.
It is a broken trust boundary.
The recent Claude Chrome extension incident is a good example. The problem was not just that the model made a bad judgment call. The bigger issue was that the surrounding system allowed attacker-controlled input to enter a trusted workflow in a way that could influence actions. In other words, the system failed before the model ever had a fair chance to “reason” correctly about what was happening.
We have seen earlier versions of this pattern that external content found its way into the model’s decision space and started steering behavior it was never supposed to control. The recent agent incidents matter more because the stakes are now higher. These systems are not just generating text. They are reading, clicking, sending, retrieving, and acting.
That is why the risk here is bigger than “It just hallunicates.”
The real danger is systems with authority operating in environments full of adversarial content they cannot reliably classify. Once an agent has access to inboxes, files, browsers, internal tools, apps, and workflows, the consequences of a broken boundary stop looking like chatbot weirdness and start looking like operational compromise.
This is also why so many proposed fixes feel shallow.
Classifiers, regex rules, keyword filters, and similar detection layers do not solve the real problem. They are all attempts to spot malicious language after untrusted content has already been allowed into the system’s decision-making process.
That is a weak defense by design. Attackers do not need to use obvious instructions or recognizable patterns. They can rephrase, fragment, disguise, or route instructions through markup, tool outputs, intermediate steps, or ordinary-looking content. So even when a filter catches some cases, the system remains exposed if trusted user intent and untrusted external content are still being interpreted in the same decision space. The failure is not primarily in detection. It is in the architecture.
That is why prompt injection is not just an input-filtering problem. It is not something you “solve” by getting better at spotting suspicious phrases. It is a trust-boundary problem.
And trust-boundary problems are always solved with better architecture.
User intent has to come through a separate, explicit, authenticated path. External content has to remain untrusted all the way through the system. Tool outputs need provenance. Permissions need to be narrow and scoped. Sensitive actions need real approval gates. The system should be built on the assumption that hostile content will appear, not on the hope that it will not.
In other words, untrusted content can be read, summarized, or analyzed, but it should never be allowed to speak with the authority of the user.
That is the missing discipline in a lot of the current excitement around agents.
The industry is pushing hard toward less friction, more seamless automation, fewer confirmation steps, and deeper delegated access. And that all sounds great until you remember what friction often does in security-sensitive systems. Friction is not always bad design. Sometimes it is the control layer. Sometimes it is the checkpoint that stops untrusted input from quietly becoming action.
If you remove too much of that in the name of convenience, what you get is not just a smoother assistant. You get a more fragile system with more power and fewer barriers.
They are warnings about the direction of the architecture.
The deeper issue is that agent systems collapse too many roles into the same medium. Language is no longer just something the system reads. It is also how the system interprets goals, makes decisions, and initiates action. In older security models, code, content, and authority were separated because mixing them created obvious danger. Agent systems are starting to blur that separation again, except now the mixing happens through interpretation rather than execution.
That is why this problem runs deeper than prompt injection as a narrow attack category. It is about what happens when the same stream of tokens can carry description, persuasion, instruction, and operational consequence all at once. If the system cannot reliably preserve the difference between those roles, then failure is built into the design. And when that failure shows up, It will produce actions that feel internally justified, operationally smooth, and completely misaligned with who was actually supposed to be in control.
AI Agents Are Repeating an Old Browser Security Mistake was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.



