Why boolean flags can’t solve event-ordering bugs, and the Deferred Dispatch pattern that does.
Canonical URL: https://note.com/yamashita_aidev/n/nb71fd035a6cd (English adaptation of the original Japanese post.)
“I Said ‘Repeat’ and It Sent a New Question”
That’s what a field tester told me, fresh off the floor. I knew the cause before I opened the logs. Timing. The only question was how much.
I lined up the timestamps from Logcat:
14:50:03.886 SpeechDetector: end-of-speech detected
14:50:03.887 VoiceAssistantService: handleSpeechComplete() → WAV sent to server
14:50:03.888 VoiceAssistantService: state LISTENING_FOLLOWUP → PROCESSING ("send")
14:50:04.230 VoskEngine: final result {"text": "repeat"} ← 344ms late
14:50:06.800 Server response: "Repeat." ← server treated "repeat" as a new question
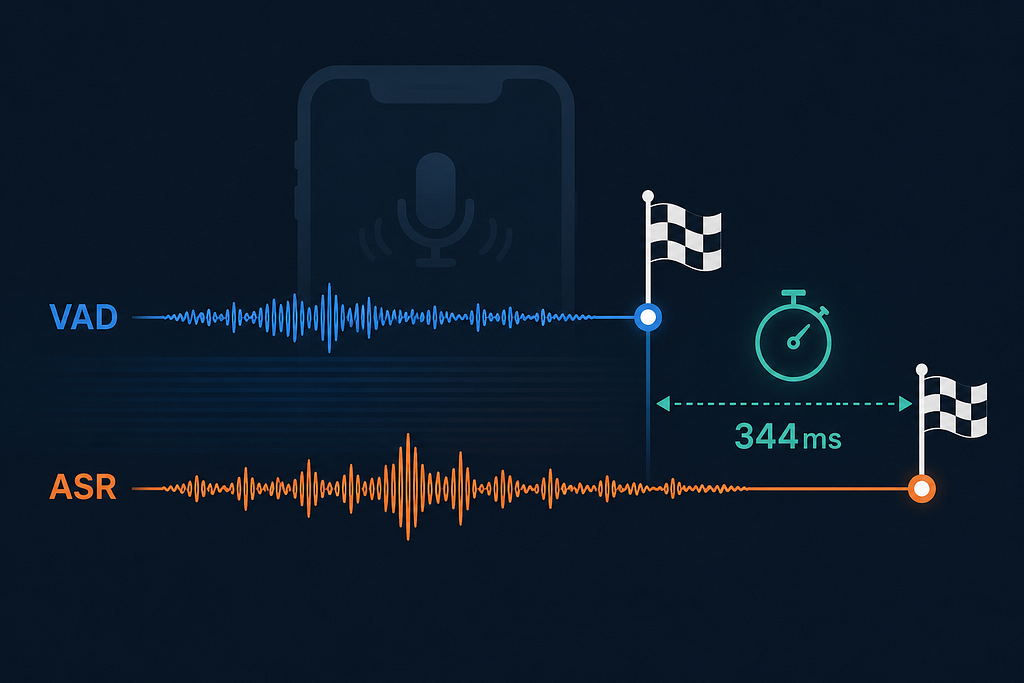
The Voice Activity Detector fired its “speech ended” event 344ms before the speech recognizer (Vosk) finished decoding. By the time the recognizer figured out the user said “repeat,” the audio had already been packaged up and sent to the LLM as a new question. The server, having no context, dutifully answered “Repeat.”
I wanted to fix it with a 1-line flag. It took three architectures and a name from a paper I hadn’t read yet: Deferred Dispatch.
TL;DR
- The bug: Two async audio components — VAD and ASR — fire their “done” events out of order. VAD wins by ~344ms. Whatever decision the system makes between those two events is wrong.
- The wrong fix #1: Boolean flag. Doesn’t work because the flag gets set after the decision point — the timing is the bug.
- The wrong fix #2: Block the audio thread until ASR finishes. Doesn’t work because blocking the audio callback drops microphone data.
- The right fix: Defer the decision. Hold the WAV in a slot. Set a 400ms timer. If ASR returns first, run that path and discard the WAV. If the timer fires first, send the WAV as a new question.
- Three cleanup sites required. Miss one and you’ll get phantom timer fires that corrupt state in unrelated flows.
- Result: Zero false sends in field testing. ~400ms worst-case extra latency, imperceptible in conversation.
Why VAD and ASR Don’t Agree on When Speech Ended
This is a trap that any pipeline composing two ML audio components will hit. Briefly:
- VAD (Silero, in our case) declares end-of-speech after ~480ms of silence (15 frames × 32ms). It’s voting based purely on signal energy / classifier output. Once it decides, the WAV is ready.
- ASR (Vosk, in our case) finalizes by running an audio chunk through an acoustic model + decoder + post-processing pipeline. Internal latency: 200–350ms in our measurements. Plus thread-handoff latency (Vosk runs on its own HandlerThread, results come back via main-thread post): another ~tens of ms.
Net: the ASR’s final result lands 250–400ms after the VAD’s “done” event.
If your downstream logic asks “was this audio a command, or a question?” — and that decision happens at the moment VAD fires — you have a race. Vosk hasn’t decided yet.
This generalizes. Any time you have:
- A fast cheap detector (VAD, wake-word, energy gate)
- A slower deep recognizer (ASR, intent classifier, LLM)
- And a routing decision that needs both opinions
…you’ve got the same race condition. The shapes of the bug are remarkably consistent across audio frameworks.
Wrong Fix #1: The Boolean Flag
My first reaction was the optimistic engineer’s reaction. “Just set a flag when Vosk recognizes a command, and check it in handleSpeechComplete." One hour. Done.
// First attempt — does not work
var commandRecognizedDuringFollowup = false
fun handleSpeechComplete(wavData: ByteArray) {
if (commandRecognizedDuringFollowup) {
commandRecognizedDuringFollowup = false
return // Discard WAV; let the command path handle it
}
// The bug: we always reach here before Vosk's callback runs.
sendToServer(wavData)
}fun onCommandDetected(command: VoskCommand) {
if (pipelineState == LISTENING_FOLLOWUP) {
commandRecognizedDuringFollowup = true // Always set 344ms TOO LATE
}
}It changed nothing. The timing was the bug, and a flag-based check only works if the flag arrives before the check runs. Here it never does.
The lesson is harder than “flags are fragile.” Race conditions where one event reliably arrives later than another aren’t fixable by a boolean, period. The flag setter is structurally too late. You can prove this by drawing the timeline:
t=0ms: VAD fires → handleSpeechComplete() runs → flag = false → send WAV
t=344ms: Vosk fires → flag = true (no one is reading anymore)
The flag never observes the true state from the consumer's perspective.
Wrong Fix #2: Block the Audio Thread
Next attempt: use CountDownLatch inside handleSpeechComplete() to wait up to 500ms for Vosk's result before deciding.
fun handleSpeechComplete(wavData: ByteArray) {
val latch = CountDownLatch(1)
voskCallbackLatch = latch
val gotResult = latch.await(500, TimeUnit.MILLISECONDS)
// ... decide based on gotResult
}This compiles. It even runs. It also drops audio.
handleSpeechComplete() is called from the audio capture thread. While it blocks, the microphone buffer doesn't get serviced. Frames get dropped. Subsequent recognition quality tanks because we're now feeding the recognizer audio with gaps.
I heard it in playback — the test recording sounded chopped, like a bad cellular call. Blocking the audio thread to solve a routing decision is a category mistake. The audio thread has exactly one job: keep the mic alive.
The Right Fix: Defer the Decision
The breakthrough came while diagnosing the latch failure. Both wrong fixes assumed I had to decide now. I didn’t. I needed to decide later, when I have enough information.
The pattern:
- WAV arrives → don’t send it. Hold it in a slot.
- Schedule a deadline (e.g., 400ms) on the main thread.
- Race between two events:
- Vosk fires a command → cancel the deadline, run the command path, discard the WAV.
- Deadline fires → send the WAV as a new question, clear the slot.
- Whichever wins, the loser is canceled.
fun handleSpeechComplete(wavData: ByteArray) {
if (pipelineState != LISTENING_FOLLOWUP) {
sendToServer(wavData) // Outside follow-up, send immediately
return
}// Deferred Dispatch: hold the WAV, decide in 400ms.
pendingFollowupWavData = wavData
val decisionRunnable = Runnable {
// Deadline reached — Vosk didn't get a command in time.
val wav = pendingFollowupWavData ?: return@Runnable
pendingFollowupWavData = null
followupDecisionRunnable = null
transitionToProcessing()
sendToServer(wav)
}
followupDecisionRunnable = decisionRunnable
mainHandler.postDelayed(decisionRunnable, FOLLOWUP_VOSK_DEADLINE_MS)
}fun onCommandDetected(command: VoskCommand) {
if (pipelineState == LISTENING_FOLLOWUP && pendingFollowupWavData != null) {
// Vosk won the race. Cancel the deadline, discard the WAV.
followupDecisionRunnable?.let { mainHandler.removeCallbacks(it) }
followupDecisionRunnable = null
pendingFollowupWavData = null
executeFollowupCommand(command) // "repeat" or "next"
}
}The audio thread does not block. The decision is made on the main thread, with full information about which event arrived first. Both paths (Vosk wins vs. deadline wins) write to the same set of state fields, so the cleanup is symmetric.
I learned later that this pattern has a name in distributed systems literature: Deferred Dispatch. I’d reinvented it from first principles.
Why 400ms
The deadline is a calibrated number, not a guess.
ComponentMeasuredVAD silence detection (15 frames × 32ms)~480msVosk internal pipeline200–350msmainHandler.post() queue latency~tens of msTotal: VAD-fire → Vosk-result-arrival250–400ms
400ms covers the upper end of the distribution with a small margin. Shorter, and you’ll lose Vosk results that were almost in time. Longer, and a real new question waits noticeably long before being sent (the user starts to wonder if the system froze).
400ms is the minimum deadline that empirically catches all of Vosk’s results in our environment. On a different device or model, you’d recalibrate.
Approach Comparison
ApproachMechanismWhy it fails (or works)Boolean flagSet flag on Vosk result, check in handleSpeechCompleteFlag set is structurally too late (344ms after the check)Block audio threadCountDownLatch waits in handleSpeechCompleteAudio thread blocked → mic buffer drops → recognition degradesDeferred DispatchHold WAV in slot, deadline-vs-Vosk race on main threadWorst-case +400ms latency, no thread blocking, deterministic behavior
The Cleanup Trap: Why Three Sites?
Easiest part of the fix to underestimate, hardest part to get right.
followupDecisionRunnable is a posted Runnable on mainHandler. If it survives a state transition, it'll fire later in an unrelated context — usually with pendingFollowupWavData already nulled (no-op, harmless) or, worse, freshly populated by the next utterance (sends the new utterance with the old utterance's logic).
I cancel the runnable in three places:
private fun cancelPendingFollowupDecision() {
followupDecisionRunnable?.let { mainHandler.removeCallbacks(it) }
followupDecisionRunnable = null
pendingFollowupWavData = null
}// Site 1: returning to wake-word listening
fun returnToWakeWord() {
cancelPendingFollowupDecision()
pipelineState = LISTENING_WAKEWORD
}
// Site 2: re-entering follow-up after a new response
fun enterFollowupMode() {
cancelPendingFollowupDecision() // Clean slate
pipelineState = LISTENING_FOLLOWUP
}
// Site 3: Service tearing down
override fun onDestroy() {
cancelPendingFollowupDecision() // Critical — mainHandler may outlive the Service
super.onDestroy()
}
The onDestroy site is the one I'd have missed without thinking carefully. Android Services don't always destroy their mainHandler on shutdown — bound to the application context, the handler can outlive the Service that posted to it. A leaked Runnable keeps a reference back to your Service, leaks memory, and fires in unrelated contexts later. I never reproduced the failure, but it would have been miserable to debug if I had.
The general rule: any deferred work needs explicit cancellation at every state transition where the deferred decision is no longer valid. Miss one and you have a Heisenbug.
Results
- “Repeat” false-sends: ~1 in 5 attempts → zero in 50 retest trials
- “Next” false-sends: a handful per session → zero
- New-question worst-case latency increase: +400ms (subjectively imperceptible — confirmed by field testers)
The field tester’s response after the fix: “It just works now.”
Where This Pattern Travels
Anywhere two async components disagree on event ordering and you need both opinions before routing:
- Voice pipelines: VAD + ASR is the canonical case. Same pattern works for wake-word + command-recognizer, or push-to-talk button + transcription.
- Sensor fusion: GPS fix arrives milliseconds before IMU correction. Decisions that need both should buffer briefly.
- Multi-modal LLM input: image classifier returns before text classifier. If the routing decision needs both, defer.
- UI input + server validation: user clicks “submit” but the server hasn’t validated the form yet. Defer the actual submission, race validation against a timeout.
The general shape: “if you’re tempted to use a flag to coordinate two events that fire in undefined order, you almost always want to defer the decision instead.” Flags assume both events have happened by the time you check. Deferred Dispatch makes the order explicit and lets the runtime pick.
A few specific tips that travel:
- Calibrate the deadline empirically. Don’t pick a round number. Measure your actual distribution and pick the upper end.
- Cancel deferred work at every exit transition. Every one. The Service-destroy case will bite you eventually.
- Don’t block the latency-critical thread. Blocking the audio thread, the UI thread, or the network event loop to wait for “the other component” is always a category error. Defer instead.
- Name the pattern in code. A function called cancelPendingFollowupDecision() reads better than three inline nullifications. Future-you, when this fires once a year in production, will be grateful.
Closing
I’m a solo developer building hands-free voice AI for eldercare workers — real care staff in real facilities, where “I said ‘repeat’ and it sent a new question” is a trust-killer the second time it happens. Two ML components disagreeing on event order isn’t an exotic bug. It’s the default when you compose async pipelines.
The 344ms gap between VAD and ASR was specific to my hardware and model choice. The pattern of “fast cheap signal arriving 200–400ms before slow accurate signal” is universal. Wherever you compose detection + recognition + routing, plan for the race from day one. Deferred Dispatch costs you a small worst-case latency. Flags cost you weeks of irreproducible bug reports.
If you’re building voice AI, multi-modal input pipelines, or anything with async event composition, follow me. I write Field Notes from voice-AI-for-eldercare in Japan, where shift-floor reality recalibrates every textbook value. Earlier in the series: The AsyncAnthropic Footgun Claude Code Caught Before I Wrote a Line of Code and “Bedsore” Was the Word That Broke Our Vector Search.
A 344ms Race Condition Between Two Audio Components Almost Killed My Voice AI’s “Repeat” Command was originally published in Level Up Coding on Medium, where people are continuing the conversation by highlighting and responding to this story.