NanoGPT is Andrej Karpathy’s from-scratch GPT trained on Shakespeare — no abstractions, no optimizations, just the bare-minimum transformer you need to generate text. I wanted to understand how inference servers actually work, so I started at the bottom: adding a KV cache to this toy model by hand.
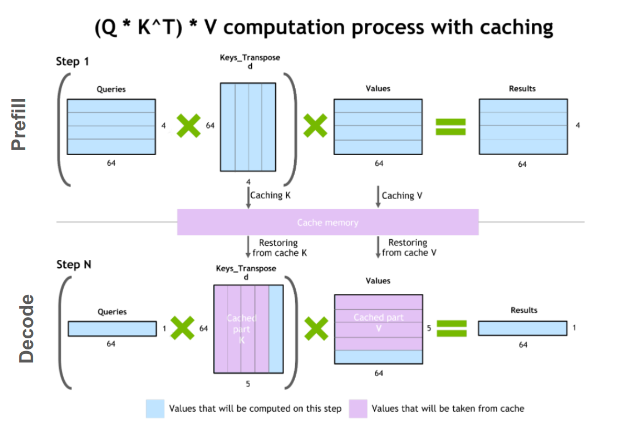
The core idea is simple. In a standard transformer, every time you generate a new token, you recompute the key and value projections for every token in the sequence — including all the ones you already processed. That’s quadratic in the sequence length. A KV cache stores the key and value vectors from previous positions so you never recompute them. The query for the new token attends over the cached keys and values, and you only compute K and V for the single new token. This brings the per-step cost from O(n) to O(1), and the total generation cost from O(n²) to O(n).
Where the cache lives
The natural place for the cache is inside the Head class — the module that handles one head of self-attention. Each head independently projects the input into query, key, and value vectors, so each head needs its own cache.
I had to think through several things:
• Data structure. My first instinct was a hashmap keyed by token ID, but that’s wrong — the cache isn’t about which token, it’s about which position. It’s just a tensor of shape (B, T, hs) that grows by one row each decode step as we concatenate new key/value vectors along the sequence dimension.
• Don’t interleave K and V. You might think about storing keys and values in one tensor, but the whole point of caching is fast access. During attention, you need Q @ K^T and then weights @ V — interleaving would force you to extract K and V back out every step, defeating the purpose.
• Masking goes away. In the original NanoGPT, the causal mask prevents the model from attending to future tokens during training. But during cached inference, we feed one token at a time. There are no future tokens to mask — the cache only contains past positions. So the mask can be removed entirely for the inference path.
• Training vs. inference. PyTorch’s nn.Module has a self.training flag that flips when you call model.eval(). We use this to guard the cache logic: during training, the original full-sequence attention runs unchanged; during inference, we accumulate into the cache and attend over it.
The final code:
class Head(nn.Module):
""" one head of self-attention """ def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.key_cache = None
self.value_cache = None
self.dropout = nn.Dropout(dropout) # KV Cache lives here.
def forward(self, x):
# input of size (batch, time-step, channels)
# output of size (batch, time-step, head size)
B,T,C = x.shape
k = self.key(x) # (B,1,hs)
q = self.query(x) # (B,1,hs)
v = self.value(x)
if not self.training:
if self.key_cache is not None:
self.key_cache = torch.cat([self.key_cache, k], dim=-2) # (B, num_tokens_seen, hs)
self.value_cache = torch.cat([self.value_cache, v], dim=-2) # (B, num_tokens_seen, hs)
else:
self.key_cache = k
self.value_cache = v
wei = q @ torch.transpose(self.key_cache, 1, 2) * self.key_cache.shape[-1]**-0.5
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
# perform the weighted aggregation of the values
out = wei @ self.value_cache # (B, 1, T) @ (B, T, hs) -> (B, 1, hs)
return out
else:
# compute attention scores ("affinities")
wei = q @ k.transpose(-2,-1) * k.shape[-1]**-0.5 # (B, T, hs) @ (B, hs, T) -> (B, T, T)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
# perform the weighted aggregation of the
out = wei @ v # (B, T, T) @ (B, T, hs) -> (B, T, hs)
return out
The inference branch is the interesting one. When a new token arrives, we project it to get k and v of shape (B, 1, hs) and concatenate them onto the existing cache. Now the cache has shape (B, T_so_far, hs). The query — also (B, 1, hs) — attends over the full cache: Q @ K^T gives (B, 1, T_so_far) attention weights, and the weighted sum over V gives (B, 1, hs). One row in, one row out. The training branch is unchanged — full-sequence attention with the causal mask, exactly as Karpathy wrote it.
The if self.key_cache is not None check handles the first step: when the cache is empty (the very first forward pass), we initialize it directly instead of trying to concatenate onto None.
Generation
With the cache in place, we need a generation function that actually uses it:
def generate_kv_cache(model, idx, max_num_tokens):
model.eval()
clear_kv_cache(model)
model(idx)
with torch.no_grad():
for step in range(max_num_tokens):
curr_pos = idx.shape[1]
logits, _ = model(idx[:, -1:], pos=torch.tensor[curr_pos], device=device) # (B, 1, C)
logits = logits[:, -1, :]
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
model = GPTLanguageModel()
m = model.to(device)
# print the number of parameters in the model
print(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')
# create a PyTorch optimizer
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
for iter in range(max_iters):
# every once in a while evaluate the loss on train and val sets
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss()
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
# generate from the model
context = torch.zeros((1, 1), dtype=torch.long, device=device)
print(decode(generate_kv_cache(m, context, max_num_tokens=500)[0].tolist()))
In this function, we are setting the model to evaluation mode, and making sure to clear the kv cache for the model.
Now, we run model(idx) once since that is how we prefill the KV cache before the next token is generated. Then, we have a for loop that iterates until the max number of new tokens we want, and grab the logits for the specific index, run softmax over the logits to get the probabilities, and then sample the next index. The index is added to the running sequence of indexes, which will then be decoded into the correct letters at the final step.
Positional encoding
There’s a subtlety here that tripped me up. A transformer has no inherent sense of order — “A cat is big” and “A big is cat” would produce the same embeddings without position information. NanoGPT uses a learned position embedding table: during the forward pass, the position index looks up a vector from the table, and that vector gets added to the token embedding.
During full-sequence training, this is straightforward: if the sequence has 17 tokens, you look up positions 0 through 16. But with the KV cache, we’re feeding one token at a time. If we don’t pass the correct position, the model treats every token as position 0.
The fix is simple: curr_pos = idx.shape[1], which is the current length of the full sequence (prompt + generated so far). Here's a concrete example:
Prompt: "O Romeo, " → encodes to 9 tokens: [15, 23, 6, 18, 14, 5, 12, 0, 3]
idx = [[15, 23, 6, 18, 14, 5, 12, 0, 3]] # shape (1, 9)
↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑
pos0 pos1 ... ... ... ... ... ... pos8
Step 0: width is 9 → model uses pos 9 → generates token 42 → append
idx = [[15, 23, 6, 18, 14, 5, 12, 0, 3, 42]] # shape (1, 10)
Step 1: width is 10 → model uses pos 10 → generates token 10 → append
idx = [[15, 23, 6, 18, 14, 5, 12, 0, 3, 42, 10]] # shape (1, 11)
Step 2: width is 11 → model uses pos 11 → generates token 19 → append
idx = [[15, 23, 6, 18, 14, 5, 12, 0, 3, 42, 10, 19]] # shape (1, 12)
idx.shape[1] always gives us exactly the right position index for the next token.
Verification
The most important check: if the KV cache is mathematically correct, it should produce the exact same tokens as the no-cache version given the same random seed and prompt. The cache is an optimization, not an approximation — it shouldn’t change the output at all.
torch.manual_seed(42)
context = torch.zeros((1, 1), dtype=torch.long, device=device)
# Run without cache
out_no_cache = generate_no_cache(model, context.clone(), max_new_tokens=20)
# Run with cache (same seed, same prompt)
torch.manual_seed(42)
out_with_cache = generate_with_cache(model, context.clone(), max_new_tokens=20)
# Check token-by-token equality
assert torch.equal(out_no_cache, out_with_cache), \
f"MISMATCH!\nNo cache: {out_no_cache}\nWith cache: {out_with_cache}"
print("✓ Cache output matches no-cache output exactly!")
print(decode(out_with_cache[0].tolist()))
This seeds the RNG, runs the same prompt through both paths, and asserts that every token matches. If even one differs, the cache logic has a bug.
Shape walkthrough
It helps to trace the dimensions through one full cycle to make sure everything fits:
Prefill (9-token prompt):
model.forward(idx) # idx: (1, 9)
tok_emb: (1, 9, 64) # token embedding lookup
pos_emb: (9, 64) # position embedding for positions 0..8
x: (1, 9, 64) # tok_emb + pos_emb (broadcast)
→ Head.forward(x):
k = self.key(x): (1, 9, 16) # Linear(64 → 16)
q = self.query(x): (1, 9, 16)
v = self.value(x): (1, 9, 16)
key_cache is None → set directly
key_cache: (1, 9, 16)
value_cache: (1, 9, 16)
wei = q @ key_cache.T: (1,9,16) @ (1,16,9) → (1, 9, 9)
out = wei @ value_cache: (1,9,9) @ (1,9,16) → (1, 9, 16)
Decode step 0 (one new token):
model.forward(idx[:, -1:], pos=9) # idx: (1, 1)
tok_emb: (1, 1, 64)
pos_emb: (1, 64) # position embedding for position 9
x: (1, 1, 64)
→ Head.forward(x):
k = self.key(x): (1, 1, 16)
q = self.query(x): (1, 1, 16)
v = self.value(x): (1, 1, 16)
key_cache: cat[(1,9,16), (1,1,16)] → (1, 10, 16)
value_cache: cat[(1,9,16), (1,1,16)] → (1, 10, 16)
wei = q @ key_cache.T: (1,1,16) @ (1,16,10) → (1, 1, 10)
out = wei @ value_cache: (1,1,10) @ (1,10,16) → (1, 1, 16)
During prefill, the query has 9 positions and attends over 9 cached positions — (1, 9, 9) attention weights. During decode, the query has 1 position and attends over 10 cached positions — (1, 1, 10). The cache grew by one row, and the computation stayed O(1) per token instead of recomputing everything.
Benchmarks
The real test: does this actually speed things up?
# ── non-cached generate (forces full-context recompute every step) ────────────
def generate_no_cache(model, idx, max_new_tokens):
"""Runs in train mode so the KV cache branch is never entered."""
model.train() # disables KV cache path
with torch.no_grad():
for _ in range(max_new_tokens):
idx_cond = idx[:, -block_size:]
logits, _ = model(idx_cond)
logits = logits[:, -1, :]
probs = torch.nn.functional.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
return idx
# ── cached generate (your existing path, one token fed at a time) ─────────────
def generate_with_cache(model, idx, max_new_tokens):
model.eval()
clear_kv_cache(model)
with torch.no_grad():
for _ in range(max_new_tokens):
# Feed only the LAST token so the cache does the rest of the work
logits, _ = model(idx[:, -1:]) # (B, 1, vocab_size)
logits = logits[:, -1, :]
probs = torch.nn.functional.softmax(logits, dim=-1)
idx_next = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, idx_next), dim=1)
return idx
# ── benchmark ─────────────────────────────────────────────────────────────────
N_TOKENS = 200
N_RUNS = 3 # average over multiple runs for stability
context = torch.zeros((1, 1), dtype=torch.long, device=device)
# warm-up (avoids cold-start CUDA overhead skewing results)
_ = generate_no_cache(model, context.clone(), 10)
clear_kv_cache(model)
_ = generate_with_cache(model, context.clone(), 10)
# --- No KV cache ---
times_no_cache = []
for _ in range(N_RUNS):
t0 = time.perf_counter()
generate_no_cache(model, context.clone(), N_TOKENS)
if device == 'cuda':
torch.cuda.synchronize()
times_no_cache.append(time.perf_counter() - t0)
# --- With KV cache ---
times_cache = []
for _ in range(N_RUNS):
t0 = time.perf_counter()
generate_with_cache(model, context.clone(), N_TOKENS)
if device == 'cuda':
torch.cuda.synchronize()
times_cache.append(time.perf_counter() - t0)
avg_no_cache = sum(times_no_cache) / N_RUNS
avg_cache = sum(times_cache) / N_RUNS
print(f"Tokens generated : {N_TOKENS}")
print(f"No KV cache : {avg_no_cache:.3f}s ({N_TOKENS/avg_no_cache:.1f} tok/s)")
print(f"With KV cache : {avg_cache:.3f}s ({N_TOKENS/avg_cache:.1f} tok/s)")
print(f"Speedup : {avg_no_cache/avg_cache:.2f}×")
In this block of code, we first define the no-cache and cache versions of the generate function. The no-cache version is the original generate function, which is used to generate text from the model. The cache version is the same as the no-cache version, but it uses the KV cache to generate text from the model.
Then, we define the benchmark function, which is used to benchmark the no-cache and cache versions of the generate function. The benchmark function first generates text from the model using the no-cache version, and then from the model using the cache version. Finally, it prints the speedup of the cache version over the no-cache version.
Running this code, we get:
Tokens generated : 200
No KV cache : 1.305s (153.3 tok/s)
With KV cache : 1.172s (170.7 tok/s)
Speedup : 1.11×
Only 1.11×. That’s real but underwhelming. The reason: this model is tiny — 0.2M parameters, 4 layers, 4 heads. At this scale, the Python interpreter overhead (function calls, tensor creation, torch.cat) dominates the actual matrix multiplications. The KV cache saves recomputation that barely costs anything in the first place. On larger models with longer sequences, the quadratic savings become dramatic — this is why production systems treat the KV cache as essential infrastructure, not an optimization.
Output
The model generates Shakespeare-flavored gibberish, which is exactly what we expect from a character-level model trained on a small corpus:
And they brid write, is not the die;
Though we art One my day hangs:
Wart he us hath bury, dills ane away, my feanst,
Anzing heavens, tofultien me milen's
Whines is eye, hain latise, drovets, and Will.
Downerabs!
Alhin the courtius, onceivy:
Supplain's twoy. Hence's norfole,
Against my lows thee again Willo when evicks eye myself?
ETo husing stroops: the resheper my brupt for treign the flows.
Tale oftenceful in thy offery your
Hasting is a aday Was happesty:
if courty.
ANGCIO:
Say, from care,
Things that went wrong
Estimate loss frequency. I was running the loss estimation loop every 100 steps, which was destroying throughput on the free Colab GPU. Changing it to every 500 steps made training workable.
torch.compile and mutable state. I tried torch.compile(model) to speed things up, but it doesn't play well with the KV cache. Torch compile traces the computation graph and replays it — but the cache is mutable state that changes shape every step. The traced graph expects fixed shapes and corrupts the output. Production systems solve this with pre-allocated caches and padding, but for a toy implementation it's easier to just skip compile.
Validation loss not decreasing. At one point my validation loss was flat. The cause was surprising: I was calling model.train() and model.eval() in the estimation loop, but since I wasn't using dropout, there was no behavioral difference between the two modes — except that model.eval() was activating the KV cache path, which was corrupting the loss computation. Removing those calls from the estimation function fixed it.
CUDA device-side assert. After training, generation crashed with CUDA error: device-side assert triggered. The position embedding table had only 32 entries (block_size = 32), so generating 500 tokens tried to look up position 500 in a table that only goes to 31. The fix: cap max_new_tokens so that prompt_length + max_new_tokens ≤ block_size.
This is a real limitation worth calling out. With a fixed-size learned position embedding table, you can never generate more than block_size total tokens. Production models solve this with RoPE (Rotary Positional Embeddings), which computes position information on the fly instead of looking it up in a table, removing the sequence length cap entirely.
You can see the entire code on my GitHub: https://github.com/czhou578/multimodal-inference-visualizer/blob/main/nanogpt.ipynb
CZ
Adding KV Cache to Andrej Karpathy’s NanoGPT (2026 edition) was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.