In the previous post, I introduced prefix caching to NanoGPT. We are going to continue along that line of thinking and introduce paged attention to NanoGPT. This is an optimization that allows us to reduce memory fragmentation and improve cache efficiency.
Paged Attention is most notably used in vLLM for managing the KV cache of requests, and one of vLLM’s primary innovations.
Our current KV cache management strategy is that every request owns a contiguous block of memory for its KV cache.
Every decode step does:
k = torch.cat([past_k, k_new], dim=1) # allocate a NEW (1, T+1, hs) tensor
v = torch.cat([past_v, v_new], dim=1) # copy all old data + 1 new token
1. O(T) copy per step — every torch.cat copies the entire cache history just to append one token.
2. Memory fragmentation — each request’s cache is a different-sized contiguous slab. When requests finish, they leave holes that can’t be reused by shorter or longer sequences.

At nanoGPT scale (32 max tokens, 210K params) this doesn’t matter. At production scale (128K tokens, 70B params) it’s the dominant bottleneck. The concept is what matters here.
PagedAttention replaces the contiguous cache with a block table — exactly like how an OS replaces contiguous RAM allocation with virtual memory pages. Each request gets a list of logical block indices that map to physical blocks in a shared pool. Appending a token writes into the current block’s next slot; no copying. When a block fills up, allocate a fresh one from the pool.
Block Pool
Your existing BlockManager allocates block indices but has no actual KV storage. You need a global pool of pre-allocated GPU tensors that hold the KV data for all requests, all layers, all heads.
Here is what that looks like:
class KVBlockPool:
"""
Pre-allocated GPU memory pool for KV cache blocks.
Physical layout: one big tensor per (layer, head, k/v).
Shape: (num_physical_blocks, block_size, head_size)
Block i occupies pool[i, :, :] — a fixed-size (block_size, head_size) slab.
"""
def __init__(self, num_blocks, block_size, n_layer, n_head, head_size, device):
self.num_blocks = num_blocks
self.block_size = block_size
# Pre-allocate ALL memory upfront — no dynamic allocation during inference
# k_pool[layer][head] = (num_blocks, block_size, head_size)
self.k_pool = {}
self.v_pool = {}
for layer in range(n_layer):
for head in range(n_head):
self.k_pool[(layer, head)] = torch.zeros(
num_blocks, block_size, head_size, device=device
)
self.v_pool[(layer, head)] = torch.zeros(
num_blocks, block_size, head_size, device=device
)
Preallocation may seem like a backwards step but in production, torch.empty / torch.zeros calls trigger CUDA memory allocation, which is slow and causes fragmentation. By allocating one big pool at startup, all subsequent "allocations" are just index bookkeeping — no CUDA malloc calls during inference.
Question for yourself: Why (num_blocks, block_size, head_size) instead of one giant (num_blocks * block_size, head_size) tensor?
Answer: Because the block dimension lets you use pool[block_indices] to gather multiple non-contiguous blocks into a contiguous view with a single indexing operation. This is the paged gather.
Block Table
Each request maintains a block table: an ordered list of physical block indices that maps its logical token positions to physical pool locations. We will modify our existing Request class to support this.
@dataclass
class Request:
"""Each in-flight generation carries its own state and KV cache."""
id: int
prompt_tokens: List[int] # the original encoded prompt
max_new_tokens: int # how many tokens this request wants
generated_tokens: List[int] = field(default_factory=list)
status: str = "waiting" # "waiting" -> "prefilling" -> "active" -> "done"
prefill_cursor: int = 0
_committed_blocks: int = 0
block_table: List[int] = field(default_factory=list)
num_filled_slots: int = 0
@property
def tokens_so_far(self) -> List[int]:
"""Full sequence: prompt + everything generated."""
return self.prompt_tokens + self.generated_tokens
@property
def num_tokens_in_cache(self):
return self.num_filled_slots
@property
def num_generated(self) -> int:
return len(self.generated_tokens)
@property
def is_done(self) -> bool:
return self.num_generated >= self.max_new_tokens
@property
def is_fully_prefilled(self) -> bool:
return self.prefill_cursor == len(self.prompt_tokens)
def clear_cache(self, block_allocator):
block_allocator.free_blocks_for_request(self.block_table)
self.block_table = []
self.num_filled_slots = 0
The mapping works like this:
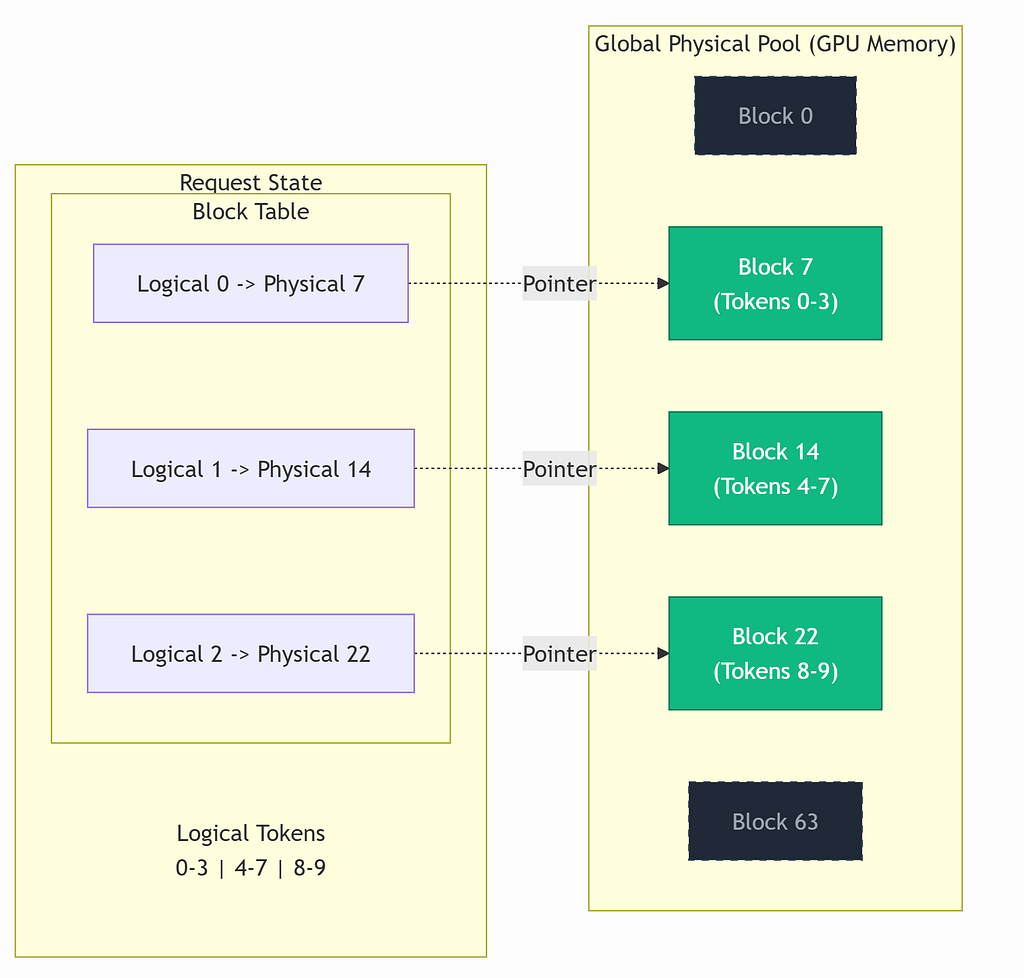
To find where logical token position t lives:
block_idx = t // block_size # which logical block
slot_idx = t % block_size # which slot within that block
phys_block = block_table[block_idx] # physical block index
# KV data lives at: pool[(layer, head)][phys_block, slot_idx, :]
You can think of it as the blocks being floors in a hotel room, and the slots being the rooms on that floor.
Writing KV Into the Pool
Previously, when the model produced new K/V tensors during a forward pass, we were concatenating them using torch.cat into a new tensor.
Now, we want to instead write them into the correct physical block slots.
Prefill
During prefill, the model processes the entire prompt (or a chunk of it) in one forward pass and produces K and V tensors for every token at once. For example, if you prefill 8 tokens, the model returns k_new and v_new each with shape (1, 8, head_size) — that's 8 tokens' worth of KV data that all need to land in the right physical blocks.
The key insight is that these 8 tokens might span multiple blocks. If block_size = 4, tokens 0–3 go into the first physical block and tokens 4–7 go into the second. The function below handles this by computing the block and slot address for each token individually.
def write_kv_to_pool(pool, block_table, block_size, start_pos, k_new, v_new, layer, head):
"""
Write new KV data into the physical pool using the block table.
Args:
pool: KVBlockPool
block_table: list of physical block indices for this request
block_size: tokens per block
start_pos: logical position of the first new token
k_new: (1, T_new, head_size) — new key data
v_new: (1, T_new, head_size) — new value data
"""
T_new = k_new.shape[1]
for t in range(T_new):
logical_pos = start_pos + t
block_idx = logical_pos // block_size
slot_idx = logical_pos % block_size
phys_block = block_table[block_idx]
pool.k_pool[(layer, head)][phys_block, slot_idx, :] = k_new[0, t, :]
pool.v_pool[(layer, head)][phys_block, slot_idx, :] = v_new[0, t, :]
Get the count of new tokens. T_new = k_new.shape[1] reads the sequence-length dimension of the new KV tensor — this is how many tokens the model just processed in one forward pass. During prefill, this could be anywhere from 1 to the full prompt length depending on chunking.
Loop over each new token. We iterate t from 0 to T_new - 1. Each iteration places one token's K and V vectors into the correct physical slot in the pool.
Compute the logical position. logical_pos = start_pos + t maps the loop index to the token's absolute position in the full sequence. If this is a chunked prefill resuming from position 8, then start_pos = 8 and the first iteration writes to logical position 8, not 0.
Translate to block + slot. block_idx = logical_pos // block_size tells us which logical block this token belongs to — for example, with block_size = 4, logical position 9 maps to block 2 (9 // 4 = 2). slot_idx = logical_pos % block_size gives the offset within that block — position 9 maps to slot 1 (9 % 4 = 1). This is the same integer division you'd use to find a page number and offset in an OS virtual memory system.
Look up the physical block. phys_block = block_table[block_idx] translates the logical block index into the actual physical block in the GPU memory pool. This is the core of paged attention — the request doesn't know or care where its data physically lives, it just follows the block table.
Write the KV data in-place. The final two lines write the K and V vectors directly into the pre-allocated pool tensors at the computed physical location. There’s no torch.cat, no new tensor allocation, no copying of old data. Just a direct write to pool[phys_block, slot_idx, :]. This is why paged attention eliminates the O(T) copy-per-step problem — appending a token is O(1).
Visualizing write_kv_to_pool
Let’s walk through exactly what this code does using a concrete example.
The Setup
Imagine we have a block size of 4 tokens. We are processing a prefill chunk of 5 new tokens (T_new = 5). The request already has 2 tokens processed (start_pos = 2).
1. The Block Table (The Map)
This request already has two physical blocks assigned to it from the pool.
Logical Block Index | Physical Block Index
--------------------|---------------------
Block 0 | Block 14
Block 1 | Block 22
In Python: block_table = [14, 22]
2. The Physical Pool (The Destination)
The pool is a giant 3D tensor holding all KV data for everyone. We’re only looking at a specific (layer, head) slice.
Physical Block 14 (Capacity: 4) Physical Block 22 (Capacity: 4)
[ Slot 0 ] - (filled: Token 0) [ Slot 0 ] - (empty)
[ Slot 1 ] - (filled: Token 1) [ Slot 1 ] - (empty)
[ Slot 2 ] - (empty) [ Slot 2 ] - (empty)
[ Slot 3 ] - (empty) [ Slot 3 ] - (empty)
3. The New Data (k_new, v_new - The Source)
The model just computed the keys and values for our 5 new tokens.
k_new (shape: 1, 5, head_size):
[ t0_data, t1_data, t2_data, t3_data, t4_data ]
Step-by-Step Execution
The function loops over each of the 5 new tokens: for t in range(5):
Iteration 1: t = 0 (The 1st new token)
1. Calculate Global Position: logical_pos = start_pos + t ➔ 2 + 0 = 2 (This is the 3rd token overall for this request).
2. Find the Logical Block: block_idx = logical_pos // block_size ➔ 2 // 4 = 0 (It belongs in Logical Block 0).
3. Find the Slot Inside the Block: slot_idx = logical_pos % block_size ➔ 2 % 4 = 2 (It goes into slot 2 of that block).
4. Lookup the Physical Address: phys_block = block_table[block_idx] ➔ block_table[0] = 14 (Logical Block 0 maps to Physical Block 14).
5. Write the Data! Take t0_data from k_new and write it to Physical Block 14, Slot 2.
Iteration 2: t = 1 (The 2nd new token)
1. logical_pos = 2 + 1 = 3
2. block_idx = 3 // 4 = 0 (Still Logical Block 0)
3. slot_idx = 3 % 4 = 3 (Slot 3)
4. phys_block = block_table[0] = 14
5. Write! t1_data goes to Physical Block 14, Slot 3.
Uh oh, Physical Block 14 is now completely full! Let’s see what happens next.
Iteration 3: t = 2 (The 3rd new token)
1. logical_pos = 2 + 2 = 4
2. Find the Logical Block: block_idx = 4 // 4 = 1 (Notice the jump! We crossed the block boundary and moved to Logical Block 1).
3. Find the Slot: slot_idx = 4 % 4 = 0 (The slot index wraps back around to 0).
4. Lookup the Physical Address: phys_block = block_table[1] = 22 (We look up the next block in our table and find Physical Block 22).
5. Write! t2_data goes to Physical Block 22, Slot 0.
Iteration 4: t = 3 (The 4th new token)
1. logical_pos = 5
2. block_idx = 5 // 4 = 1
3. slot_idx = 5 % 4 = 1
4. phys_block = 22
5. Write! t3_data goes to Physical Block 22, Slot 1.
Iteration 5: t = 4 (The 5th new token)
1. logical_pos = 6
2. block_idx = 6 // 4 = 1
3. slot_idx = 6 % 4 = 2
4. phys_block = 22
5. Write! t4_data goes to Physical Block 22, Slot 2.
The Resulting Physical Memory
Notice how a contiguous tensor of 5 new tokens (k_new) was automatically sliced and scattered across two completely separate physical blocks in GPU memory, just by doing simple math on the logical positions!

Decode
Decode is simpler than prefill because we’re only ever writing one token at a time. Each decode step, the model produces a single new K and V vector for the token it just generated. We need to write that single vector into the next available slot in the pool.
But there’s a subtlety: what if the current block is full? If block_size = 4 and we've already written 4 tokens into the current block (slots 0, 1, 2, 3), there's no room for token 5. We need to grab a fresh physical block from the pool first. That's what maybe_allocate_block handles — it checks if we're at a block boundary and allocates a new block if needed.
def maybe_allocate_block(request, block_allocator, block_size):
"""Allocate a new physical block if the current one is full."""
if request.num_filled_slots % block_size == 0:
new_block = block_allocator.allocate_one()
request.block_table.append(new_block)
Check if we’re at a block boundary. request.num_filled_slots % block_size == 0 is true whenever the number of tokens written so far is an exact multiple of the block size — meaning the previous block is completely full and there's no room for the next token. For example, with block_size = 4: after writing 0 tokens (need a first block), after 4 tokens (block 0 full), after 8 tokens (block 1 full), etc.
Allocate a fresh physical block. block_allocator.allocate_one() grabs an unused physical block index from the free pool. This is just an integer — the actual GPU memory was already pre-allocated in the KVBlockPool at startup. No CUDA malloc happens here.
Extend the block table. The new physical block index is appended to the request’s block_table. Now when write_kv_to_pool runs for the next token, block_table[block_idx] will resolve to this freshly allocated block, and the KV data will be written into it.
After maybe_allocate_block runs, the caller uses the same write_kv_to_pool function from the prefill section — but with T_new = 1 (a single token) and start_pos = request.num_filled_slots. The write logic is identical; the only difference is that decode writes one token per step while prefill writes many.
Block Allocator
We need now a block allocator class to define the operations for managing physical blocks from the block pool. It will allow us to allocate arbitrary amounts of blocks from the pool and free them if needed.
Here is what the code looks like:
class BlockAllocator:
"""Manages physical block allocation from the pool."""
def __init__(self, num_blocks):
self.num_blocks = num_blocks
self.free_blocks = list(range(num_blocks))
def allocate_one(self):
"""Allocate a single physical block. Raises if pool exhausted."""
if not self.free_blocks:
raise RuntimeError("Block pool exhausted!")
return self.free_blocks.pop()
def allocate_n(self, n):
"""Allocate n blocks for a prefill chunk."""
if len(self.free_blocks) < n:
raise RuntimeError(f"Need {n} blocks, only {len(self.free_blocks)} free")
return [self.free_blocks.pop() for _ in range(n)]
def free_blocks_for_request(self, block_table):
"""Return all blocks from a request back to the free pool."""
self.free_blocks.extend(block_table)
@property
def num_free(self):
return len(self.free_blocks)
There are 3 scenarios when we have to perform an operation:
• At admission (prefill start): allocate enough blocks for the prompt + some headroom
• At decode, when the current last block fills up: allocate 1 new block
• At request completion: free all blocks back to the pool
Question to ask yourself: How many blocks does a prompt of length P need? Answer: ceil(P / block_size). For P=10, block_size=4: ceil(10/4) = 3 blocks.
Does Head.forward() Need to Change?
NO! The beauty of this design is that the attention head itself doesn’t need to know anything about physical blocks or fragmentation. It only cares about logical positions. The BlockAllocator and write_kv_to_pool handle all the low-level details transparently.
Assembly for Paged KV

So far we’ve solved the write side — new KV data goes directly into physical blocks with no copying. But there’s a problem on the read side: when the model runs a forward pass, Head.forward() expects a contiguous past_kvs tensor of shape (B, T, head_size) for the attention bmm operation. Our KV data is now scattered across arbitrary physical blocks in the pool — block 14, then block 22, then block 7 — and PyTorch's torch.bmm can't natively index into non-contiguous scattered memory.
This is where assemble_paged_cache comes in. It's the bridge between the paged world (scattered blocks in a pool) and the contiguous world (what attention needs). It gathers each request's KV blocks from the pool, stitches them into a contiguous tensor, left-pads shorter sequences to match the longest one in the batch, and builds the attention mask — exactly the same interface as our previous assemble_batch_cache, so the model doesn't need to change at all.
In production systems like vLLM, this gather step is replaced by a custom CUDA kernel (paged_attention_kernel) that reads directly from scattered blocks during the attention computation — avoiding the gather entirely. But for learning purposes, this explicit gather-then-attend approach lets us keep our existing Head.forward() unchanged while still getting the memory management benefits of paging.
def assemble_paged_cache(requests, pool, block_size):
"""
Gather per-request KV from the paged pool into batched tensors.
Same interface as assemble_batch_cache — returns left-padded batched cache.
"""
B = len(requests)
lengths = [req.num_filled_slots for req in requests]
max_t = max(lengths) if lengths else 0
pad_lengths = [max_t - t for t in lengths]
attn_mask = torch.zeros(B, 1, max_t, device=device, dtype=torch.bool)
for i, pad in enumerate(pad_lengths):
attn_mask[i, 0, pad:] = True
past_kvs = []
for layer_idx in range(n_layer):
block_kv = []
for head_idx in range(n_head):
keys, values = [], []
for i, req in enumerate(requests):
k, v = gather_kv_from_pool(
pool, req.block_table, block_size,
req.num_filled_slots, layer_idx, head_idx
)
# Left-pad if needed
if pad_lengths[i] > 0:
hs = k.shape[2]
pad_tensor = torch.zeros(1, pad_lengths[i], hs, device=device)
k = torch.cat([pad_tensor, k], dim=1)
v = torch.cat([pad_tensor, v], dim=1)
keys.append(k)
values.append(v)
block_kv.append((torch.cat(keys, dim=0), torch.cat(values, dim=0)))
past_kvs.append(block_kv)
return past_kvs, attn_mask, pad_lengths
Measure each request’s cache length. lengths = [req.num_filled_slots for req in requests] collects how many KV tokens each request currently has. These will differ — one request might have 10 tokens cached, another 6. We find the longest (max_t) so we know how wide the batched tensor needs to be, and compute pad_lengths — how many zeros to prepend to shorter sequences so they all line up on the right edge.
Build the attention mask. The mask is (B, 1, max_t) and starts as all False (masked out). For each request, we set positions pad: onward to True — these are the real token positions. The leading False positions correspond to the left-padding and will be ignored during attention. This prevents the model from attending to padding tokens, which would corrupt the softmax distribution.
Gather KV from the pool. The triple-nested loop iterates over every (layer, head) combination and, for each request, calls gather_kv_from_pool to read the scattered physical blocks and concatenate them into a contiguous (1, T, head_size) tensor. This is the "page table walk" — it follows the request's block_table to find where each block of KV data physically lives and stitches the pieces together in logical order.
Left-pad shorter sequences. If a request has fewer tokens than max_t, we prepend a zero tensor of shape (1, pad_length, head_size) to the left side of its K and V. This ensures every request's KV tensor has the same sequence length dimension, which is required for batching. The attention mask ensures these padded positions are never attended to.
Stack into a batch. torch.cat(keys, dim=0) concatenates all B requests' K tensors along the batch dimension, producing a single (B, max_t, head_size) tensor. The same happens for V. Each (layer, head) pair gets one such (K, V) tuple, matching the exact format that Head.forward() already expects.
Return the same interface. The function returns (past_kvs, attn_mask, pad_lengths) — identical to the old assemble_batch_cache. This is a deliberate design choice: by keeping the output format the same, we can swap paged attention in without touching any model code. The only thing that changed is where the KV data comes from — a shared pool of scattered blocks instead of per-request contiguous tensors.
Disassembly for Paged KV
assemble_paged_cache is the read side — it gathers scattered blocks into contiguous tensors so the model can run attention. disassemble_paged_fused is the write side after a forward pass — it takes the new KV tensors the model just produced and scatters them back into the correct physical blocks in the pool.
The “fused” in the name refers to the fact that this function handles a mixed batch where different requests contributed different numbers of new tokens to the forward pass. In a typical step, a prefilling request might have contributed 8 new tokens (a chunk) while three decoding requests each contributed 1 token. The model ran them all in a single batched forward pass, so the output new_kvs tensor has all their new KV data packed together — but each request's slice is a different width. The num_new_per_req list tells us how to carve up that output.
This is the inverse of what assemble_paged_cache did: assembly gathered from pool → contiguous tensor, disassembly writes from contiguous tensor → pool.
def disassemble_paged_fused(all_reqs, new_kvs, num_new_per_req, pool, block_size):
"""Like disassemble_paged_cache but handles variable new tokens per row."""
for layer_idx, block_kv in enumerate(new_kvs):
for head_idx, (batched_k, batched_v) in enumerate(block_kv):
for i, req in enumerate(all_reqs):
t_new = num_new_per_req[i]
k_new = batched_k[i:i+1, -t_new:, :]
v_new = batched_v[i:i+1, -t_new:, :]
write_kv_to_pool(
pool, req.block_table, block_size,
req.num_filled_slots,
k_new, v_new, layer_idx, head_idx
)
for i, req in enumerate(all_reqs):
req.num_filled_slots += num_new_per_req[i]
Loop over every (layer, head) pair. The outer two loops iterate over the model’s layer and head structure. new_kvs is organized as new_kvs[layer][head] = (batched_k, batched_v), where each tensor has shape (B, T_padded, head_size). We need to process every layer and head independently because each has its own slice of the physical pool.
Look up how many new tokens this request produced. t_new = num_new_per_req[i] tells us how wide this request's slice is in the batched output. A prefilling request might have t_new = 8 (a full chunk), while a decoding request has t_new = 1. This is the key piece of information that lets us handle the mixed batch correctly.
Slice out this request’s new KV data. batched_k[i:i+1, -t_new:, :] extracts request i's portion of the batched output. The -t_new: indexing takes the last t_new positions from the sequence dimension — this is important because the batched tensor was left-padded during assembly, so the real data is always right-aligned. The i:i+1 keeps the batch dimension (shape (1, t_new, head_size)) so it matches what write_kv_to_pool expects.
Write back into the pool. We call the same write_kv_to_pool function from the prefill section, passing req.num_filled_slots as start_pos. This tells the writer where in the request's logical sequence these new tokens begin — right after whatever was already cached. The function handles the block/slot math and scatters the data into the correct physical blocks.
Advance the fill counter. After all layers and heads have been written, we update each request’s num_filled_slots by adding the number of new tokens it just processed. This is done in a separate loop after the KV writes because write_kv_to_pool reads num_filled_slots as the start position — if we updated it mid-loop, later layers would write to the wrong slots.
The Generate function
## Interleave generate
def interleaved_generate(model, requests, policy="fcfs", token_budget=16, max_kv_tokens=256):
scheduler = Scheduler(policy, token_budget=token_budget, max_kv_tokens=max_kv_tokens)
head_size = n_embd // n_head
num_blocks = max_kv_tokens // block_size
pool = KVBlockPool(num_blocks, block_size, n_layer, n_head, head_size, device)
scheduler.block_allocator = BlockAllocator(num_blocks)
step = 0
for req in requests:
req.arrival_time = step
scheduler.add_request(req)
model.eval()
with torch.no_grad():
while not scheduler.is_done():
prefill_req, decode_reqs = scheduler.schedule(step)
chunk_size = 0
remaining_budget = token_budget - len(decode_reqs)
if remaining_budget > 0 and prefill_req is not None:
tokens_left = len(prefill_req.prompt_tokens) - prefill_req.prefill_cursor
chunk_size = min(remaining_budget, tokens_left)
if chunk_size == 0 and not decode_reqs:
step += 1
continue
for req in decode_reqs:
maybe_allocate_block(req, scheduler.block_allocator, block_size)
# 3. ── SINGLE FUSED MODEL CALL ──
# Use your already-written helper to build the batched inputs
batch_tokens, batch_positions, past_kvs, attn_mask, pad_lengths = assemble_fused_batch(
decode_reqs,
prefill_req if chunk_size > 0 else None,
chunk_size,
pool,
block_size
)
logits, _, new_kvs = model(
batch_tokens,
pos=batch_positions,
past_kvs=past_kvs,
attn_mask=attn_mask
)
## DISASSEMBLY
all_reqs = decode_reqs[:]
num_new_tokens_per_req = [1] * len(decode_reqs)
if chunk_size > 0:
all_reqs.append(prefill_req)
num_new_tokens_per_req.append(chunk_size)
disassemble_paged_fused(all_reqs, new_kvs, num_new_tokens_per_req, pool, block_size) # CHANGED
# 5. ── POST-PROCESSING ──
# Handle decode requests (they are the first N rows in the batch)
if len(decode_reqs) > 0:
logits_decode = logits[:len(decode_reqs), -1, :]
probs = F.softmax(logits_decode, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
for i, req in enumerate(decode_reqs):
req.generated_tokens.append(idx_next[i].item())
req._last_token = idx_next[i : i + 1]
if req.is_done:
scheduler.complete(req)
if chunk_size > 0:
prefill_req.prefill_cursor += chunk_size
if prefill_req.is_fully_prefilled:
prefill_logits = logits[-1:, -1, :]
probs = F.softmax(prefill_logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
prefill_req.generated_tokens.append(idx_next.item())
prefill_req._last_token = idx_next
commit_completed_blocks(prefill_req, scheduler.block_cache, BLOCK_SIZE, pool)
scheduler.promote(prefill_req)
step += 1
return scheduler
The key changes are the following:
1. We create a single pre-allocated KVBlockPool upfront. The BlockAllocator tracks which physical blocks are free/in-use. This is the core of the paged attention change — memory is now a fixed pool of blocks, not dynamically-allocated per-request tensors.
2. We call maybe_allocate_block for each request in decode_reqs.
for req in decode_reqs:
maybe_allocate_block(req, scheduler.block_allocator, block_size)
Before each decode step, every active request checks if its current block is full (num_filled_slots % block_size == 0). If so, a new physical block is allocated and appended to the request’s block_table. This is the “grow by one block at a time” pattern — you never over-allocate.
1. We are now calling assemble_fused_batch once per step, instead of once per request.
2. After the forward pass, new KV entries are written back into the physical pool via write_kv_to_pool (mapping logical position → physical block + slot). Previously, you’d just concatenate onto per-request tensors.
3. Once a request finishes prefilling, any fully-filled blocks are hashed and inserted into the global BlockCache:
if prefill_req.is_fully_prefilled:
...
commit_completed_blocks(prefill_req, scheduler.block_cache, BLOCK_SIZE, pool)
scheduler.promote(prefill_req)
Once a request finishes prefilling, any fully-filled blocks are hashed and inserted into the global BlockCache. Future requests with the same prompt prefix can skip recomputing those blocks — this is prefix caching.
1. scheduler.complete(req) now calls block_allocator.free_blocks_for_request(req.block_table), recycling the physical blocks. With contiguous caches, you just dropped the tensors and let Python’s GC handle it. Now it’s explicit — the blocks go back to the free list for reuse.
Tests
Test 1: Output equivalence
Run the same requests through both the old contiguous-cache interleaved_generate and the new paged version with the same random seed. Outputs must be identical. This validates that paging didn't change the attention computation.
Test 2: Block allocation
This test validates the full lifecycle of physical block management: allocation at admission, growth during decode, and release at completion. It’s a critical correctness check because if blocks aren’t allocated properly, KV writes will land in uninitialized or already-freed memory. If blocks aren’t freed properly, the pool will leak and eventually refuse to admit new requests even when there’s plenty of logical capacity.
The test simulates the complete lifecycle by hand — no model forward pass, just the block bookkeeping — which isolates the allocator logic from any attention bugs.
'''
Test 2: Block Allocation Lifecycle
This tests your BlockAllocator and Scheduler admission/completion logic.
'''
def test_block_allocation_lifecycle(scheduler):
allocator = scheduler.block_allocator
initial_free = allocator.num_free
block_size = allocator.block_size # Assuming this is accessible, e.g., 4
# 1. Create request with a 12-token prompt
prompt = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
req = Request(id=0, prompt_tokens=prompt, max_new_tokens=10)
# 2. Simulate Admission
scheduler.add_request(req)
scheduler._maybe_admit(step=0)
# Prompt is 12 tokens, block_size=4 -> needs 3 blocks
assert len(req.block_table) == 3, f"Expected 3 blocks, got {len(req.block_table)}"
assert req.num_filled_slots == 0, "Slots should be 0 immediately after admission"
# 3. Simulate prefill completion
req.num_filled_slots = 12
# 4. Simulate 4 decode steps (slots 12, 13, 14, 15)
for _ in range(4):
# This is the logic you should have at the start of your decode loop
if req.num_filled_slots % block_size == 0:
new_block = allocator.allocate_one()
req.block_table.append(new_block)
req.num_filled_slots += 1
# We started with 3 blocks. We filled slots 13, 14, 15, 16.
# Slot 13 requires a new block (Block 4).
# Slot 14, 15, 16 fit in Block 4.
# Therefore, total blocks = 4.
assert len(req.block_table) == 4, f"Expected 4 blocks, got {len(req.block_table)}"
assert req.num_filled_slots == 16, "Should have 16 filled slots"
# 5. Simulate Request Completion
free_before_complete = allocator.num_free
scheduler.complete(req)
assert allocator.num_free == free_before_complete + 4, "Blocks were not properly returned to the free pool"
assert allocator.num_free == initial_free, "Memory leak! Pool did not return to initial state."
print("✅ Test 2: Block allocation lifecycle PASSED")
BLOCK_SIZE = 4
scheduler = Scheduler(token_budget=16, max_kv_tokens=256, block_size=BLOCK_SIZE)
scheduler.block_allocator = BlockAllocator(num_blocks=64)
# Run it
test_block_allocation_lifecycle(scheduler)
The test walks through 5 stages that mirror exactly what happens during a real request’s lifetime:
Stage 1 — Admission allocates blocks for the prompt. A 12-token prompt with block_size=4 needs exactly ceil(12/4) = 3 physical blocks. The assertion checks that _maybe_admit correctly computed this and allocated 3 blocks from the pool. It also verifies that num_filled_slots is still 0 — the blocks are allocated (reserved) but no KV data has been written yet. This distinction matters: allocation is about reserving space, filling is about writing data.
Stage 2 — Prefill fills the allocated blocks. We manually set num_filled_slots = 12 to simulate a completed prefill. In the real generate loop, write_kv_to_pool would have filled these 12 slots across the 3 blocks. No new blocks are needed here because the prompt fits exactly into the 3 blocks that were pre-allocated.
Stage 3 — Decode triggers a new block allocation. We simulate 4 decode steps (generating tokens at positions 12, 13, 14, 15). At position 12, num_filled_slots % block_size == 0 is true (12 % 4 == 0), meaning the last block is full and we need a 4th block. Positions 13, 14, and 15 fit into that new block without triggering another allocation. The assertion confirms we now have exactly 4 blocks and 16 filled slots.
Stage 4 — Completion returns all blocks to the pool. When scheduler.complete(req) runs, it calls block_allocator.free_blocks_for_request(req.block_table), which returns all 4 physical blocks to the free list. The assertion checks that the free count increased by exactly 4, and that the pool is back to its initial state — no memory leaked.
This test catches the most common paged attention bugs: off-by-one errors in block allocation (allocating too many or too few blocks for a given prompt length), forgetting to allocate new blocks at decode-time boundaries, and failing to free blocks on completion (memory leaks).
Test 3: Memory Reuse
"""
Test 3: Memory Reuse
This ensures that when a request finishes, its physical blocks are actually handed out to the next request.
"""
def test_memory_reuse(scheduler):
allocator = scheduler.block_allocator
# Request A asks for blocks
req_a = Request(id=1, prompt_tokens=[10, 20], max_new_tokens=5)
scheduler.add_request(req_a)
scheduler._maybe_admit(step=0)
blocks_used_by_a = set(req_a.block_table)
# Request A finishes, returning blocks to pool
scheduler.complete(req_a)
# Request B asks for blocks
req_b = Request(id=2, prompt_tokens=[30, 40], max_new_tokens=5)
scheduler.add_request(req_b)
scheduler._maybe_admit(step=1)
blocks_used_by_b = set(req_b.block_table)
# Because A finished before B started, B should have been handed the exact same physical blocks
assert blocks_used_by_a.intersection(blocks_used_by_b), "Physical blocks were not reused!"
# Clean up
scheduler.complete(req_b)
print("✅ Test 3: Memory reuse PASSED")
BLOCK_SIZE = 4
scheduler = Scheduler(token_budget=16, max_kv_tokens=256, block_size=BLOCK_SIZE)
scheduler.block_allocator = BlockAllocator(num_blocks=64)
# Run it
test_memory_reuse(scheduler)
This test proves that freed blocks are genuinely recycled — not just marked as free but actually handed out again to the next request that needs them. This is the whole point of paged attention: unlike contiguous allocation where each request gets a fresh torch.zeros call, the paged pool reuses the same physical memory over and over.
The test creates Request A with a 2-token prompt (needing 1 block), completes it (returning that block to the free list), then creates Request B with a different 2-token prompt. The key assertion is blocks_used_by_a.intersection(blocks_used_by_b) — it checks that at least one of B's physical blocks was previously owned by A. Since our BlockAllocator uses a list with pop() and extend(), freed blocks go to the end of the free list and get popped off last-in-first-out, so B should receive the exact same block index that A just released.
This test matters for two reasons. First, it validates that free_blocks_for_request actually puts blocks back on the free list (not just clearing the request's block table). Second, it confirms that the allocator doesn't have a "use once and discard" bug where freed block indices are lost. In a real system serving thousands of requests, block reuse is what keeps GPU memory utilization stable — without it, you'd exhaust the pool after a few hundred requests even though most of the memory is logically free.
Test 4: Pool Exhaustion
Tests 2 and 3 proved that blocks are allocated and recycled correctly. But what happens when the pool is completely full and a new request arrives? The scheduler must refuse to admit the request — not crash, not silently overwrite someone else’s memory, just hold it in the waiting queue until blocks free up. This is backpressure, and it’s how production systems like vLLM prevent out-of-memory crashes under heavy load.
This test uses an artificially tiny pool (only 2 blocks) to force exhaustion with just one request, making the behavior easy to observe.
"""
Test 4: Pool Exhaustion
This tests that your scheduler correctly stops admitting requests when the GPU is "full".
"""
def test_pool_exhaustion():
# Create a tiny allocator with ONLY 2 blocks
tiny_allocator = BlockAllocator(num_blocks=2)
# You might need to mock your scheduler initialization here if it requires other arguments
tiny_scheduler = Scheduler(token_budget=32, max_kv_tokens=8)
tiny_scheduler.block_allocator = tiny_allocator
# Request A needs 2 blocks (8 tokens) -> Should admit
req_a = Request(id=1, prompt_tokens=[1]*8, max_new_tokens=10)
tiny_scheduler.add_request(req_a)
tiny_scheduler._maybe_admit(step=0)
assert req_a.status == "prefilling", "Request A should have been admitted"
assert tiny_allocator.num_free == 0, "Pool should be completely empty"
# Request B needs 1 block -> Should NOT admit because pool is empty
req_b = Request(id=2, prompt_tokens=[1]*4, max_new_tokens=10)
tiny_scheduler.add_request(req_b)
tiny_scheduler._maybe_admit(step=1)
assert req_b.status == "waiting", "Request B should NOT have been admitted (pool full)"
# Request A finishes -> Frees 2 blocks
tiny_scheduler.complete(req_a)
assert tiny_allocator.num_free == 2, "Pool should have 2 free blocks again"
# Try admitting Request B again -> Should admit now
tiny_scheduler._maybe_admit(step=2)
assert req_b.status == "prefilling", "Request B should have been admitted after A finished"
print("✅ Test 4: Pool exhaustion and preemption PASSED")
test_pool_exhaustion()
Step 1 — Request A fills the entire pool. Request A has an 8-token prompt, which with block_size=4 needs exactly 2 blocks — the pool's entire capacity. After admission, tiny_allocator.num_free == 0 confirms every block is taken. This is the "GPU is full" state.
Step 2 — Request B is rejected. Request B arrives with a 4-token prompt (needing 1 block), but there are zero free blocks. The assertion req_b.status == "waiting" confirms that _maybe_admit correctly checked the allocator's free count and refused to admit B. Crucially, B isn't dropped — it stays in the waiting queue, ready to be retried on a future step.
Step 3 — Request A completes and frees its blocks. When tiny_scheduler.complete(req_a) runs, A's 2 blocks are returned to the free pool. The assertion verifies the free count is back to 2.
Step 4 — Request B is admitted on retry. We call _maybe_admit again, and this time it succeeds — B gets its block from the freshly freed pool and transitions to "prefilling". This proves the full recovery cycle: exhaustion → backpressure → release → admission.
This test validates the most important safety property of paged attention: the system never over-commits physical memory. Without this check, two requests could be assigned the same physical block, silently corrupting each other’s KV caches and producing garbage output. The backpressure mechanism ensures that when GPU memory is full, new requests wait rather than crash — exactly matching vLLM’s behavior under memory pressure.
You can find my entire code here: https://github.com/czhou578/multimodal-inference-visualizer/blob/main/nanogpt-paged-attention.ipynb
CZ
Adding Paged Attention to Andrej Karpathy’s NanoGPT (2026 edition) was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.

